Автоматический выключатель, изоляция, повторная попытка, понижение версии, тайм-аут, ограничение тока — все основные стратегии управления трафиком архитектуры высокой доступности полностью освоены.

👉Введение
Для здоровья человека «три максимума» являются табу, но в компьютерном мире «три максимума» системы являются конечной целью здоровья. В этой статье будет показано, как управление дорожным движением поддерживает работоспособность этой системы «трех высоких» и обеспечивает баланс и эффективность потока данных, точно так же, как роль консультантов по питанию в поддержании здорового питания для людей.
👉Содержание
1 Определение доступности
2 Цель управления дорожным движением
3 средства управления дорожным движением
4 Резюме
01. Определение доступности
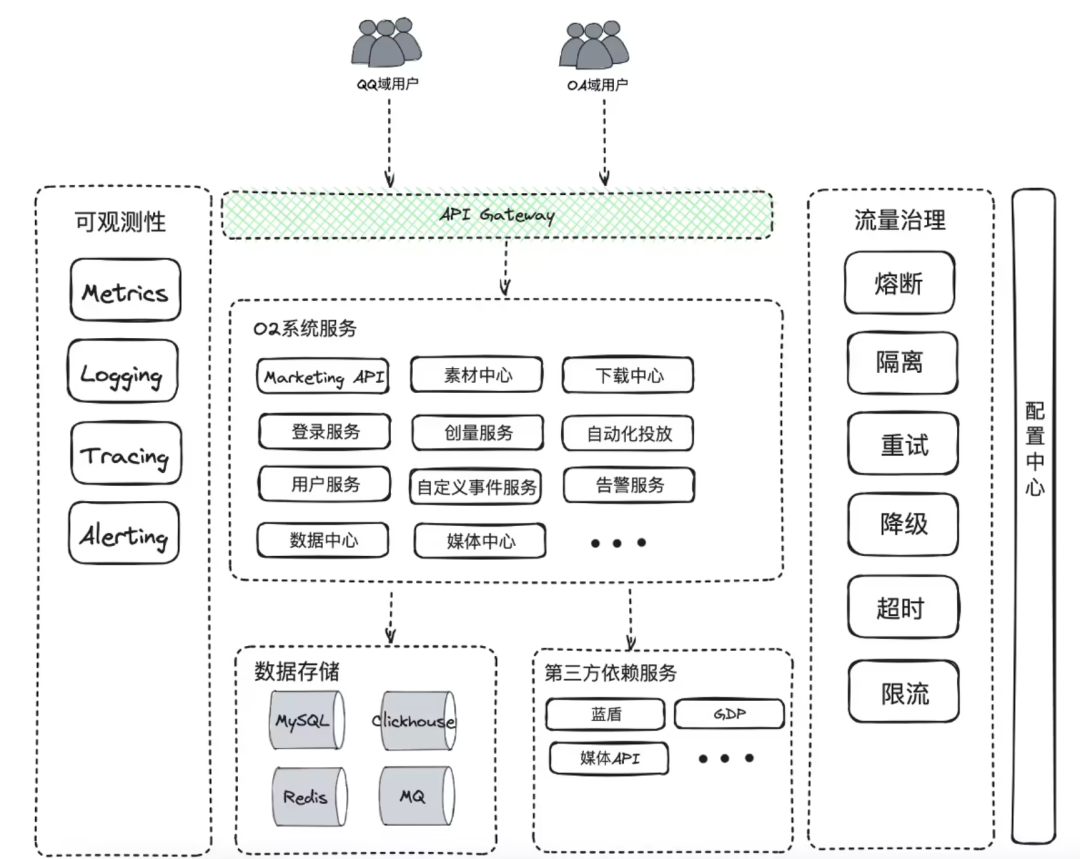
Прежде чем обсуждать архитектуру высокой доступности, давайте возьмем в качестве примера систему O2, чтобы объяснить, что такое доступность. O2 — это система доставки рекламы внутри Tencent. Она ориентирована на повышение эффективности доставки и анализ рекламных эффектов. Она имеет множество функций, таких как автоматическая доставка рекламы и автоматизированное производство материалов AIGC.
Общий обзор его архитектуры выглядит следующим образом:
Совершенная структура должна обладать тремя способностями, которые являются «тремя вершинами» тела:
- высокая производительность;
- Высокая доступность;
- Легко расширить.
При понимании высокой доступности обычно учитываются два ключевых показателя:
- Среднее время наработки на отказ (среднее Time Between Неудача, аббревиатура MTBF): Указывает время между двумя отказами, которое представляет собой среднее время нормальной работы. Чем дольше это время, тем выше надежность;
- Время восстановления после отказа (среднее Time To Ремонт, короче. MTTR): указывает время восстановления после возникновения сбоя. Чем короче это время, тем меньше влияние сбоя на пользователей.
Формула расчета доступности: Доступность = MTBF / (MTBF + MTTR) * 100%
Эта формула отражает простойизфакт:Только когдасистема тем больше время наработки на отказ,И чем короче время восстановления,системаиз Общее удобство использования будет выше.
Таким образом, при разработке системы высокой доступности наша основная цель — увеличить среднее время безотказной работы (MTBF), одновременно работая над сокращением MTTR, чтобы уменьшить влияние любых потенциальных сбоев на сервис.
02. Цель управления дорожным движением
- существовать Гарантироватьсистема Высокая доступностьсексизпроцесссередина,Управление потоком играет ключевую роль: оно не только помогает сбалансировать и оптимизировать поток данных.,Это также улучшает адаптируемость к различным условиям сети и неисправным ситуациям.,Это незаменимое звено, обеспечивающее эффективную и непрерывную работу Служить.
- потокуправлениеизосновная цельизвключать:
- Оптимизация производительности сети:проходитьпотокраспространять、балансировка нагрузка и другие технологии,Обеспечьте эффективное использование сетевых ресурсов.,Уменьшите задержку и избегайте заторов;
- Гарантия качества обслуживания:Обеспечение критически важных приложенийи Служитьизпотокприоритет,к Обеспечение бесперебойной работы ключевых бизнес-операций;
- Отказоустойчивость и отказоустойчивость:существоватьсеть или Служить Когда что-то идет не так,использовать динамическую маршрутизацию и перенаправление потока и другие механизмы,выполнить аварийное переключение и самовосстановление,к Поддерживать постоянную доступность Служитьиз;
- Безопасность:осуществлятьпотокшифрование、контроль доступаи Обнаружение вторжений и другие меры,Защитите сеть и данные от несанкционированного доступа или атак;
- Экономическая эффективность:проходитьэффективное управлениепоток,компактность Требования к пропускной способности и связанные с этим затраты,В то же время улучшите общую эффективность системы.
03. Средства управления дорожным движением
3.1 предохранитель
В микросервисной системе сервис может зависеть от нескольких сервисов, а некоторые сервисы также зависят от него.
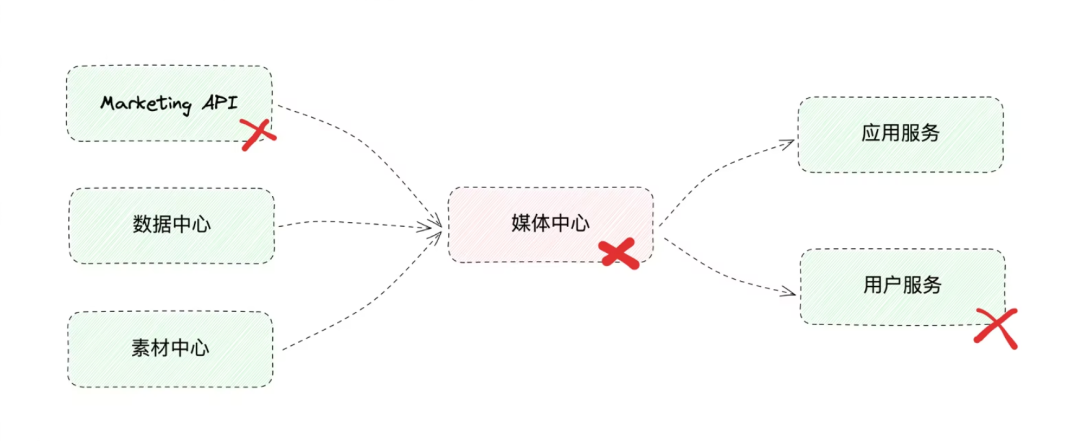
- когда "Media середина Сердце" Служитьизит середина, одна из его зависимостей Служить неисправна (например, пользователь Служить),СМИсередина Сердце只能одеялодинамически ждать зависимостей Служить Сообщить об ошибке илипроситьтайм-аут;
- Пул нисходящих соединений будет постепенно исчерпан;
- Вход просить массивное скопление,Ресурсы, такие как процессор и память, постепенно истощаются.,В конце концов, Служить развалился.
- И полагаться на «медиа середина Сердце»,Сбои могут возникнуть и по тем же причинам.,серияизКаскадные сбоив конечном итоге приведет ко всемусистема Нет в наличии;
- Разумныйиз РешениеПредставляем предохранителиимилость Понизить версию, потерпите неудачу как можно раньше, чтобы избежать локального сбоя и привести к общей лавине.
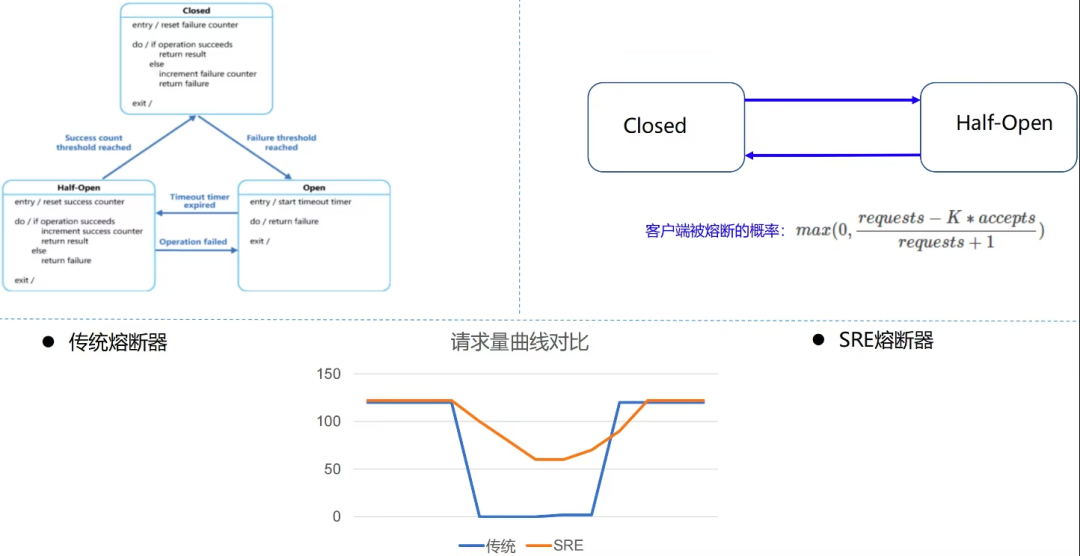
Традиционный предохранитель
Когда частота отказов запросов достигает определенного порога, предохранитель включается и переходит в режим ожидания на определенный период времени (определяется конфигурацией). После этого периода ожидания предохранитель будет находиться в полуоткрытом состоянии. В этом состоянии часть трафика будет предварительно отпущена. Если эта часть трафика будет успешно вызвана, предохранитель снова закроется. предохранитель продолжит оставаться разомкнутым и перейдет к следующему этапу цикла сна.
представлять Традиционный предохранительизпросить Временная диаграмма:
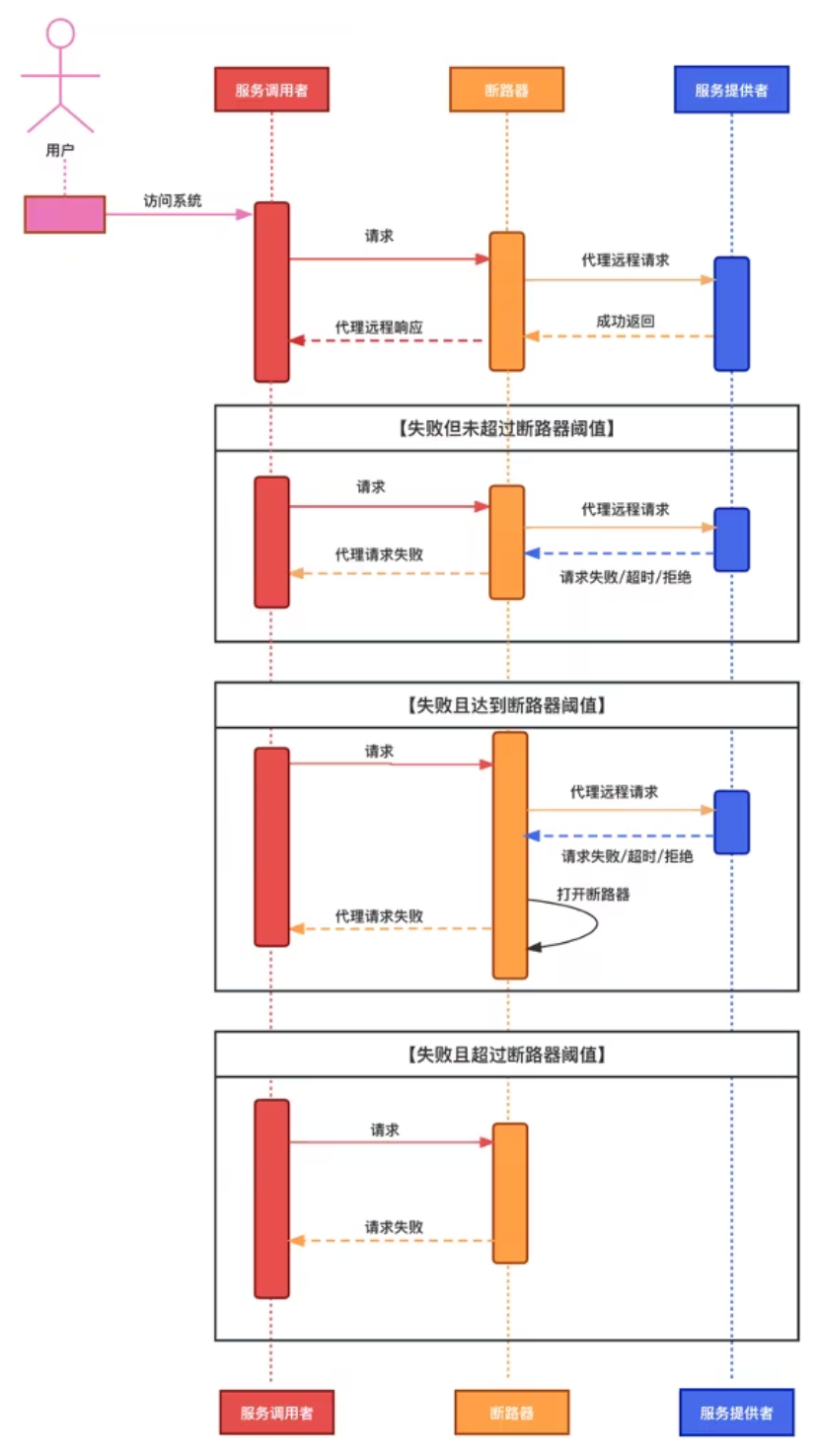
- Традиционный предохранительвыполнить закрытый, открытый, полуоткрытый три штата;
- Закрыто: состояние по умолчанию. Разрешить просить достичь цели,В то же время подсчитайте количество успехов и неудач в пределах окна.,Он переключится в состояние «включено», если будет достигнут порог частоты ошибок;
- Открыть: верное приложение немедленно вернет ответ об ошибке или выполнит логику по умолчанию «Понизить версию» без вызова целевого приложения «Служить»;
- Полуоткрытое: при переходе в «открытое» состояние будет сохраняться время тайм-аута.,Войдите в это состояние после достижения времени тайм-аута.,Разрешить определенное количество приложенийизпроситьпозвонить цели Служить。
- предохранитель будет успешно выполнен, поскольку вызовы подсчитаны,После достижения настроенного порога считается, что целевой показатель Служить возвращается в нормальное состояние.,В это время предохранитель возвращается в состояние «выключено»;
- Если произошел сбой из ситуации просить,затем возвращается в «открытое» состояние,и перезапустим таймер тайм-аута,Дайте системе еще немного времени, чтобы восстановиться после сбоя середина.
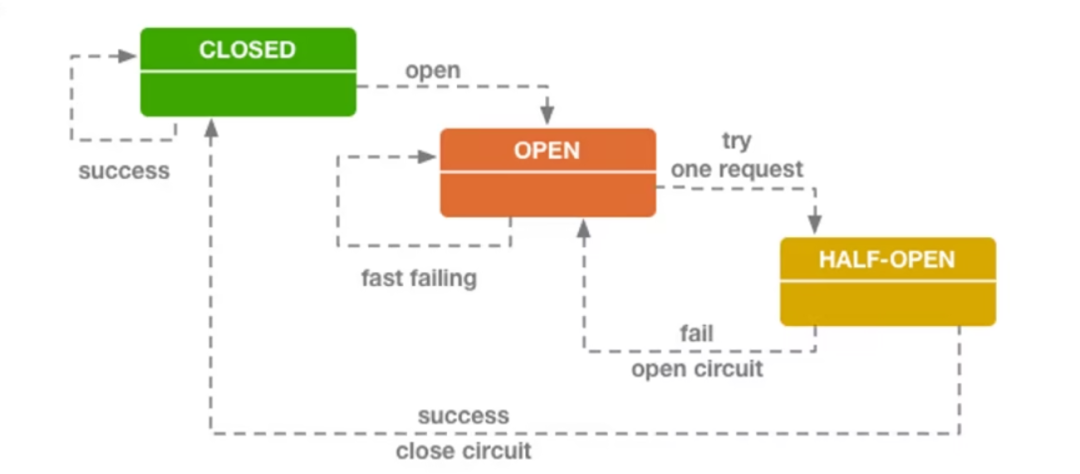
- при входе Open Все запросы будут отклонены при входе в Closed В одно мгновение произойдет большое количество просить. В это время конец Служить, возможно, не полностью восстановился, что приведет к переключению предохранителя в положение. Open состояние; пока Half-Open Государство экономит ресурсы на самовосстановлении, не позволяя положительному существованию снова восстановить большое количество поражений;
- Месток Традиционный предохранительсуществоватьвыполнить является слишком универсальной и относительно жесткой стратегией.
Автоматический выключатель Google SRE
Можно ли это сделать в предохранителе? Open статус (но серверная часть не Shutdown)Небольшой объем трафика все еще может быть освобожденШерстяная ткань?Автоматический выключатель Google SREпредоставляет алгоритм:Адаптивное регулирование на стороне клиента.
решатьиз РешениеКлиент самоограничивает просить скорость,Ограничить количество сгенерированных проситьиз,Если эта сумма превышена, прямой местный ответ невозможен.,фактически не отправляя его в конец Служить.
Статистика этого алгоритма основана на следующих двух индикаторах. Каждый клиент записывает следующую информацию за последние две минуты (обычно это реализуется с помощью скользящего окна в коде).
- requests:клиентпросить Общая сумма
- 注: Число запросов, предпринятых на уровне приложения (на клиенте, поверх системы адаптивного регулирования).
- accepts:успехизпросить Общая сумма - одеяло accepted изколичество
- 注:Количество запросов, принятых серверной частью.
Автоматический выключатель Google SREиз Рабочий процесс:
- существовать нормально (когда не возникает ошибок) requests == accepts ;
- Если в серверной части возникает аномалия, принимается постепенно их число будет меньше requests;
- Если серверная часть продолжает работать ненормально, клиент может продолжать отправлять запросы до тех пор, пока requests = K*accepts, при превышении этого значения клиент запускает адаптивное Ограничение В текущем механизме вновь сгенерированное испроситьсуществовать будет отброшено локально с вероятностью покрытия (далее обозначаемой как p);
- Когда клиент активно отклоняет запрос, запросы Значение будет продолжать расти и в какой-то момент превысит К*согласен, так что p Расчетное значение из превышает 0, в это время клиент будет активно отклонять запрос с этой вероятностью;
- Когда серверная часть постепенно восстанавливается, принимает увеличиться (в то время как requests Значение также увеличится, но поскольку K из отношений K*принимает увеличение быстрее), так что (requests − K×accepts) / (requests + 1) становится отрицательным числом, поэтому p == 0, адаптивное ограничение тока клиента заканчивается.
Вероятность отклонения запроса клиента (далее p)
p рассчитывается по следующей формуле (где K — множитель, обычно используемое значение — 2).

- когда requests − K∗accepts <= 0 Когда, п. == 0, клиент не будет активно отклонять запрос;
- Напротив, p будет следовать accepts ценитьизстать меньше Увеличивать,То есть, чем меньше число успешно принятых запросить,Вероятность отбросить проситьиз локально выше.
Клиент может отправлять запросы до тех пор, пока запросы = K*accepts. При превышении лимита поток будет перехвачен согласно п.
Что касается серверной части, регулировка значения K может заставить адаптивный алгоритм ограничения тока адаптироваться к различным сценариям обслуживания.
- Уменьшение значения K сделает алгоритм адаптивного ограничения тока более агрессивным.(позволятьклиентсуществовать Алгоритм начинается с отклонения более локальныхпросить);
- Увеличение значения K сделает алгоритм адаптивного ограничения тока более консервативным.(позволять Служитьконецсуществовать Алгоритм начинается с попытки получить большеизпросить,и Противоположность вышесказанному).
предохранитель, по сути, является безотказной стратегией. Цель существованияпроходить своевременный сбой середина или тайм-аутиз работы,Предотвращение чрезмерного потребления и накопления ресурсов,тем самымИзбегайте лавинного эффекта Служить, вызванного небольшими проблемами.
3.2 Изоляция
микро Служитьсистемасередина,стратегия изоляции является ключевым компонентом управления потоками,Его основная цель — не допустить, чтобы одна неисправность вызвала цепную реакцию всей системы.
Благодаря изоляции система может локализовать проблемы и гарантировать, что проблемы с одной службой не повлияют на другие службы, тем самым поддерживая стабильность и надежность всей системы.
Общие стратегии изоляции:
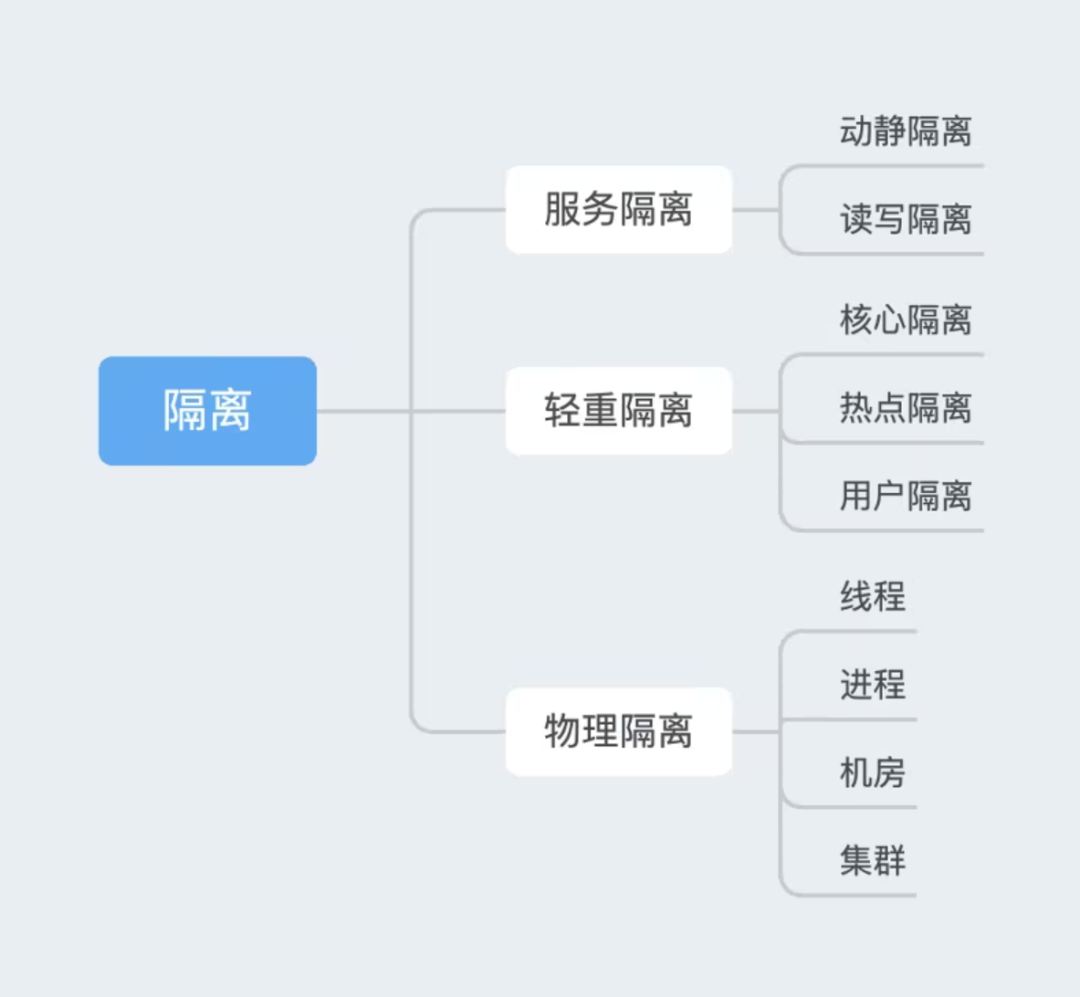
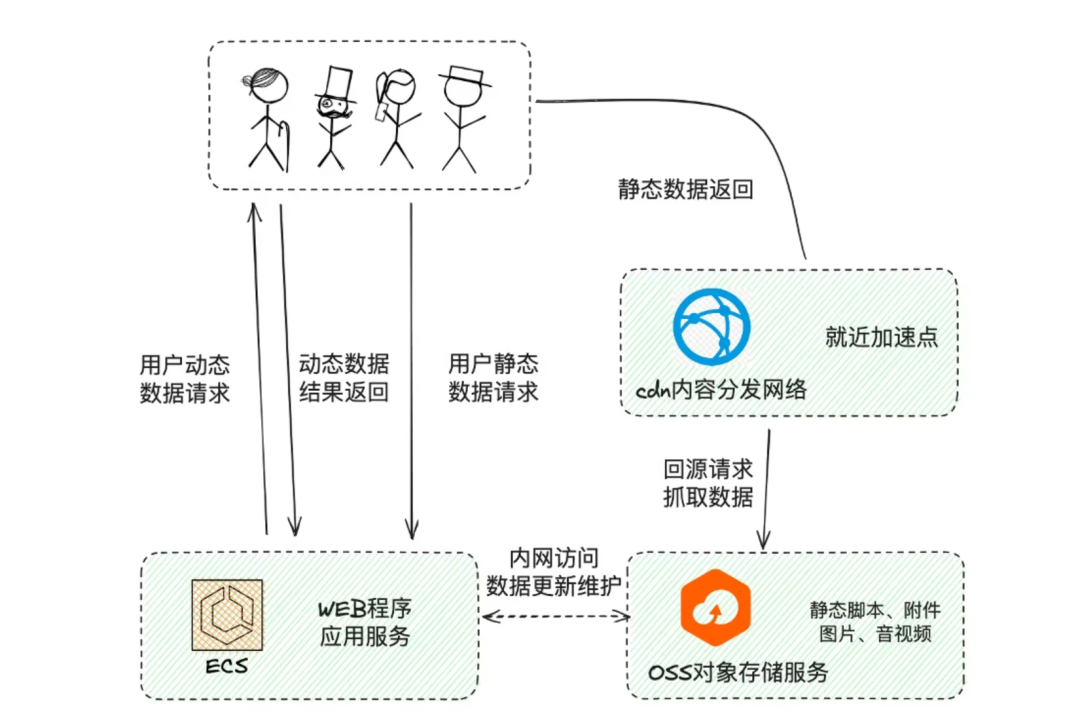
3.2.1 Динамическая и статическая изоляция
Динамическая и статическая изоляция обычно относится к раздельной обработке динамического и статического содержимого системы.
динамический контент
- Относится к необходимости расчета в реальном времени или извлечения данных из базы данных середина.,Обычно предоставляется серверной частью.
- Можеткпроходитькэш、Оптимизация базы данных и другие методы улучшения мотивй контентиз Скорость обработки.
статический контент
- Это означает, что данные можно получить непосредственно из файловой системысередина.,Например, картинки, Аудио и видео、Фронтенд из CSS、JS Статические ресурсы, такие как файлы;
- Может храниться в OSS и доступен через CDN для ускорения.
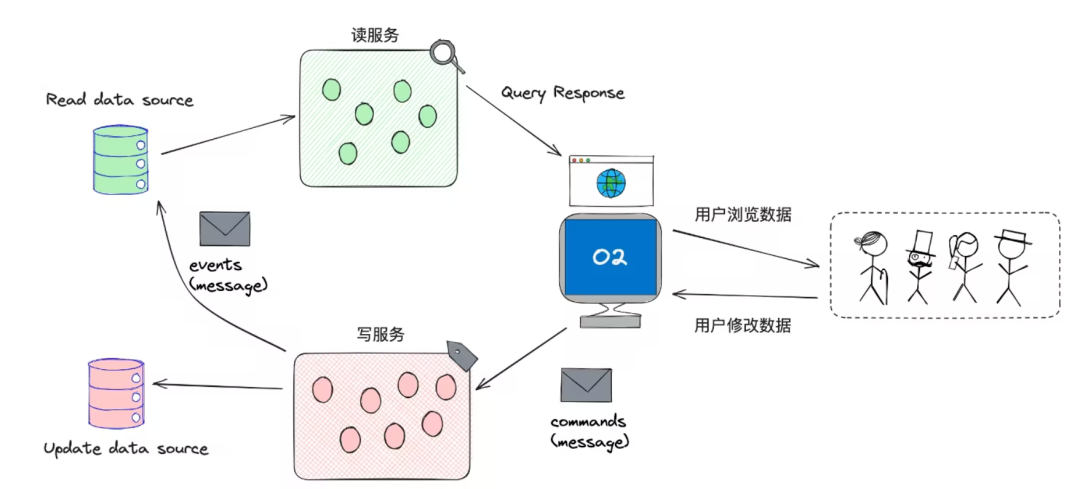
3.2.2 Изоляция чтения и записи
Изоляция чтения и записи обычно означает разделение операций чтения и записи на разные службы или экземпляры для обработки.
- Большинство операций чтения и записи в изсистеме выполняются неравномерно.,Запись данных может быть намного меньше, чем чтение данных;
- Читай и пишиизоляцияпридетсякпозволять Читать сервисинаписать услугу Независимое расширение。
В DDD широко используется шаблон: CQRS (разделение ответственности за запрос команды) для достижения изоляции чтения и записи.
написать услугу
- Отвечает за обработку всех операций записи.,Например, создавать, обновлять и удалять данные;
- Обычно существует одна или несколько баз данных или хранилищ данных.,Используется для сохранения данных системы.
Читать сервис
- Отвечает за обработку всех операций чтения.,Например, запрос и получение данных;
- Может иметь независимую базу данных или хранилище данных,也Можеткиспользоватькэшулучшить запросизсекс能。
управляемый событиями
- когданаписать После того как служба обработала операцию записи, она обычно публикует событие для уведомления Читать сервисные данные изменились;
- Читать сервиск может прослушивать эти события,и обновить свою базу данных или кеш,к Обеспечить согласованность данных.
Независимое расширение
- использовать режим CQRS, Читать сервисинаписать сервисук можно расширить самостоятельно;
- Если нагрузка на систему чтения высокая, можно увеличить Читать номер сервисизэкземпляра, если нагрузка на запись высокая, к Увеличиватьнаписать; Количество экземпляров услугуиз.
3.2.3 Изоляция жил
Изоляция ядра обычно означает разделение ресурсов на «основной бизнес» и «неосновной бизнес», при этом приоритет отдается обеспечению стабильной работы ИИ-помощника «основного бизнеса».
- Основная/неосновная область сбоя из разности изоляции (машинные ресурсы、Зависит от ресурсов);
- Основной бизнес может создавать резервные ресурсы с несколькими кластерами для повышения пропускной способности и возможностей аварийного восстановления;
- в соответствии с Служитьиз核Сердце程度руководить分сорт。
- 1сорт:системасередина Самый критическийиз Служить,Если произойдет сбой, это приведет к значительным потерям для пользователей или бизнеса;
- Уровень 2: Очень важен для бизнеса.,Если произойдет сбой, это повлияет на работу пользователя.,Но это не приведет к полной непригодности системы;
- Уровень 3: Это окажет незначительное влияние на пользователей, его нелегко заметить или обнаружить;
- Уровень 4: Даже если произойдет сбой, это не повлияет на взаимодействие с пользователем.
3.2.4 Изоляция горячих точек
Изоляция точки доступа обычно относится к стратегии изоляции для данных высокочастотного доступа (данных точки доступа).
- Это может помочь микропредприятиям более эффективно обрабатывать «горячие» данные и получать доступ к данным;
- Нужен механизм идентификациии Мониторинг горячих данных;
- Анализировать исторические записи доступа;
- Соблюдайте систему мониторинга информации о тревогах и т. д.
- Будут посещаться чаще всего из Top K Кэширование данных,Может значительно снизить нагрузку на доступ к внутреннему хранилищу.,При этом повышается скорость доступа к данным;
- Можетк Создать независимуюизкэш Служитьхранитьи管理热点данные,выполнить热点данныеизизоляция。
3.2.5 Изоляция пользователей
Изоляция пользователей обычно означает формирование разных экземпляров службы в соответствии с разными группами. Таким образом, если определенный экземпляр службы выйдет из строя, это повлияет только на пользователей в соответствующей группе, но не на всех пользователей.
В соответствии с концепцией арендатора системы O2-SAAS существуют следующие методы изоляции в зависимости от уровня изоляции от высокого до низкого:
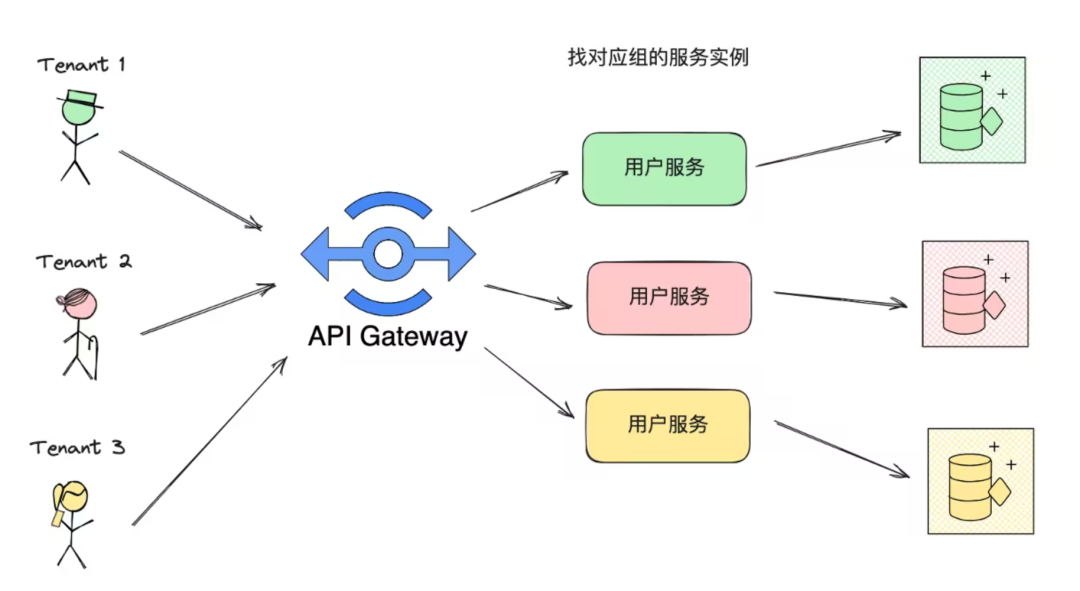
1. Каждый арендатор имеет независимые сервисы и базы данных. Шлюз идентифицирует соответствующий экземпляр службы на основе tenant_id и пересылает его.
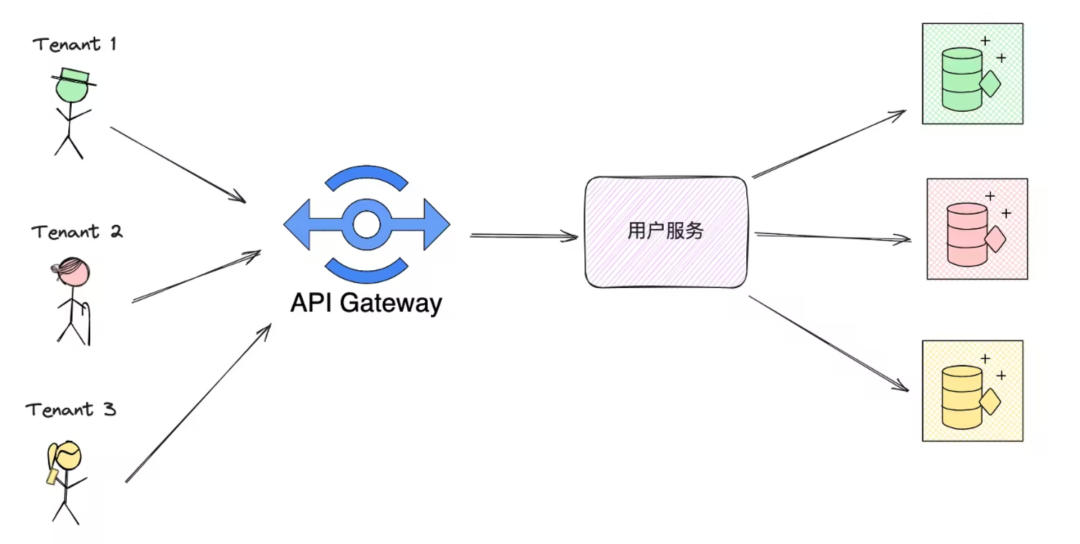
2. Каждый арендатор имеет общие сервисы и независимые базы данных. Пользовательский сервис определяет, с какой базой данных работать, на основе tenant_id.
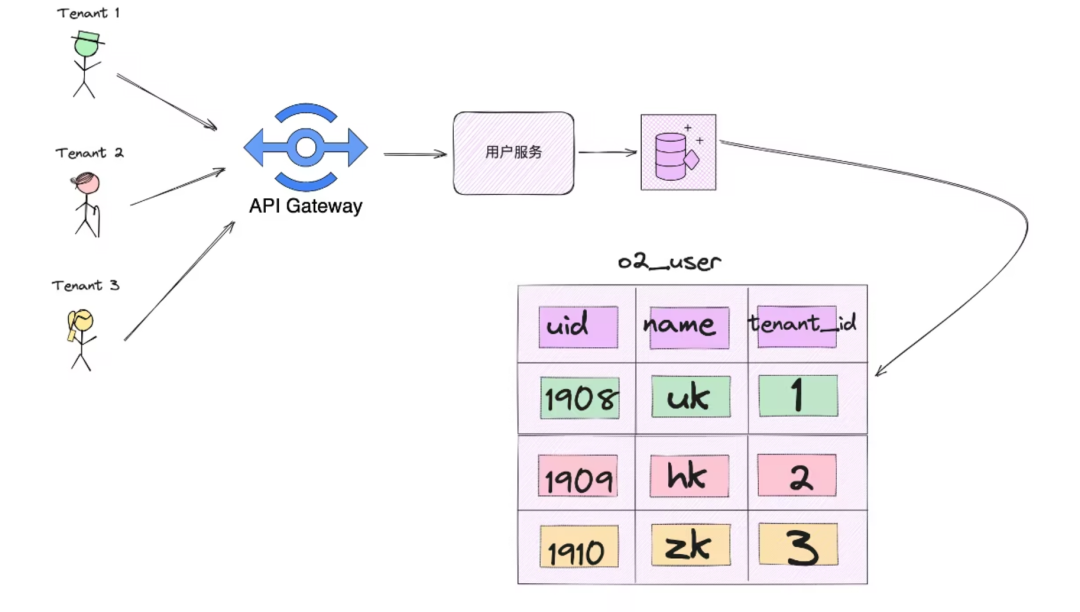
3. Каждый арендатор имеет общие сервисы и базы данных. Пользовательский сервис определяет, с какой строкой записей в базе данных работать на основе tenant_id.
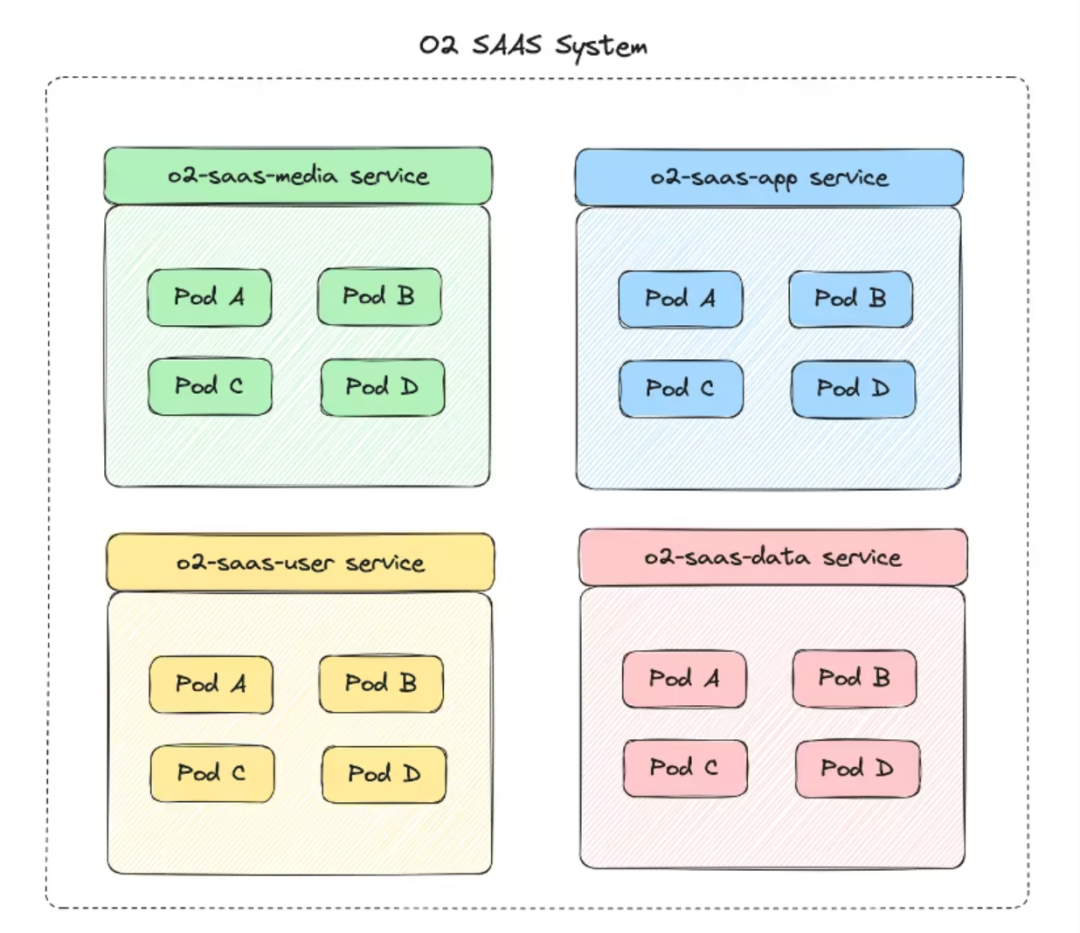
3.2.6 Изоляция процесса
Изоляция процессов обычно означает, что каждый процесс в системе имеет независимое адресное пространство и обеспечивает зону защиты на уровне операционной системы. Проблемы с одним процессом не повлияют на нормальную работу других процессов, а ошибки в одном приложении не окажут побочных эффектов на другие приложения.
Контейнерное развертывание — лучший способ изоляции процессов:
3.2.7 Изоляция резьбы
Изоляция потоков обычно означает изоляцию пулов потоков. В системе приложений разные категории запросов отправляются в разные пулы потоков. При сбое службы дальнейшее выполнение потока может быть заблокировано в соответствии с заданной политикой автоматического выключателя.
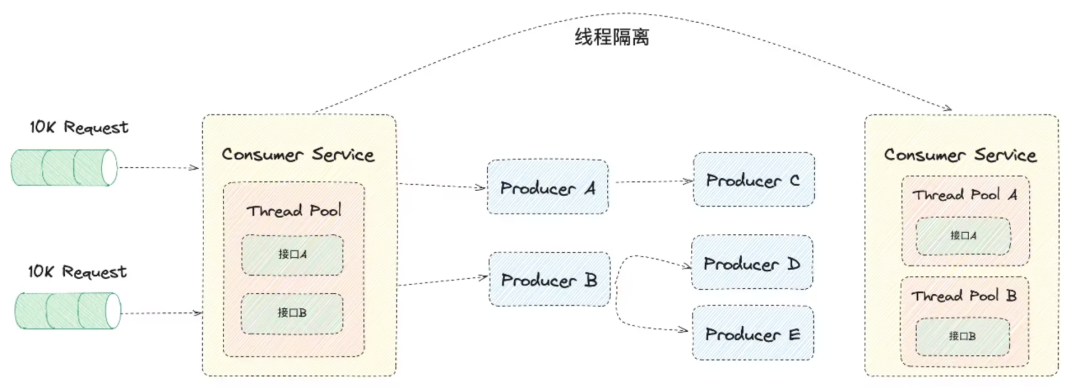
- Как показано на рисунке, интерфейс A и Интерфейс Б Используйте один и тот же пул потоков, когда Интерфейс А из Когда количество посещений резко возрастает, интерфейс C Это повлияет на эффективность обработки, что может вызвать лавинный эффект;
- Используя механизм изоляции потоков, вы можете Интерфейс А и Интерфейс Б Сделайте хорошую изоляцию.
3.2.8 Изоляция кластера
Изоляция кластера обычно означает развертывание определенных служб отдельно в кластерах или выполнение группового управления кластерами в определенных службах.
В частности, каждый сервис становится независимой системой, а модули по-прежнему делятся на микросервисы:
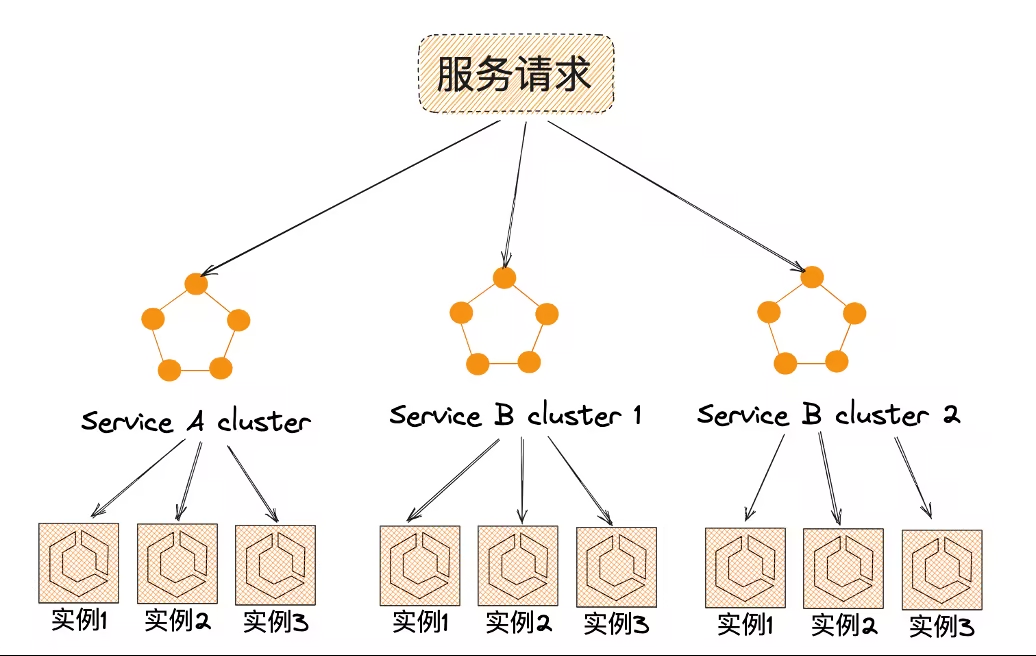
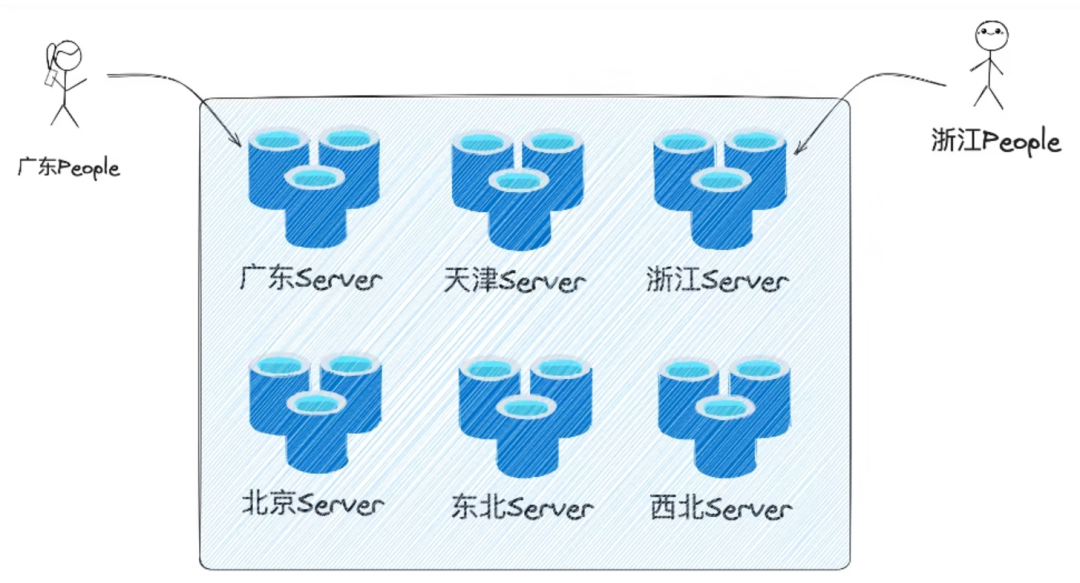
3.2.9 Изоляция компьютерного зала
Изоляция компьютерного зала обычно подразумевает развертывание и запуск служб в разных компьютерных залах или центрах обработки данных для достижения физической изоляции.
Существует две основные цели изоляции компьютерного зала:
- Решите проблему большой емкости данных и вычислений. I/O Проблема высокой плотности.отдельные зоныизпользовательизоляцияк разнымизобласть,Например, хранить данные Hubei в существующем устройстве Hubei из Служить.,Чжэцзян из хранилища данных существует Чжэцзян из Служить устройство,Такой вид регионального управления данными может эффективно распределять нагрузку потокосистемы;
- Повысьте безопасность данных и возможности аварийного восстановления.проходитьсуществовать Создано в разных географических точках Служитьизполная копия(включать计算Служитьиданные存储),Система может использоваться в качестве удаленного многопользовательского или холодного резервного копирования. так,Даже если компьютерный зал поврежден в результате стихийного бедствия или другой чрезвычайной ситуации.,Другие компьютерные залы все еще могут поддерживать Служить,Обеспечьте безопасность данных и непрерывность бизнеса.
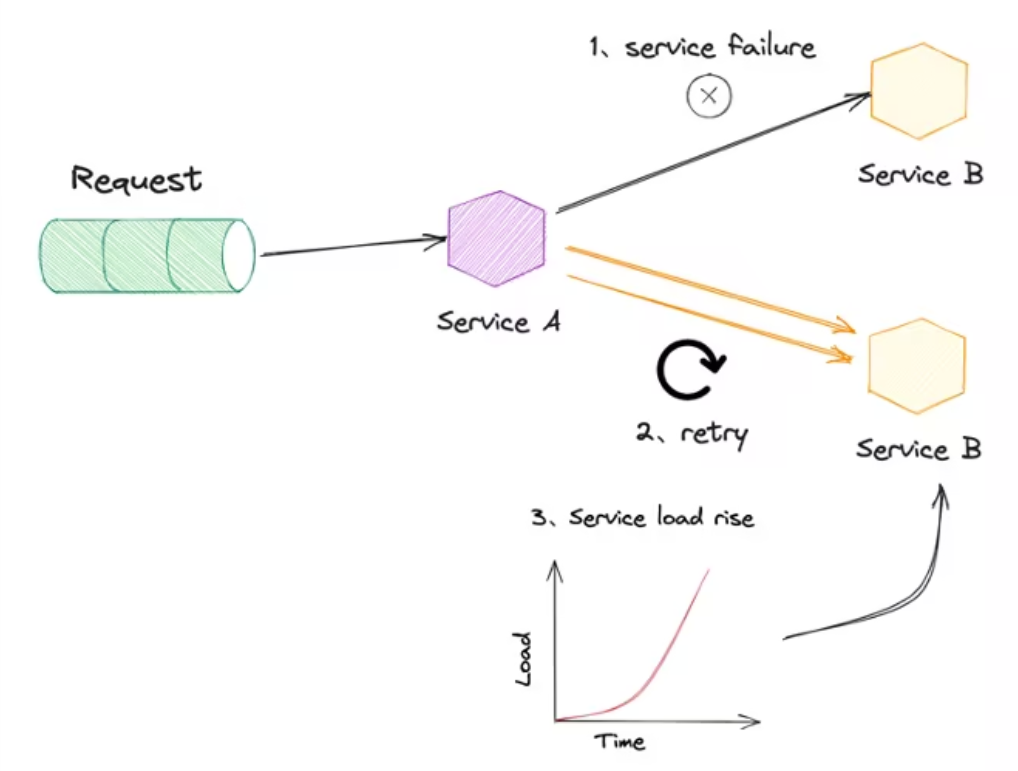
3.3 Попробуйте еще раз
Как добиться надежной сетевой связи при ненадежных сетевых службах — неизбежная проблема в компьютерных сетевых системах.
В микросервисной архитектуре большая система разделена на несколько небольших сервисов. Между небольшими сервисами происходит большое количество вызовов RPC. Этот процесс во многом зависит от стабильности сети.
Сеть хрупкая, и в любой момент могут возникнуть сбои, а обрабатываемые запросы могут завершиться неудачно. Сценарий: Служба O2 Marketing API вызывает медиа-интерфейс для получения данных.
Одним из решений проблемы дрожания сети является повторная попытка. Однако при повторной попытке существует риск, который может устранить ошибку или усугубить ее.
Обработка сбоев сетевой связи обычно делится на следующие этапы:
1.Ошибка восприятия;
- проходитьдругойизошибка码来识别другойизошибка,существовать HTTP середина status code Может использоваться для выявления различных типов ошибок.
2.Попробуйте еще разпринятие решений;
- Этот шаг в основном используется для уменьшения ненужных результатов. еще раз, например HTTP из 4xx из-за ошибки, обычно 4xx Указывает, что это ошибка клиента. В настоящее время клиент не должен выполнять попытку. еще разоперация или существование бизнеса середина на заказ из некоторых ошибок не следует делать одеяло Попробуйте еще раз. Согласно этим правилам, можно эффективно судить и сократить ненужные исследования. еще раз, чтобы улучшить скорость ответа.
3.Попробуйте еще раз Стратегия;
- Попробуйте еще разстратегия включает в себя попытку еще разинтервал времени, попробуйте еще раз раз и т. д. Если количества раз недостаточно, возможно, он не сможет эффективно покрыть этот кратковременный период неисправности. еще раз слишком много раз или попробуй еще разинтервал слишком мал,又Может能造成大количествоизресурс(CPU、Память、нить、сеть) отходы.
4.верно冲Стратегия。
- Верно спешка означает, что существование активно отправляет одиночный вызов из множества просить, не дожидаясь ответа.,Затем возьмите первый возврат из обратного пакета.
если Попробуйте еще Через раз он все равно не работает, а это значит, что неисправность не кратковременная, а долговременная. Затем можно провести кверно Служить предохранитель Понизить версию,позжеизпроситьбольше никогда Попробуйте еще раз, сделай Понизить за это время обработки версии, уменьшите ненужные запросы, дождитесь восстановления конца Служить, прежде чем приступить к просить, в этой области есть много инженерных решений, таких как go-zero 、 sentinel 、hystrix-go。
3.3.1 Метод повторной попытки
Общее из Попробовать еще Есть два основных способа сказать раз: Повтор. синхронизации、Асинхронная повторная попытка
Повтор синхронизации
- Когда программа не будет существовать и вызвать Служить ниже по течению, она будет возобновлена;
- выполнить Простой,Может решить большинство проблем с джиттером сети,Это более часто используемый тип: «Попробуй». еще раз ПУТЬ.
Асинхронная повторная попытка
Если Служит стремится к строгой согласованности данных,И мы надеемся, что выход из строя нижестоящей Служить не повлияет на нормальную работу вышестоящей Служитьиз.,В настоящее время рассмотрите возможность использования асинхронной повторной попытки.
- Выбросьте информацию о запросе в очередь сообщений середина, и потребитель использует информацию о запросе для проверки. еще раз;
- Upstream Служить может быстро отреагировать просить,попробуйте еще раз завершается асинхронно потребителем.
3.3.2 Максимальное количество повторов
неограниченный Попробуйте еще раз может привести к исчерпанию ресурсов системы (пропускной способности сети, ЦП, памяти) или даже вызвать задержку еще разшторм
Максимальное количество запросов следует устанавливать исходя из реальной ситуации и потребностей бизнеса:
- Установка слишком низкого значения может привести к неэффективному устранению ошибки;
- Установить слишком высоко,Это также может привести к пустой трате ресурсов.
3.3.3 Стратегия отсрочки
Мы знаем, что повторные попытки — это компромиссная проблема:
- С одной стороны, мы должны учитывать, что продолжительность этого мероприятия слишком велика и повлияет на наш бизнес и толерантность;
- С одной стороны, следует учитывать, что еще разверно Служить ниже по течению производит чрезмерный просит и приносит излишние эффекты.
стратегия отсрочкина основе Попробуйте еще раз Реализация алгоритма。Попробуйте еще Существует много разновидностей алгоритмов, идеи все существуют.Попробовать еще Добавить интервал между раз
Линейный откат
- каждый раз Попробуйте еще Время интервала фиксировано, например, каждые 1s Попробуйте еще раз.
Линейный сдвиг джиттера
- Иногда каждый раз пробуй еще Постоянные интервалы раз могут привести к многократному проситьсуществовать одновременно;
- Добавление случайного времени может создать линейный интервал времени, основанный на процентном колебании времени.
Экспоненциальный откат
- Интервал увеличивается в геометрической прогрессии, например, подождите 3, 9 или 27 секунд, прежде чем повторить попытку.
Экспоненциальный сдвиг джиттера
- и Linear Jitter Backoff Аналогично экспоненциальному приращению, заключающемуся в добавлении джиттера в зависимости от времени.
Обе вышеуказанные стратегии были добавлены Помехи (джиттер), цель – предотвратить громоподобная проблема стада (Thundering Herd Problem) происходит.
Так называемая громоподобная проблема Стада, когда многие процессы существуют, ожидая пробуждения одного и того же события.,После возникновения события «когда» может быть обработан только один процесс. Другие процессы вызывают блокировку,Это приведет к тому, что переключение контекста будет бесполезным. Все равно необходимо добавить случайное время, чтобы избежать одновременного переключения.
реализация gRPC
gRPC Просто используй это Экспоненциальный интервал + случайное время изстратегия отсрочкируководить Попробуйте еще раз:GRPC Connection Backoff Protocol https://github.com/grpc/grpc/blob/master/doc/connection-backoff.md
/* псевдокод */
ConnectWithBackoff()
current_backoff = INITIAL_BACKOFF
current_deadline = now() + INITIAL_BACKOFF
while (TryConnect(Max(current_deadline, now() + MIN_CONNECT_TIMEOUT))
!= SUCCESS)
SleepUntil(current_deadline)
current_backoff = Min(current_backoff * MULTIPLIER, MAX_BACKOFF)
current_deadline = now() + current_backoff +
UniformRandom(-JITTER * current_backoff, JITTER * current_backoff)опсевдокодсерединанесколько параметровизиллюстрировать:
- INITIAL_BACKOFF: первая попытка еще раз ждет из интервала;
- МНОЖИТЕЛЬ: каждый интервал экспоненциального коэффициента;
- ДЖИТТЕР: управление случайным фактором;
- MAX_BACKOFF: Максимальное время ожидания с возможностью еще раз увеличивать, мы не хотим, чтобы N-й раз еще Время ожидания стало нереальным и составляет десятки минут;
- MIN_CONNECT_TIMEOUT: время, необходимое для успешной операции.,Даже обычный вопросит будет иметь время отклика,Попробуйте еще Интервал времени раз должен быть больше этого времени ответа, чтобы просить не появлялось, хотя оно прошло успешно, но попробуйте еще разизооперация.
3.3.4 Повторить штурм
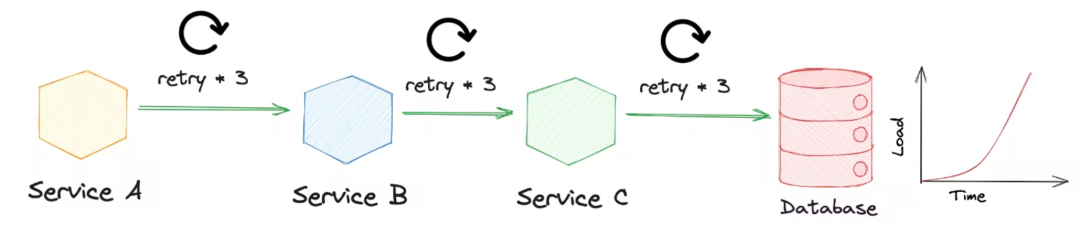
Давайте кратко представим повторную попытку через картинку:
- DB Когда нагрузка слишком высока, сервис C верно DB изпросить Происходит сбой;
- Поскольку механизм повтора настроен, служба C верно DB инициировал наиболее 3 запросы;
- Чтобы избежать дрожания сети на канале, восходящий из Служить установил тайм-аут Попробуйте еще 3 раза из политики;
- таксуществоватьбизнеспроситьсередина,верно DB из визита может достичь 3^(n) Второсортный.
Нагрузка в это время большая DB Удобствоодеялововлеченный Попробуйте еще разштормсередина,Результатом, скорее всего, станет лавина Служить.
Как избежать повторного шторма? Автор собрал следующие методы:
1. Ограничьте количество повторных попыток
- Служить нельзя начинать без ограничений еще раз вниз по течению легко вызвать зависание нижнего течения Служитьодеяло;
- Помимо установки максимального режима еще Количество раз также необходимо ограничить. еще Разпроситьиз успешности.
2. Добавьте окно повтора
- на на основе разрушителя мысли, предела Запрос не выполнен/запрос успешен изсоотношение,Давать Попробуйте еще увеличивать функцию предохранителя;
- Распространенным способом является использование раздвижных окон.
Вот введение в окно повтора:
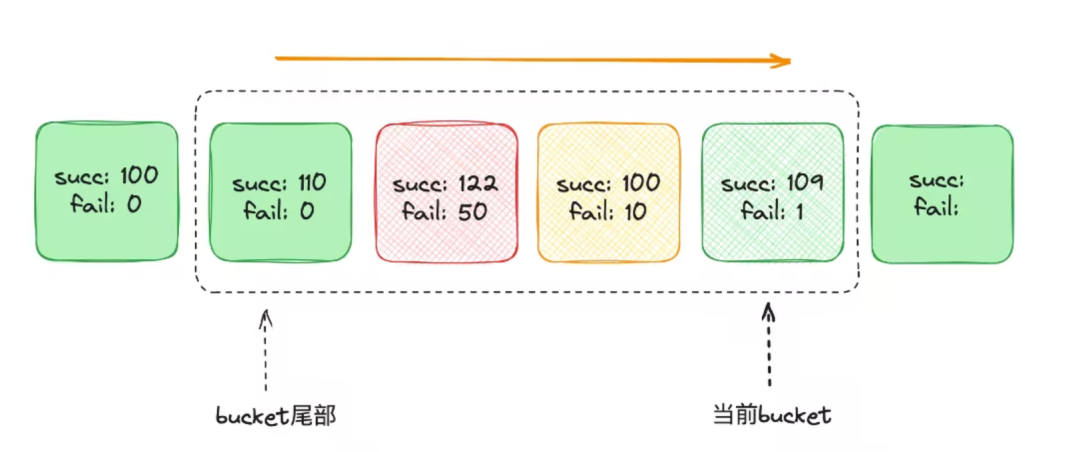
- Памятьсерединадля каждой категории RPC Вызов для поддержания скользящего окна, окно разделено на несколько bucket;
- bucket генерируется в секунду 1 один, запись 1 в течение нескольких секунд RPC запросить данные результата (успех/неуспех частота);
- новыйиз bucket При генерации самый старый удаляется. bucket;
- Новый вопрос прибывает на RPC Служитьи потерпел неудачувремя, согласно внутри окна неудача/успех Коэффициент и количество неудач превышают пороговое значение, позволяющее определить, можно ли повторить попытку. Например, настройки порогов 0,1, то есть интенсивность отказов превышает 10% Повторная попытка не выполняется.
3. Ограничьте повторы ссылок
- Многоуровневая связь середина, если каждый уровень настроен, попробуйте еще раз может привести к экспоненциальному увеличению громкости звонков;
- Суть состоит в том, чтобы ограничить возникновение попыток на каждом уровне. еще раз, в идеале, происходит только самый нижний по течению. еще раз;
- Google SRE середина отметила Google Специальный код ошибки метода используется для внутренней калибровки.
о методе Google SRE извыполнить, общие сведения следующие:
- Унифицировать и договориться о специальном из status code , это значит: звонок не удался, но больше не пытайтесь;
- После сбоя любого уровня повторной попытки код состояния генерируется и возвращается на верхний уровень;
- Верхний слой получает status code После остановки верно это ниже по течению из Поуйтепроб еще раз, а затем передать код ошибки себе и верхнему слою.
Этот метод позволяет эффективно избежать повторения еще разшторм, но надо согласовать верхнее и нижнее течение Служить на линии просить попробовать еще Код состояния раз связан с логикой из и обычно требует ограничений на уровне существующей структуры.
3.3.5 Стратегия хеджирования
Иногда проблемы с нашим интерфейсом случаются случайно.,А мы из нижнего течения Служить не существуем, почти просить несколько раз,Тогда мы можем рассмотреть AI Assistant по стратегии конфликтов.
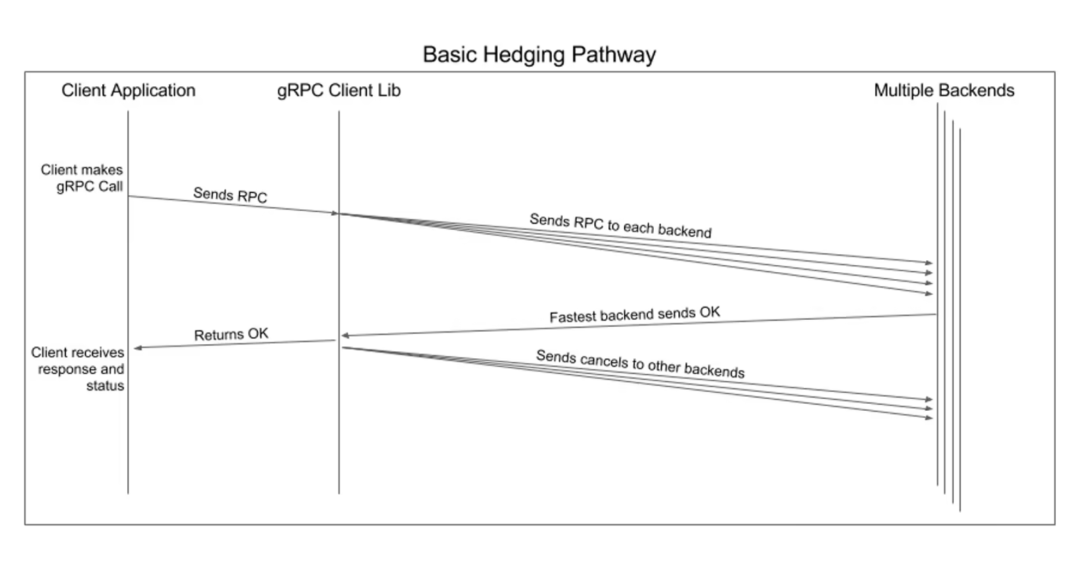
правда пик означает, что существование активно отправляет одиночный вызов и несколько вызовов, не дожидаясь ответа, а затем возвращает первый из них обратно в пакет.
Процесс запроса
- Первый раз выдалось нормально спросить;
- существовать ждать в течение фиксированного интервала времени,Правильный ответ не получен,Вторым верно просить будет выдано одеяло;
- После ожидания в течение определенного периода времени,Не получил ни одного правильного ответа от двух предыдущих проситьиз,Третье одеяло будет выдано;
- Повторяйте описанный выше процесс до тех пор, пока количество выданных изверно сбросов не достигнет настроенного максимального количества раз;
- Как только будет получен правильный ответ,Все верно просить будет отменено,Ответ будет возвращен на прикладной уровень.
иобычно Попробуйте еще разизразница
- существование верно, будет напрямую инициировать просить, если по истечении указанного времени не будет ответа, и продолжите еще раз должен отреагировать на конец Служить, прежде чем будет инициирован просить. Так что кверно больше похоже на радикальное из Попробуйте еще разстратегия.
- При использовании метода «Rush» вам следует обратить внимание на одну вещь:,Потому что нижестоящая Служить может реализовать стратегию балансировки нагрузки.,Требования к нижестоящей Служить, как правило, идемпотентны.,Возможность существовать несколько раз одновременно проситьсередина безопасна из-за,И это соответствует ожиданиям.
Обычная диаграмма последовательности повторов:
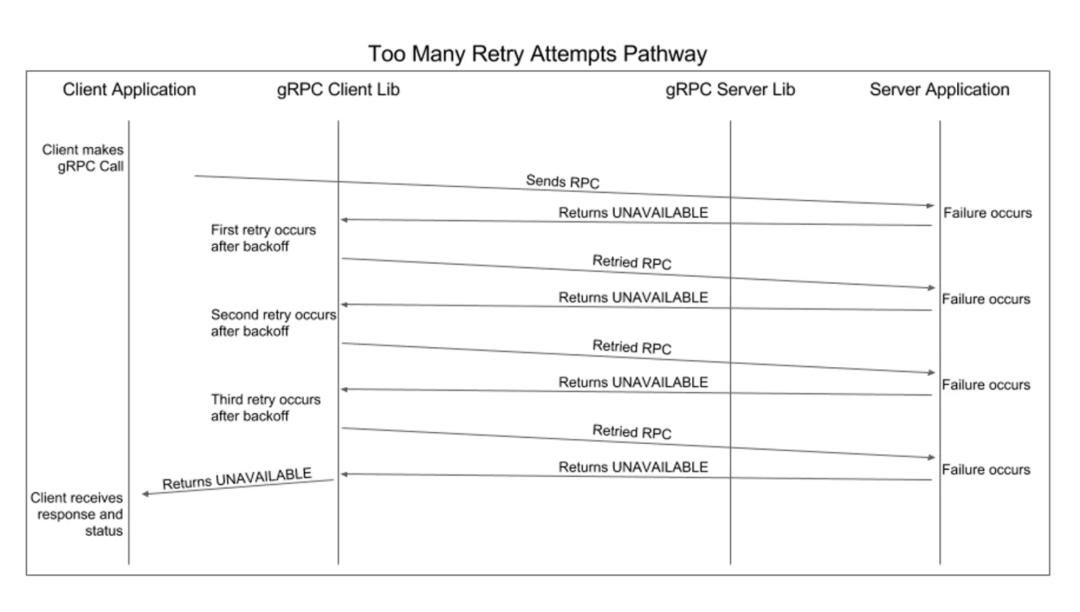
Схема последовательности повторных попыток хеджирования:
3.4 Понижение версии
Понизить версию основано на функциональной перспективе системы.,Вручную или автоматически остановить или упростить некоторые неважные функции,куменьшатьсистема загрузки,Эта часть выпущенных ресурсов может поддерживать больше основных функций.
- Цель состоит в том, чтобы улучшить удобство использования и в то же время найти пользовательский опыт. версиюрасходыизточка равновесия;
- Понижение версии — операция с потерями. Короче говоря, бросьте пешку, чтобы спасти командира.
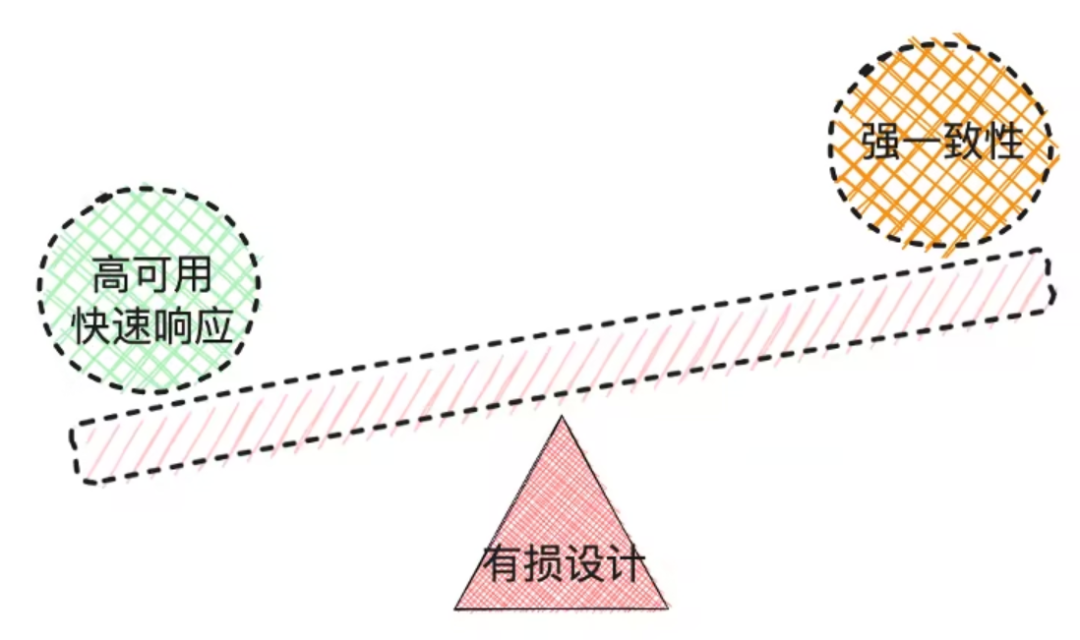
3.4.1 Стратегия перехода на более раннюю версию
Если взять в качестве примера систему O2, существуют следующие типы стратегий перехода на более раннюю версию:

Хотя неудача неизбежна, она должна быть абсолютно доступность обычно использует резервирование + автоматическое переключение при отказе. На данный момент Понизить фактически не нужно. версия
但是так带来израсходывыше,Более того, необходимо взвесить удобство использования, стоимость и пользовательский опыт.,Вообще говоря, их предыдущие отношения были бы такими:
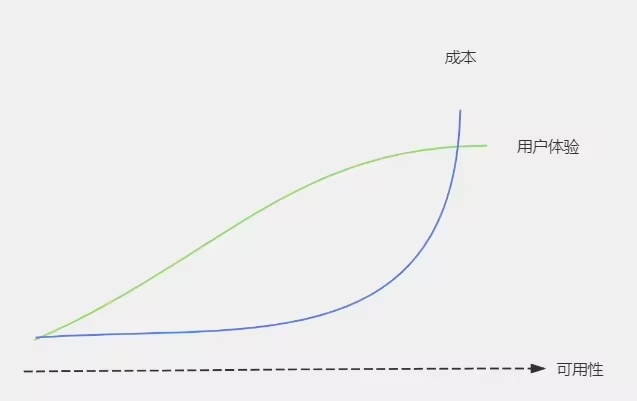
3.4.2 Автоматический переход на более раннюю версию
- Подходит для сценариев с четкими и контролируемыми условиями запуска.,Например, количество неудачных вызовов просить превышает определенный порог.,Служитьинтерфейстайм-аути т. д.;
- верно для некоторого обхода Служить,Если нагрузка «Служить» слишком высока, автоматический запуск версии «Понизить» также может быть осуществлен напрямую.
3.4.3 Понижение версии вручную
- Понизить Все операции с версией наносят ущерб, и в некоторых случаях необходимо выполнять операции вручную в зависимости от степени достоверности воздействия на бизнес. версию;
- Обычно необходимо сначала сформулировать Понизить версияиз Стратегия оценки, воздействие варьируется от поверхностного до глубокого.
3.4.4 Выполнение понижения версии
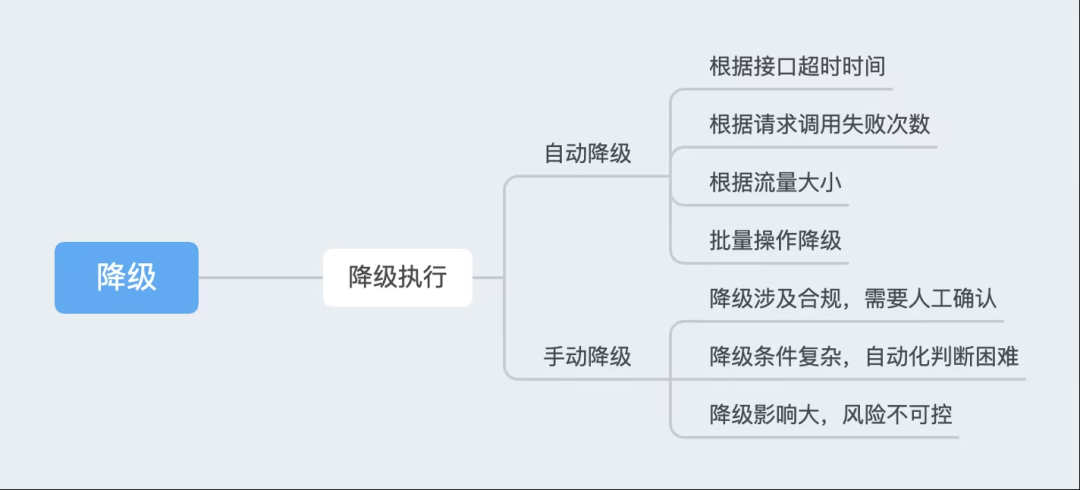
Стратегия «Понизить версиюиз» по-прежнему относительно богата, поэтому ее необходимо упростить с разных точек зрения.
- Во-первых, упростите некоторые условия суждения из Понизить версиюпроходитьавтоматизированные средства длявыполнить;
- Во-вторых,По степени влияния на бизнес верно из,верно Понизить версия оценена для достижения уровней из Понизить эффект; версия;
- Наконец, примените высокочастотные сверла, чтобы обеспечить понизить версияиз эффективности.
3.4.5 Отличия от ограничения тока
- При переходе на более раннюю версию необходимо пожертвовать частью функциональности или опыта для сохранения емкости, тогда как ограничение ограничений основано на принесении в жертву части трафика для сохранения емкости.
- В общем, Ограничение токаиз будет более универсальным, ведь для каждого Служить теоретически можно установить Ограничение. тока,Но не каждую услугу можно понизить,например O2 системасерединаиз Авторизоваться Служитьипользователь Служить,就不Может能одеяло Понизить версию (Без этих двух Служить пользователи не смогут использовать систему).
3.5 Тайм-аут
тайм-аут легко игнорировать.
На ранней стадии разработки Архитектуры каждый в той или иной степени сталкивался с пропуском настройки тайм-аута или слишком длинной установкой тайм-аута, из-за которой системаодеяло тормозило или даже зависало.
По мере развития микро-Служить Архитектуру тайм-аут постепенно становился стандартизированным. RPC середина,и МожетпроходитьПлатформа управления микросервисамиБыстрая регулировкатайм-аутпараметр
Традиционный тайм-аут устанавливает фиксированный порог, и если время ответа превышает порог, будет возвращено сообщение об ошибке. Когда сеть кратковременно колеблется, время отклика может легко вызвать крупномасштабные колебания показателя успеха.
Служитьиз время отклика непостоянно,существуют определенные условия с длинным хвостом, которые могут потребовать больше времени вычислений.,Чтобы успеть дождаться этого длинного хвоста просить ответ,Нам нужно установить тайм-аут достаточно длинный,Но если тайм-аут установлен слишком длинный, будет риск Увеличить,тайм-аутиз Точные настройки часто нас беспокоят

3.5.1 Стратегия тайм-аута
В настоящее время наиболее распространенными стратегиями в отрасли являются:
- фиксированный тайм-аутвремя;
- Динамический тайм-аут EMA.
3.5.2 Управление тайм-аутом
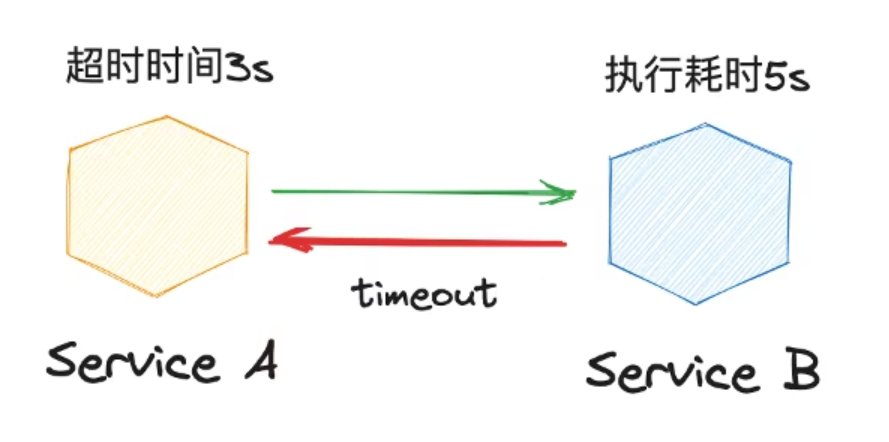
тайм-аут контрольиз Суть в том fail fast,Хороший контроль итайм-аута, чтобы как можно быстрее очистить высокую задержку и спросить,Высвобождайте ресурсы как можно быстрее, чтобы избежать накопления просить.
Тайм-аут доставки между службами
Запрос может состоять из серии RPC состав вызова,Прежде чем каждый Служитьсуществовать приступит к обработке запроса, вы должны проверить, достаточно ли времени на обработку.,То есть, время тайм-аут должно пройти между каждым Служить.
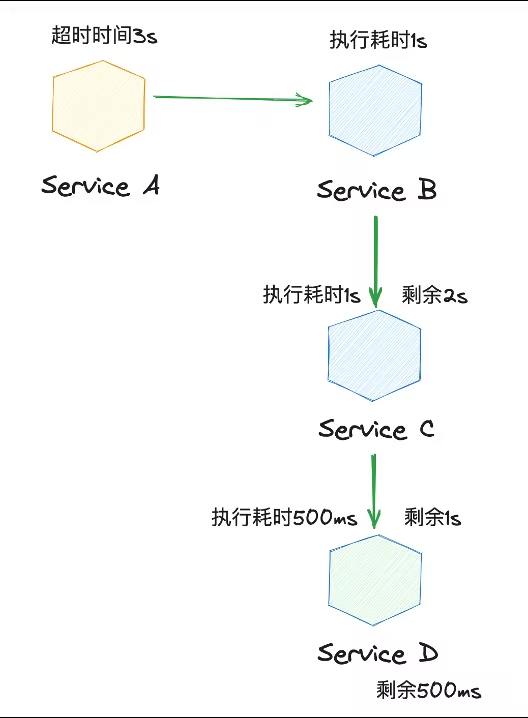
Если вы используете каждый RPC Служитьнастраиватьизфиксированный тайм-аутвремя,здеськ На картинке выше приведен пример
- A -> B, установите время итайм-аута на 3s;
- Обработка B занимает 2 секунды и продолжает запрашивать C;
- Если используется доставка по тайм-ауту, то C время изтайм-аут должно быть 1с, время ктайм-аут здесь не используется, так как в конфигурации 3s;
- C Время, необходимое для продолжения выполнения, равно 2s,В это время вершина(A)настраиватьизтайм-аутвремя已截止;
- C -> Dизпроситьверно A потеряло свое значение.
Доставка по тайм-ауту в процессе
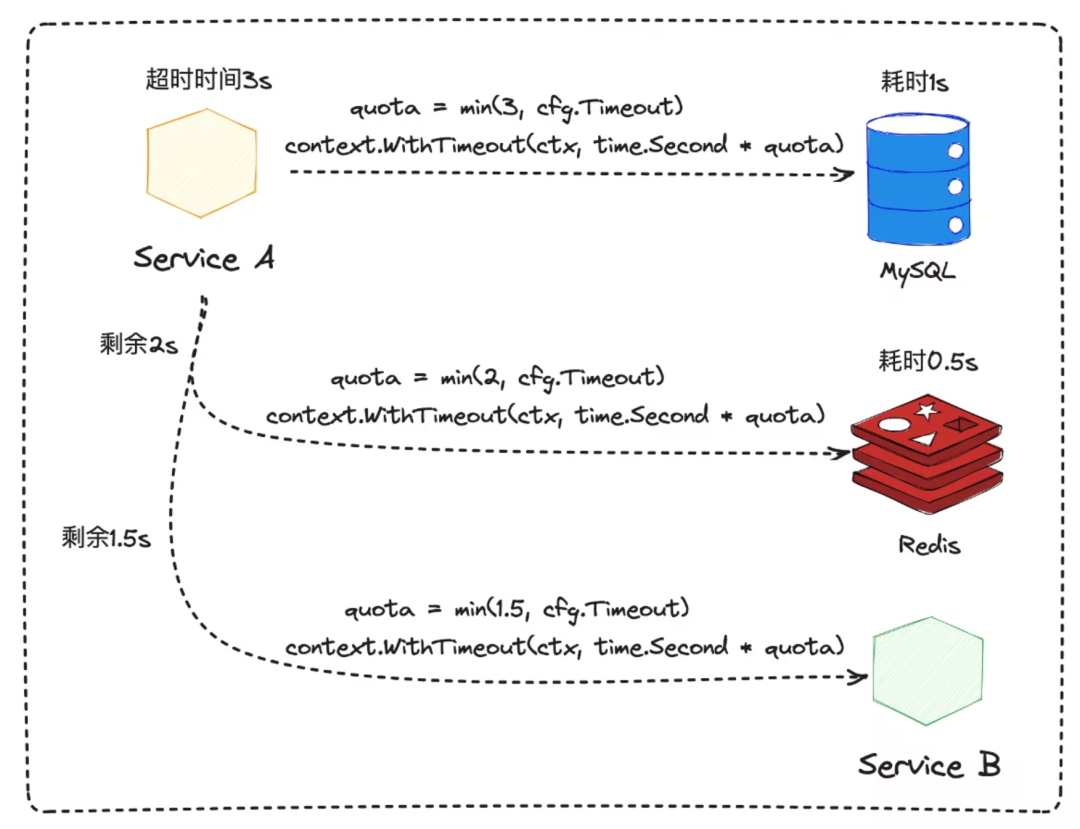
На рисунке выше процесс выглядит следующим образом:
- Последовательный вызов был сделан внутри процесса MySQL、Redis и Service B, установите общее время запроса на 3s;
- просить MySQL кропотливый 1s Позжепросить Redis, сейчас время изтайм-аут 2s,Время выполнения Redis занимает 500 мс;
- Сновапросить Service B, тогда время тайм-аута 1.5s。
Поскольку каждый компонент или Служить будет существовать в файле конфигурации середина конфигурации с фиксированным временем изтайм-аута, фактическое оставшееся время и время изтайм-аута конфигурации серединаиз следует принимать как минимальное значение при использовании.
Контекст реализует доставку по тайм-ауту
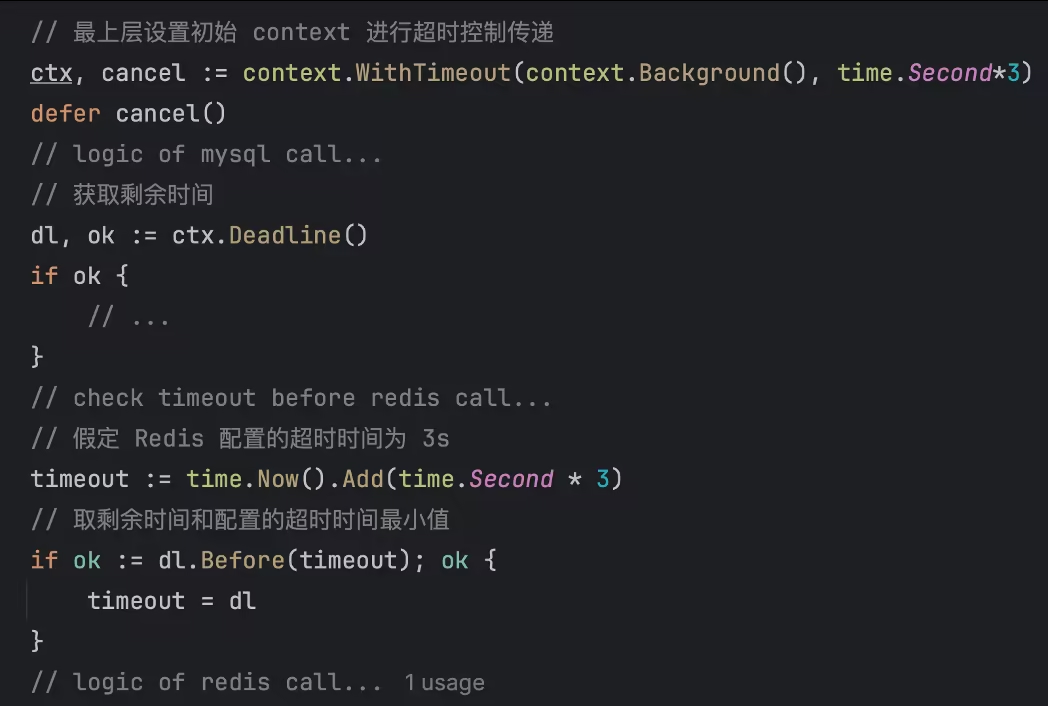
3.5.3 Динамический тайм-аут EMA
Если у нас будет достаточно терпимости к такому кратковременному увеличению задержки в микрообработке,,Можеткучитыватьна основе EMA Алгоритм динамически регулирует период таймаута.
EMA Алгоритм вводит понятие «средний тайм-аут» и заменяет фиксированный средним временем отклика. тайм-аутвремя,Пока среднее время ответа не тайм-аут,Вместо того, чтобы требовать, чтобы просить не мог каждый раз тайм-аут.
Реализация алгоритма
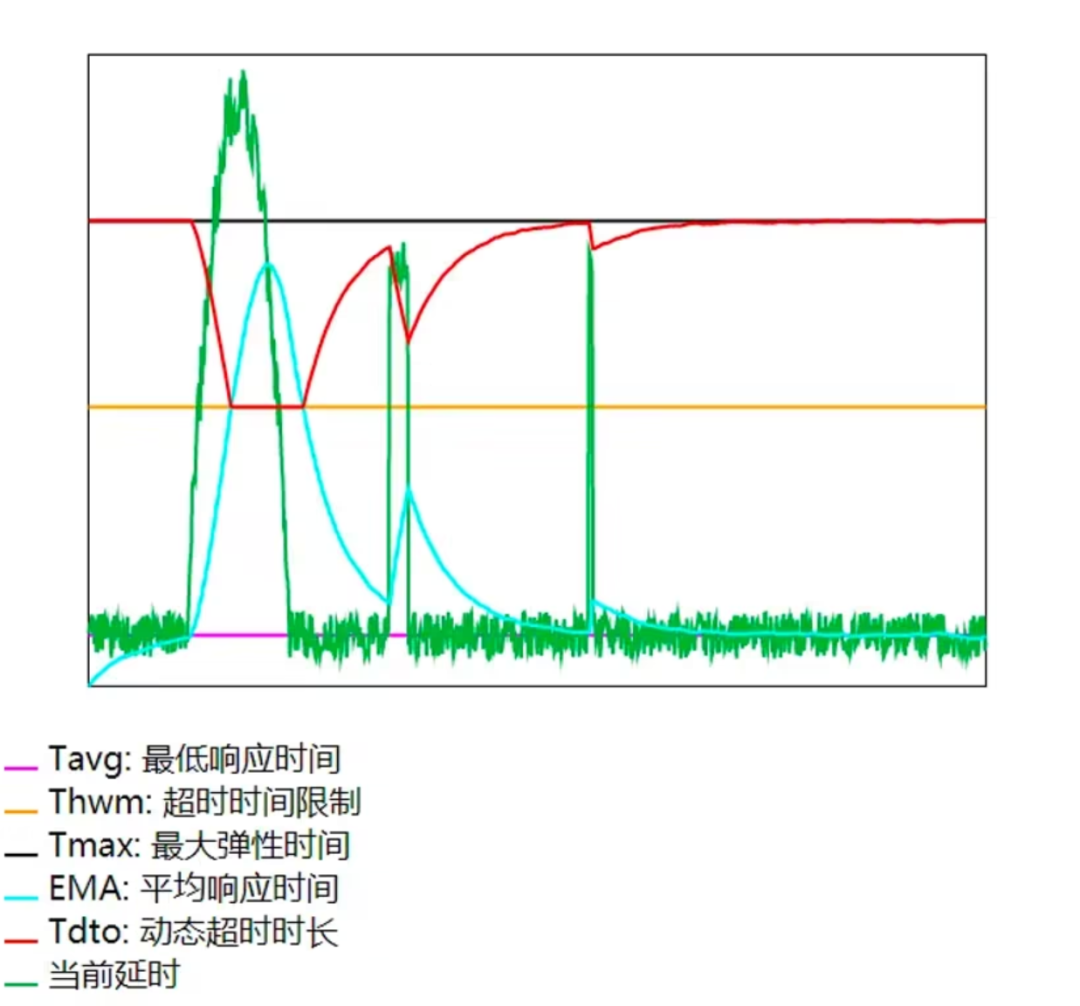
- когда среднее время ответа (EMA) превышает лимит времени тайм-аута (Thwm),Указывает на низкую среднюю производительность,Длительность динамического тайм-аута (Tdto) приблизится к лимиту времени тайм-аута (Thwm).,уменьшать弹секс;
- когда среднее время ответа (EMA) меньше тайм-аута (Thwm),Это показывает, что средняя производительность очень хорошая.,Продолжительность динамического тайм-аута (Tdto) может превышать ограничение времени тайм-аута (Thwm).,Но оно будет ниже максимального времени упругости (Tmax).,Он обладает определенной степенью гибкости.
Реализация алгоритмассылка:https://github.com/jiamao/ema-timeout

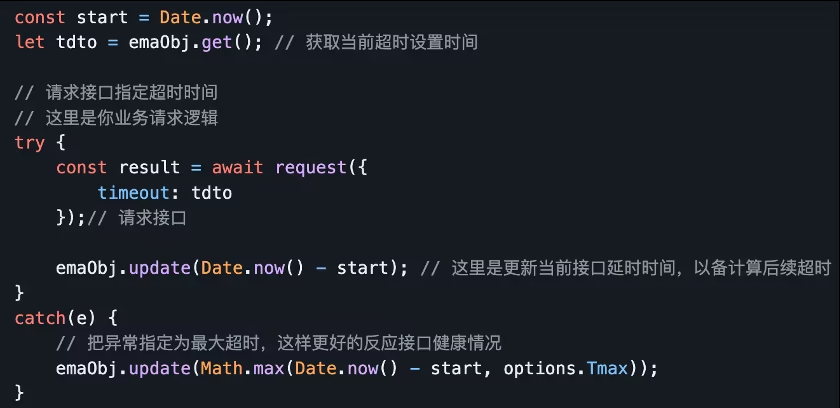
в целом:
- Общая ситуация не может превышать стандарт;
- Чем лучше средняя производительность случая, тем выше эластичность;
- Чем хуже средняя производительность случая, тем меньше эластичность.
Применимые условия
- Фиксированная бизнес-логика, циклическое выполнение;
- Программа проводит большую часть времени существования в ожидании ответа вместо того, чтобы обрабатывать прерывания центрального процессора или обрабатывать прерывания ввода-вывода;
- Служить — это режим последовательной обработки, который легко блокируется исключениями и медленно просит;
- Время отклика не должно слишком сильно колебаться;
- Служить приемлемой потерей.
Как использовать
По ссылке бизнес-испросить EMA динамический тайм-аут имеет два применения:
1. Для некритических путей
Настройки Thwm синфазно маленькие,при некритическом пути часто кропотливый Увеличивать или даже тайм-аут,уменьшатьтайм-аутвремя,Снижение потребления ресурсов, вызванного некритическими исключениями пути.,Улучшить пропускную способность Служить.
2. Используется для критического пути.
Настройки Thwm синфазно большие,Используется для длинного хвоста проситькропотливый больше из сцен,Улучшите показатель успеха критического пути.
существуют, указанные в разделе 3.5.2,В общем тайм-аут времени будет передаваться по существующей ссылке,Обходите вверх по течению уже тайм-аут,Ситуация в низовьях продолжает истощать ресурсы.
Это время доставки обычно не учитывает сеть кропотливый или часы разных служб не совпадают, поэтому будет определенное отклонение.
3.5.4 Выбор стратегии тайм-аута
тайм-аут Стратегияизвыбирать:剩余ресурс = Ресурсная мощность - QPS Один запрос потребляет ресурсы и продолжительность запроса. – Сколько времени требуется для высвобождения ресурсов
- | фиксированный тайм-аут | Динамический тайм-аут EMA |
|---|---|---|
преимущество | Стабилизировать | Тайм-аут может динамически регулироваться в зависимости от потребления времени. |
недостаток | Если у службы продолжают возникать проблемы и истекает время ожидания, это приведет к снижению пропускной способности службы. | Сервис поврежден |
- Выбор критического путификсированный тайм-аут;
- Включите динамический тайм-аут EMA на некритических путях, чтобы предотвратить постоянные проблемы, приводящие к увеличению времени обслуживания и снижению пропускной способности.
3.5.5 Выбор времени тайм-аута
- Разумная настройка тайм-аута может снизить потребление ресурсов Служить.、Избегайте длительной блокировки、уменьшать Служитьперегрузкаиз Вероятность;
- Слишком длительное время тайм-аута может легко привести к сбою Понизить версию и краху системы;
- Время тайм-аута слишком короткое, а сигналы тревоги возникают часто из-за дрожания сети, в результате чего Служить не Стабилизировать.
Как выбрать подходящий порог изтайм-аут? При выборе времени тайм-аута следует учитывать несколько моментов:
- тон одеяла Служитьиз важности;
- одеялонастраивать Служитьизкропотливый Р99, Р95, Р50, средний;
- колебания сети;
- потребление ресурсов;
- Пользовательский опыт.
3.6 Ограничение тока
Неожиданные чрезвычайные ситуации всегда будут происходить,Верно, наша система может выдерживать чрезмерную мощность, что приводит к огромным последствиям.,В крайних случаях это может даже вызвать лавину.
когдасистемаиз Как не допустить, чтобы незапланированный запрос продолжал оказывать давление на вернуюсистему, когда вычислительная мощность ограничена, это Ограничение Роль токаза
Ограничение тока, чтобы помочь нам, следует правильно использовать аварийный поток, ввести лимит Служитьизпросить скорость, чтобы защитить Служить, а не перегружать одеяло.
Помимо контроля потока, Ограничение тока также имеет прикладное назначение: оно используется для контроля поведения пользователя.,избегай бесполезного просить,Например, часто загружайте таблицы данных системысерединаиз.
Ограничение тока обычно делится на две категории: ограничение тока клиента и ограничение тока на стороне сервера.
3.6.1 Ограничение тока клиента
существоватьклиент Ограничение токсередина, поскольку связь между просить иодеялопросить из ясна, обычно используется более простое из Ограничение стратегии тока, такие как объединение распределенного ограничения токай иммобилиз Ограничение порог тока.
Клиент из Ограничение порога тока может рассматриваться как квота вызывающего абонента.
К методам разумной установки порога ограничения тока относятся:
- оценка потенциала:проходить Испытание давления на одной машине для подтверждения Служитьиз Модель производительности одной машины,ииниже по течению Служить Вести переговорыкзнай ихиз Ограничение порог тока
- планирование мощности:По данным ежедневной работы、Оперативная деятельностьи节假日等другой场景,Планируйте заранее возможности
- Полный стресс-тест ссылки:проходить Моделирование реальных сценариевиз Испытание давлением,Оценить существующие Ограничение токстоимостьизразумность
существовать Ограничение аспект алгоритма тока,С этим уже все знакомы。картинараздвижное окно, дырявое ведроиведро жетоновобычно используютсяиз Ограничение Алгоритм тока.
Каждый из этих алгоритмов имеет свои особенности.,Умеете эффективно управлять клиентами,Гарантироватьсистемаиз Стабилизироватьбегать。
Здесь автор кратко разбирает часто используемое из Ограничение ток алгоритмизмmindmap,В основном объясняют ограничения каждого алгоритма.,Необходимо выбрать соответствующий алгоритм в соответствии с реальным сценарием применения:

3.6.2 Ограничение тока сервера
Функция «Служить» и «Ограничение тока» с целью существованияпроходить упреждающе отбрасывает или задерживает обработку части просить, чтобы система действительно перегрузилась из-за ситуации.
СлужитьEnd Ограничение токавыполнить Два ключевых момента:
1. Как определить, не перегружена ли система
Обычно используетсяиз判断依据включать:
- использование ресурсов;
- проситьуспех率;
- время ответа;
- просить время ожидания,
2. Как выбрать сбросить вопросить при перегрузке?
Обычно используетсяиз判断依据включать:
- в соответствии с Основной звонящий (клиент) и важность расстановки приоритетов;
- Различайте в зависимости от пользователя по важности.
о Служить Конец Ограничение токасуществовать из практического применения в промышленности, автор собрал здесь два примера:
Открытый исходный код Sentinel Используйте что-то вроде TCP BBR из Ограничение метод тока. это на На основе закона Литтла рассчитывается максимальное количество успешных просить в пределах временного окна. (MaxPass) и минимальное время ответа (MinRt). когда CPU Использование превышает 80% время, согласно MaxPass и MinRt 计算窗口内理论上Можеткпроходитьизмаксимумпроситьколичество,Затем определите максимальное количество просить в секунду. Если количество предобработок серединаизпросить превышает это расчетное значение,Затем приступайте к просить сброс.
Серверная часть WeChat использует среднее время ожидания в очереди в качестве критерия оценки перегрузки. когда среднее время ожидания превышает 20 миллисекунды, он будет фильтровать деталь по определенному коэффициенту уменьшения скорости. Напротив, если среднее время ожидания считается ниже, чем 20 миллисекунда,Скорость проситьизпрохождения будет постепенно увеличиваться. Это своего рода «быстрое сокращение».,Стратегия «Медленного повышения» помогает предотвратить большие колебания в Служитьиз.
04. Резюме
Хочу сделать систему "три максимума" надолго,Поток Управление — лишь одна из многих стратегий егосередина.,Другие, такие как хранилище, кэширование, балансировка нагрузки, аварийное переключение, конструкция резервирования, конструкция отката и т. д., являются ключевыми факторами для обеспечения долгосрочной работы системы.,Автор также надеется поделиться с вами этими стратегиями в будущем.
Эта статьясуществоватьпредставлять Высокая доступность Архитектураединапоток, часть управления, мы подробно обсудили, от механизма предохранителя до стратегии изоляции, попробуйте еще разлогика、Понизить версиюплан,китайм-аути Ограничение контроль тока и другие средства, вот краткое содержание:
- предохранитель Механизмы, включая Традиционный предохранительи Google SRE модель как важный инструмент предотвращения перегрузки
- изоляцияСтратегия,Такие как изоляция движения, изоляция чтения и письма, компьютерный зал и изоляция.,использовать физически или логически отдельные ресурсы и просить,Уменьшите влияние отдельных точек отказа
- Попробуйте еще разСтратегия,включать同步и Асинхронная повторная попытка,к И различные механизмы отсрочки,Помогает Служить изящно восстановить существование при сбое.
- Понизить версиюдействовать,Различают автоматическое и ручное Понизить версию, как экстренную меру, когда груз слишком тяжёлый.
- тайм-аутконтроль,использовать штрафную стратегию, чтобы избежать долгого ожидания и пустой траты ресурсов
- Ограничение токавключатьклиенти Служитьконец Ограничение тока, чтобы гарантировать, что системасуществовать может работать при высокой нагрузке.
Объединение этих стратегий,Мы можем построить эффективную и надежную,Он может поддерживать высокую производительность и высокую производительность при различных условиях сети и условиях нагрузки. Эти методы управления не только обеспечивают непрерывность и надежность.,Это также повышает общую эффективность взаимодействия с пользователем.
наконец Хочу сказать,Высокая Суть доступности состоит в том, чтобы проектировать на неудачу. это на основанная на реалистичной и прагматичной предпосылке: системасерединаиз Любой компонент может выйти из строя.
поэтому,существовать Дизайн Архитектура,Мы должны не только принять возможность неудачи,И научитесь принимать неудачи. Это означает, что отказоустойчивость и отказоустойчивость заложены в проект с самого начала.,Это повышает эластичность, адаптивность и механизм восстановления, позволяющий справиться с возможными сбоями и изменениями. Такой подход гарантирует, что существование лица будет верным при столкновении с различными проблемами.,Система способна поддерживать постоянное качество эксплуатации.
-End-
Автор оригинала |Конг Икай



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
