Асинхронное программирование — 11 Асинхронная неблокирующая обработка Spring WebFlux
Обзор
Здесь мы в основном обсуждаем новый стек технологий WebFlux, представленный в Spring Framework 5.0, и представляем ценность и значимость его существования, модель параллелизма и применимые сценарии, способы реализации асинхронного программирования на основе WebFlux и принципы его внутренней реализации.
Spring WebFluxОбзор
Spring Web MVC, исходная веб-инфраструктура, включенная в среду Spring, была создана специально для API-интерфейсов сервлетов и контейнеров сервлетов.
Spring WebFlux, веб-фреймворк реактивного стека, был добавлен только в Spring версии 5.0. Он полностью неблокируется, поддерживает обратное давление Reactive Streams и может работать на таких серверах, как контейнеры Netty, Undertow и Servlet 3.1+. Среди них Flux в WebFlux происходит из объекта потока Flux в библиотеке Reactor.
Как показано в левой части рисунка ниже, это традиционный стек технологий Spring MVC на основе сервлетов, предоставляемый модулем Spring-Webmvc, а справа — стек технологий реактивного программирования (Reactive Stack) Spring-Webflux. модуль.
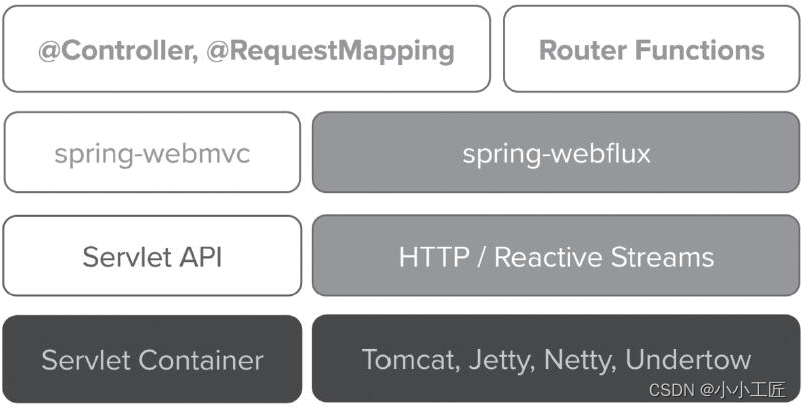
[Сравнение стека веб-технологий]
API сервлетов изначально был создан для однократного прохода по цепочке Фильтр → Сервлет. Асинхронная обработка запросов, добавленная в спецификацию Servlet 3.0, позволяет приложениям своевременно выходить из цепочки Filter-Servlet (быстро освобождая поток контейнера), но оставлять ответ открытым для последующей обработки асинхронным потоком. Поддержка асинхронной обработки Spring MVC построена на этом механизме. Когда контроллер возвращает DeferredResult, цепочка Фильтр-Сервлет будет завершена и поток контейнера сервлетов будет освобожден. Позже, когда DeferredResult установлен, запрос повторно отправляется с использованием значения DeferredResult (так же, как его вернул контроллер), чтобы возобновить обработку.
Напротив, Spring WebFlux не построен на основе API сервлетов и не требует дополнительных функций асинхронной обработки запросов, поскольку он асинхронен по своей конструкции. Обработка асинхронности встроена в спецификацию платформы и поддерживается на всех этапах обработки запросов.
С точки зрения модели программирования, как Spring MVC, так и Spring WebFlux поддерживают асинхронные и реактивные значения в качестве возвращаемых значений в методах контроллера. Spring MVC даже поддерживает потоковую передачу, включая функцию реактивного противодавления, но запись в ответ по-прежнему блокируется (и выполняется в отдельном потоке). Сервлет 3.1 предоставляет API для неблокирующего ввода-вывода, но его использование будет держаться подальше от остального. API сервлетов, например, его спецификации являются синхронными (Filter, Servlet) или блокирующими (getParameter, getPart). WebFlux отличается от других: он опирается на неблокирующий ввод-вывод и не требует дополнительных потоков для каждой записи.
Reactiveпрограммирование&ReactorБиблиотека
Реактивное (реактивное программирование) относится к модели программирования, которая реагирует на изменения, например, сетевые компоненты, реагирующие на события ввода-вывода, контроллеры пользовательского интерфейса, реагирующие на события мыши, и т. д. Неблокирование является реактивным в том смысле, что мы сейчас находимся в режиме, в котором мы реагируем на результаты по мере завершения операции или по мере того, как данные становятся доступными.
Reactive Streams — это спецификация (также принятая в Java 9), определяющая взаимодействие между асинхронными компонентами с противодавлением. Например, репозиторий данных (выступающий в роли издателя) может генерировать данные (выполнять итерацию данных из базы данных), а затем HTTP-сервер (выступая в роли подписчика) может записывать итерированные данные в ответ на запрос. Затем скорость итерации данных. в базе данных зависит от Зависит от того, насколько быстро HTTP-сервер записывает объект ответа. Основная цель Reactive Streams — позволить подписчикам контролировать, насколько быстро издатель генерирует данные.
Кроме того, цель Reactive Streams — установить механизм противодействия и граничный предел. Если издатель не может снизить скорость собственного производства данных, он должен решить, следует ли кэшировать, терять или не сообщать об ошибке.
Реактивные потоки играют важную роль в совместимости. Он полезен для библиотек и компонентов инфраструктуры, но менее полезен в качестве API приложения, поскольку он слишком низкоуровневый. Приложениям требуется API более высокого уровня и более богатой функциональности для составления асинхронной логики — аналогично API Java 8 Stream, но не только для коллекций. Эту роль играет библиотека Reactive. Существующие библиотеки Reactor в Java включают Reactor и RxJava. Команда Spring считает, что Reactor является предпочтительной библиотекой Reactor для Spring WebFlux. Reactor предоставляет типы потоков API Mono и Flux, которые предоставляют богатые операторы, соответствующие словарю ReactiveX, обрабатывающие последовательности данных 0...1 (Mono) и 0...N (Flux). Reactor — это библиотека Reactive Streams, поэтому все ее операторы поддерживают неблокирующую функцию противодавления, и она была разработана в сотрудничестве со Spring.
WebFlux требует Reactor в качестве основной зависимости, но он может взаимодействовать с другими реактивными библиотеками (такими как RxJava) через Reactive Streams. Как правило, API WebFlux получает на входе простой Publisher, внутренне адаптирует его к типу Reactor, использует его и возвращает Flux или Mono на выходе. Таким образом, любой издатель может быть передан в качестве входных данных, а к выходным данным можно применить операторы, но выходные данные необходимо будет адаптировать для использования с другими типами реактивных библиотек, таких как RxJava. WebFlux прозрачно адаптируется к использованию RxJava или других реактивных библиотек, где это возможно (например, аннотированных контроллеров).
Сервер WebFlux
Spring WebFlux может работать в контейнерах Tomcat, Jetty, Servlet 3.1+ и контейнерах, не являющихся сервлетами, таких как Netty и Undertow. Все серверы работают с общим API низкого уровня, поэтому модели программирования более высокого уровня могут поддерживаться на всех серверах.
Spring WebFlux не имеет встроенных функций для запуска или остановки сервера, но приложения можно собрать с помощью конфигурации Spring и инфраструктуры WebFlux, а сервер можно запустить, написав несколько строк кода.
Spring Boot имеет стартер WebFlux (стартер), который можно запустить автоматически. Кроме того, по умолчанию стартер использует Netty в качестве сервера (на основе поддержки реактора-netty), который можно легко переключить на серверы Tomcat, Jetty или Undertow, изменив зависимости Maven или Gradle. Причина, по которой Spring Boot использует Netty в качестве сервера по умолчанию, заключается в том, что Netty широко используется в асинхронных и неблокирующих полях и позволяет клиентам и серверам совместно использовать ресурсы (например, совместное использование NioEventLoopGroup).
Контейнеры Tomcat и Jetty можно использовать с Spring MVC и WebFlux. Но имейте в виду, что они используются по-разному. Spring MVC опирается на блокировку ввода-вывода сервлетов и позволяет приложениям использовать API сервлетов напрямую, когда это необходимо. Spring WebFlux опирается на неблокирующий ввод-вывод Servlet 3.1 и использует API сервлетов за низкоуровневым адаптером, а не напрямую.
Когда Undertow выступает в качестве сервера, Spring WebFlux напрямую использует API Undertow вместо API сервлетов.
Так как же WebFlux обеспечивает плавное переключение между разными серверами? HttpHandler в WebFlux имеет простую спецификацию с одним методом обработки запросов и ответов:
public interface HttpHandler {
/**
* Handle the given request and write to the response.
* @param request current request
* @param response current response
* @return indicates completion of request handling
*/
Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response);
}Этот подход намеренно разработан так, чтобы быть минимальным. Его основная цель — обеспечить минимальную абстракцию для различных API-интерфейсов HTTP-сервера, и базовая инфраструктура WebFlux программируется на его основе, поэтому для адаптации к различным типам серверов требуется только добавить адаптер HttpHandler. Достаточно основных серверов и соответствующих адаптеров, как показано в таблице.

Например, при реализации сервера на базе Reactor Netty вы можете использовать следующий код для адаптации HttpHandler и запуска сервера:
HttpHandler handler = ...
ReactorHttpHandlerAdapter adapter = new ReactorHttpHandlerAdapter(handler);
HttpServer.create(host, port).newHandler(adapter).block();После запуска сервера Netty он будет отслеживать запрос клиента. Когда главный поток ввода-вывода получает запрос на завершение трехстороннего TCP-квитирования, он передает канал сокета соединения работнику. Поток ввода-вывода выполняет определенную обработку, и последний вызывает для обработки метод apply адаптера ReactorHttpHandlerAdapter, а затем адаптер пересылает запрос методу handle класса реализации HttpHandler HttpWebHandlerAdapter базового уровня для обработки, и запрос диспетчер будет вызываться внутри. Метод handle DispatcherHandler назначает запрос конкретному контроллеру для выполнения.
Например, при реализации сервера на базе Tomcat можно использовать следующий код для адаптации HttpHandler и запуска сервера:
HttpHandler handler = ...
Servlet servlet = new TomcatHttpHandlerAdapter(handler);
Tomcat server = new Tomcat();
File base = new File(System.getProperty("java.io.tmpdir"));
Context rootContext = server.addContext("", base.getAbsolutePath());
Tomcat.addServlet(rootContext, "main", servlet);
rootContext.addServletMappingDecoded("/", "main");
server.setHost(host);
server.setPort(port);
server.start();После запуска сервера Tomcat он будет отслеживать запрос клиента. Когда поток мониторинга запросов получает запрос на завершение трехстороннего подтверждения TCP, он передает запрос HTTP-процессору (например, Http11Processor) в контейнере Tomcat. обработка, а последний проведет запрос. После слоев контейнеров вызовите TomcatHttpHandlerAd Tomcat через цепочку фильтров. метод службы адаптера apter, а затем адаптер перенаправит запрос методу дескриптора класса реализации HttpHandler базового уровня HttpWebHandlerAdapter для внутренней обработки. Будет вызван метод дескриптора диспетчера запросов DispatcherHandler, чтобы назначить запрос определенному контроллеру. исполнение.
Ниже уровня HttpHandler, предоставляемого WebFlux, находится общая инфраструктура. Конкретному серверу верхнего уровня необходимо только создать собственный адаптер, чтобы легко использовать базовые функции WebFlux.
Модель параллелизма WebFlux
И Spring MVC, и Spring WebFlux поддерживают аннотированные контроллеры, но существуют ключевые различия в моделях параллелизма и предположениях о том, блокируются ли потоки.
В Spring MVC (и приложениях сервлетов в целом), предполагая, что приложение может блокировать текущий поток (например, вызов удаленной процедуры), контейнер сервлетов обычно использует большой пул потоков для решения потенциальных проблем блокировки во время запросов.
В Spring WebFlux (и неблокирующих серверах в целом, таких как Netty) предполагается, что приложение не блокируется, поэтому неблокирующий сервер использует небольшой пул потоков фиксированного размера (рабочие потоки ввода-вывода цикла событий) для обработки запросы.
Что, если мне действительно нужно использовать библиотеку блокировки? Reactor и RxJava предоставляют операторыPublishOn и ObserveOn соответственно для переключения последующих операций в потоке на другие потоки для обработки. Это означает, что в решении API блокировки есть простое адаптационное решение. Но имейте в виду, что блокирующие API не подходят для этой модели параллелизма.
В Reactor и RxJava логику можно объявлять с помощью операторов, и во время выполнения формируется реактивный поток, в котором данные обрабатываются последовательно на разных этапах. Основное преимущество этого подхода заключается в том, что данные в приложении сохраняются в потокобезопасном состоянии, поскольку код приложения в реактивном потоке никогда не может вызываться одновременно.
Влияние WebFlux на производительность
Реактивное и неблокирующее программирование обычно не ускоряет работу приложений, хотя в некоторых случаях может (например, использование WebClient для параллельного выполнения удаленных вызовов). Вместо этого выполнение этого неблокирующим способом требует больше дополнительной работы и может увеличить время, необходимое для обработки.
Ключевым преимуществом реактивности и неблокируемости является возможность добиться масштабируемости системы с использованием небольшого фиксированного количества потоков и меньшего объема памяти. Это делает приложения более устойчивыми под нагрузкой, поскольку они масштабируются более предсказуемо. Но чтобы получить эти преимущества, вам нужно заплатить некоторые затраты (например, непредсказуемый сетевой ввод-вывод).
Модель программирования WebFlux
Модуль Spring-Web содержит реактивную основу, на которой основан Spring WebFlux, включая абстракции HTTP, адаптеры реактивных потоков с поддержкой сервера, кодеки и основной эквивалент API сервлетов, но с API WebHandler неблокирующей спецификации.
Исходя из этого, Spring WebFlux предоставляет на выбор две модели программирования:
- Аннотированный контроллер: соответствует Spring MVC и основан на тех же аннотациях модуля Spring-Web. Контроллеры Spring MVC и WebFlux поддерживают реактивные типы возврата, поэтому отличить их непросто. Одним из заметных отличий является то, что WebFlux также поддерживает реактивные параметры @RequestBody.
- Функциональная конечная точка: основана на Lambda, облегченной и функциональной модели программирования. Думайте об этом как о небольшой библиотеке или наборе приложений, которые можно использовать для маршрутизации и обработки запросов. Самая большая разница с аннотированными контроллерами заключается в том, что приложение отвечает за обработку запроса от начала до конца, а не объявляется с помощью аннотаций и вызывается обратно.
Две представленные выше модели программирования различаются только стилем использования и в конечном итоге одинаковы при работе в реактивной базовой инфраструктуре. WebFlux требует базовой поддержки среды выполнения. Как упоминалось выше, WebFlux может работать в контейнерах Tomcat, Jetty, Servlet 3.1+ и контейнерах, не являющихся сервлетами (таких как Netty и Undertow).
Модель программирования аннотаций WebFlux
Ранее мы представили информацию о WebFlux. Давайте посмотрим, как использовать контроллеры аннотаций для использования WebFlux. Spring WebFlux предоставляет модель программирования на основе аннотаций, в которой компоненты @Controller и @RestController используют аннотации для выражения сопоставления запросов, ввода запроса, обработки исключений и т. д. Аннотированные контроллеры имеют гибкие сигнатуры методов и не должны наследовать базовый класс или реализовывать определенный интерфейс.
Давайте сначала познакомимся с моделью программирования аннотаций на простом примере:
@RestController
public class PersonHandler {
@GetMapping("/getPerson")
Mono<String> getPerson() {
return Mono.just("jiaduo");
}
}Как показано в приведенном выше коде, метод getPerson в классе контроллера PersonHandler предназначен для возврата имени. Здесь вместо простого возврата строки возвращается объект реактивного потока Mono. В Reactor каждый Mono содержит 0 или 1 элемент. Другими словами, разница между WebFlux и Spring MVC заключается в том, что он возвращает объекты Mono или Flux реактивного типа в библиотеке Reactor.
Что, если метод контроллера возвращает более одного элемента? В это время возвращаемое значение может быть установлено на тип Flux:
@RestController
public class PersonHandler {
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng");
}
}Как показано в приведенном выше коде, метод getPersonList возвращает объект потока Flux. В библиотеке Reactor каждый Flux представляет 0 или более объектов.
Следует отметить, что WebFlux по умолчанию работает на сервере Netty. В настоящее время модель потоков для обработки запросов в WebFlux показана на рисунке ниже.
[модель потока WebFlux]
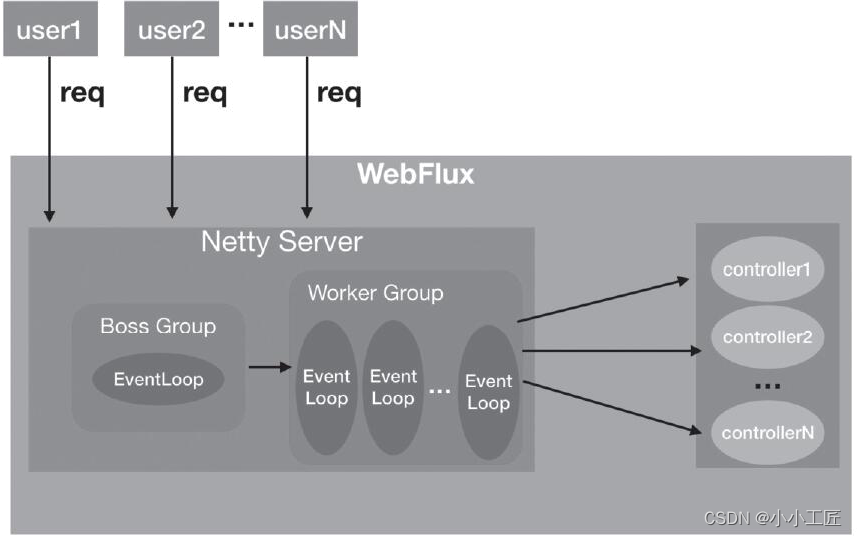
например,когда мы посещаемhttp://127.0.0.1:8080/getPersonListчас,WebFluxнижнийNettyServerизBoss Цикл событий в пуле потоков группы получит этот запрос, а затем передаст канал соединения, который завершает трехстороннее TCP-квитирование, работнику. Для обработки используется поток цикла событий в группе. Поток обработки событий вызовет для обработки соответствующий контроллер (здесь имеется в виду метод getPersonList PersonHandler для обработки), то есть контроллер выполняется с использованием потока ввода-вывода Netty. Если выполнение контроллера занимает много времени, поток ввода-вывода будет исчерпан и другие запросы больше не будут обрабатываться.
Вы можете изменить код до следующей формы, а затем посмотреть, является ли поток выполнения потоком NIO.
@RestController
public class PersonHandler {
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng").map(e -> {
System.out.println(Thread.currentThread().getName());
return e;
});
}После запуска службы на консоль будут выведены следующие результаты (обратите внимание, что номер потока «2» в nio-2 здесь случайный и может не равняться 2, когда он действительно запущен):
reactor-http-nio-2
reactor-http-nio-2
reactor-http-nio-2Как видно из вышеизложенного, контроллер выполняется в потоке ввода-вывода Netty.
Чтобы позволить потоку ввода-вывода освободиться вовремя, мы можем применить операцию публикацииOn к реактивному типу, чтобы переключить выполнение логики контроллера на другие потоки, чтобы поток ввода-вывода мог быть освобожден вовремя. Измените приведенный выше код, придав ему следующий вид:
@RestController
public class PersonHandler {
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng")
.publishOn(Schedulers.elastic())//1.1 Переключиться на асинхронное выполнение
.map(e -> {//1.2 Печать вызова нить
System.out.println(Thread.currentThread().getName());
return e;
});
}Как показано в приведенном выше коде 1.1, публикацияOn(Schedulers.elastic()) вызывается в потоке Flux, чтобы переключить последующую обработку элементов на пул потоков Schedulers.elastic(), после чего поток ввода-вывода Netty может быть освобожден вовремя. После запуска службы в это время консоль выведет (обратите внимание, что номер потока «2» в elastic-2 здесь случайный и может не равняться 2, когда он фактически запущен):
elastic-2
elastic-2
elastic-2Как видно из вышеизложенного, обработка элементов теперь использует потоки в эластичном пуле потоков вместо потоков Netty IO.
Кроме того, планировщик потоков Schedulers также предоставляет нам функцию формирования собственного пула потоков для выполнения асинхронных задач. Измените приведенный выше код, придав ему следующий вид:
@RestController
public class PersonHandler {
// 1.0 Создать пул нить
private static final ThreadPoolExecutor bizPoolExecutor = new ThreadPoolExecutor(8, 8, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>(10));
@GetMapping("/getPersonList")
Flux<String> getPersonList() {
return Flux.just("jiaduo", "zhailuxu", "guoheng")
.publishOn(Schedulers.fromExecutor(bizPoolExecutor))//1.1 Переключиться на асинхронное выполнение
.map(e -> {//1.2 Печать вызова нить
System.out.println(Thread.currentThread().getName());
return e;
});
}Как показано в приведенном выше коде 1.0, мы создаем собственный пул потоков, а затем используем Schedulers.fromExecutor(bizPoolExecutor) для преобразования нашего собственного пула потоков в планировщик, требуемый WebFlux, чтобы поток нашего собственного пула потоков использовался при обработке элементов. для обработки.
Модель функционального программирования WebFlux
Spring WebFlux включает облегченную модель функционального программирования, в которой функции используются для маршрутизации и обработки запросов, а ее спецификация разработана с учетом неизменности. Модель функционального программирования является альтернативой модели программирования на основе аннотаций, но обе они работают на одной и той же базовой библиотеке Reactive Core.
В модели функционального программирования WebFlux HandlerFunction используется для обработки HTTP-запросов. Функция Handler — это функция, которая получает ServerRequest и возвращает (задержанный) ServerResponse (т. е. Mono) результата отложенной записи. HandlerFunction эквивалентен телу метода, снабженному аннотацией @Request Mapping в модели программирования на основе аннотаций.
После того, как Сервер WebFlux получит запрос,Направит запрос в функцию-обработчик с помощью RouterFunction.,RouterFunction — это функция, которая получает ServerRequest и возвращает отложенную HandlerFunction (т. е. Mono). Когда функция маршрутизации совпадает,Возвращает функцию-обработчик; в противном случае возвращается пустой объект потока Mono. RouterFunction эквивалентен самой аннотации @RequestMapping.,Основное различие между ними заключается в,Функциональность маршрутизатора не только обеспечивает передачу данных,Поведение также предусмотрено.
Метод RouterFunctions.route() предоставляет построитель маршрутов, который упрощает создание правил маршрутизации, как показано в следующем коде:
@Configuration
public class FunctionModelConfig {
@Bean
public FunctionPersonHandler handler() {
return new FunctionPersonHandler();
}
@Bean
public RouterFunction<ServerResponse>routerFunction(final FunctionPersonHandler handler) {
RouterFunction<ServerResponse> route = RouterFunctions.route()//1
.GET("/getPersonF",RequestPredicates.accept(MediaType.APPLICATION_JSON), handler::getPerson)//2
.GET("/getPersonListF",RequestPredicates.accept(MediaType.APPLICATION_JSON), handler::getPersonList)//3
.build();//4
return route;
}
}public class FunctionPersonHandler {
// 1.0 Создать пул нить
private static final ThreadPoolExecutor bizPoolExecutor = new ThreadPoolExecutor(8, 8, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>(10));
Mono<ServerResponse> getPersonList(ServerRequest request) {
// 1. Найти список персон по запросу
Flux<String> personList = Flux.just("jiaduo", "zhailuxu", "guoheng")
.publishOn(Schedulers.fromExecutor(bizPoolExecutor))// 1.1 Переключиться на асинхронное выполнение
.map(e -> {// 1.2 Печать звонка
System.out.println(Thread.currentThread().getName());
return e;
});
// 2.Вернуть результаты поиска
return ServerResponse.ok().contentType(MediaType.APPLICATION_JSON).body(personList, String.class);
}
Mono<ServerResponse> getPerson(ServerRequest request) {
// 1. Найти человека по запросу,
Mono<String> person = Mono.just("jiaduo");
// 2.Вернуть результаты поиска
return ServerResponse.ok().contentType(MediaType.APPLICATION_JSON).body(person, String.class);
}
}Как показано в приведенном выше коде, FunctionPersonHandler создается для предоставления различных функций-обработчиков для обработки разных запросов. Здесь методы getPersonList(запрос ServerRequest) и getPerson(запрос ServerRequest) являются HandlerFunction.
Объект Mono создается в методе getPerson в качестве результата поиска, а затем вызывается ServerResponse.ok() для создания результата ответа, при этом для contentType ответа устанавливается значение JSON, а телом ответа является созданный объект person. Аналогичен методу getPersonList, за исключением того, что метод getPerson создает объект Flux в качестве содержимого тела ответа.
Метод routerFunction создает базовую логику RouterFunction, где код 1 создает Router. Объект-строитель функции; код 2 регистрирует маршрут для запроса GET, что означает, что когда пользователь обращается к запросу по пути /getPersonF, если заголовок принятия соответствует данным типа JSON, для обработки используется метод getPerson в классе FunctionPersonHandler. ; Код 3 регистрирует GET. Маршрут запроса метода означает, что когда пользователь обращается к запросу по пути /getPersonListF, если заголовок принятия соответствует данным типа JSON, для обработки используется метод getPersonList в классе Function-PersonHandler.
После локального запуска службы при доступе к http://127.0.0.1:8080/getPersonListF консоль службы выведет код, аналогичный следующему:
pool-2-thread-1
pool-2-thread-2
pool-2-thread-2Из вышесказанного видно, что метод контроллера выполняется асинхронно в бизнес-потоке, что соответствует логике выполнения программирования аннотаций.
Краткий обзор принципов WebFlux
Используя Netty в качестве сервера, мы объясним принцип реализации WebFlux.
Reactor NettyОбзор
Когда Netty выступает в качестве сервера, его базовый уровень основан на Reactor Netty для поддержки реактивной потоковой передачи. Reactor Netty предоставляет неблокирующие клиенты и серверы TCP/HTTP/UDP с противодавлением на основе платформы Netty. Reactor Netty, который в основном используется в WebFlux для создания HTTP-серверов, предоставляет простой в использовании и настройке класс HttpServer. Он скрывает большинство функций Netty, необходимых для создания HTTP-сервера, и добавляет противодавление Reactive Streams.
Если вы хотите использовать функции, предоставляемые библиотекой Reactor Netty, сначала необходимо добавить библиотеку в pom.xml с помощью следующего кода для импорта спецификации:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>Californium-RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Затем вам нужно как обычно добавить зависимость к соответствующему проекту реактора (тег версии не требуется). Следующий код показывает, как это сделать:
<dependencies>
<dependency>
<groupId>io.projectreactor.netty</groupId>
<artifactId>reactor-netty</artifactId>
</dependency>
</dependencies>Чтобы запустить HTTP-сервер, необходимо создать и настроить экземпляр HttpServer. По умолчанию хост настроен как любой локальный адрес, и система может выбрать временный порт при вызове операции привязки. В следующем примере показано, как создать экземпляр HttpServer:
import reactor.core.publisher.Mono;
import reactor.netty.DisposableServer;
import reactor.netty.http.server.HttpServer;
public class ReactorNetty {
public static void main(String[] args) {
DisposableServer server = HttpServer.create()//Создать http-сервер.
.host("localhost")//2.Установить хост
.port(8080)//3.Установите порт прослушивания
.route(routes -> маршруты //4.Установить правила маршрутизации
.get("/hello", (request, response) -> response.sendString(Mono.just("Hello World!")))
.post("/echo", (request, response) -> response.send(request.receive().retain()))
.get("/path/{param}",
(request, response) -> response.sendString(Mono.just(request.param("param"))))
.ws("/ws", (wsInbound, wsOutbound) -> wsOutbound.send(wsInbound.receive().retain())))
.bindNow();
server.onDispose().block();//5. Запустите сервер в режиме блокировки и дождитесь синхронной остановки службы.
}
}Это видно из приведенного выше кода:
- Код 1 создает HttpServer для настройки.
- Код 2 настраивает хост службы HTTP.
- Код 3 настраивает номер порта прослушивания службы HTTP.
·Код 4 настраивает маршрут службы HTTP, предоставляет запрос GET для пути доступа /hello и возвращает «Hello World!», предоставляет запрос POST для пути доступа /echo и возвращает полученное тело запроса в качестве ответа; путь доступа /path/ {param} Предоставляет запрос GET и возвращает значение параметра пути, предоставляет веб-сокет в /ws и возвращает полученные входящие данные в качестве исходящих данных.
·Код 5 вызывает метод onDispose() DisposableServer, возвращенный кодом 1, и ожидает выключения сервера в блокирующем режиме.
Запустите приведенный выше код и введите http://127.0.0.1:8080/hello в браузере. Если на странице отображается «Hello World!», это означает, что наш HTTP-сервер вступил в силу.
Процесс запуска сервера WebFlux
Давайте объясним процесс запуска службы WebFlux на основе процесса запуска SpringBoot. Сначала давайте посмотрим на диаграмму последовательности запуска.
[Схема последовательности запуска службы WebFlux]
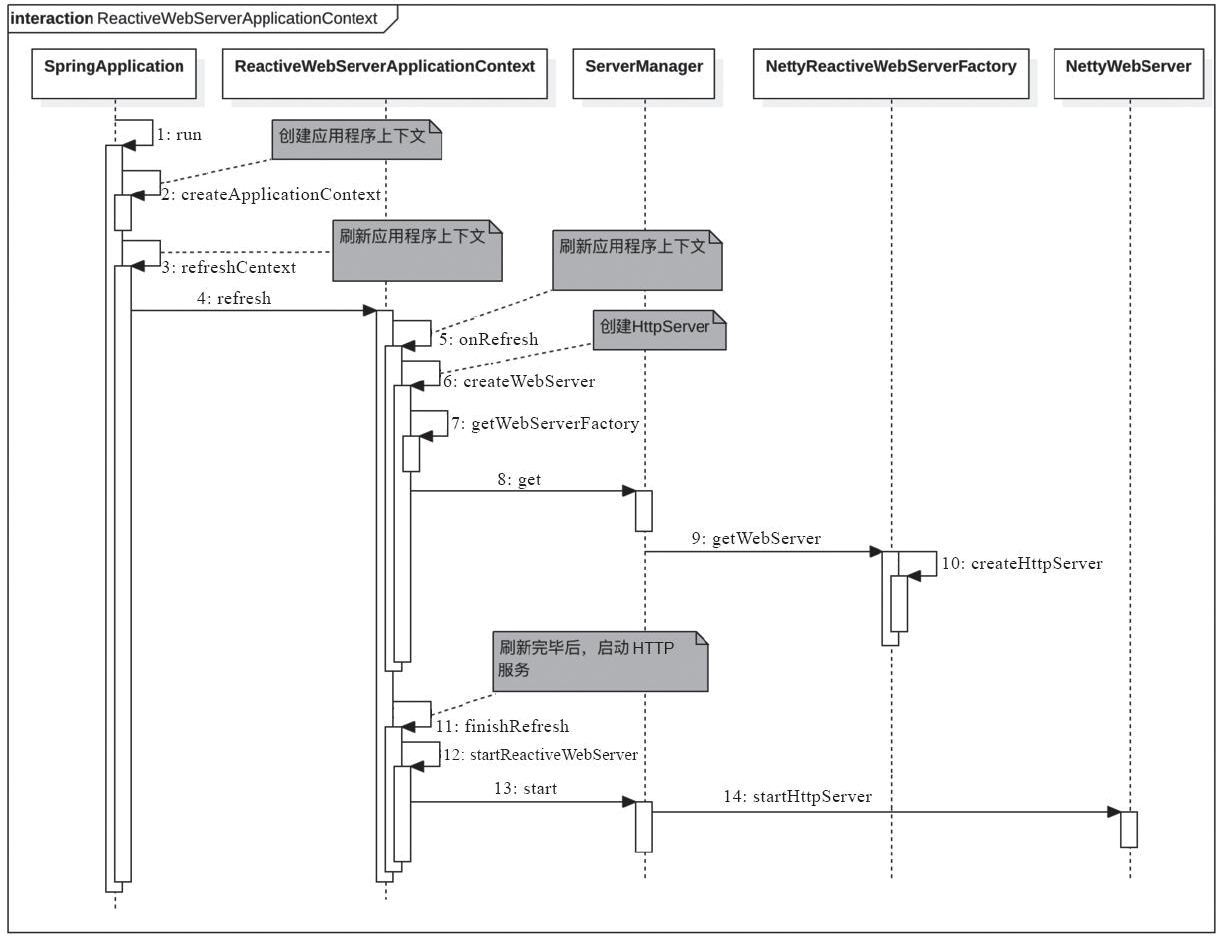
Шаг 1 на рисунке создает контекст приложения AnnotationConfigReactiveWebServerApplicationContext через createApplicationContext. Код выглядит следующим образом.
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
//a тип среды
switch (this.webApplicationType) {
case SERVLET://a.1 Web среда сервлета
contextClass = Class.forName(DEFAULT_SERVLET_WEB_CONTEXT_CLASS);
break;
case REACTIVE://a.2 Web Реактивная среда
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default://a.3 Не веб-среда
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, "
+ "please specify an ApplicationContextClass",
ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}
//По умолчанию Нет веб-средачас
public static final String DEFAULT_CONTEXT_CLASS = "org.springframework.context."
+ "annotation.AnnotationConfigApplicationContext";
//web Среда сервлетов является контекстом по умолчанию.
public static final String DEFAULT_SERVLET_WEB_CONTEXT_CLASS = "org.springframework.boot."
+ "web.servlet.context.AnnotationConfigServletWebServerApplicationContext";
//Контекст по умолчанию в реактивной веб-среде
public static final String DEFAULT_REACTIVE_WEB_CONTEXT_CLASS = "org.springframework."
+ "boot.web.reactive.context.AnnotationConfigReactiveWebServerApplicationContext";Как показано в приведенном выше коде, при создании контекста приложения-контейнера необходимо создавать разные контексты приложения в зависимости от типа среды. Здесь мы используем реактивную веб-среду, поэтому созданный контекст приложения является экземпляром AnnotationConfigReactiveWebServerApplicationContext.
Так как же определяется тип среды webApplicationType? Фактически, оно определяется внутри конструктора, создающего SpringApplication:
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {
...
this.webApplicationType = WebApplicationType.deduceFromClasspath();
...
}
Далее мы рассмотрим метод deducFromClasspath WebApplicationType:
static WebApplicationType deduceFromClasspath() {
//b. Определить, является ли это РЕАКТИВНЫМ типом.
if (ClassUtils.isPresent(WEBFLUX_INDICATOR_CLASS, null)
&& !ClassUtils.isPresent(WEBMVC_INDICATOR_CLASS, null)
&& !ClassUtils.isPresent(JERSEY_INDICATOR_CLASS, null)) {
return WebApplicationType.REACTIVE;
}
//c. Определить, является ли это типом, не относящимся к Интернету.
for (String className : SERVLET_INDICATOR_CLASSES) {
if (!ClassUtils.isPresent(className, null)) {
return WebApplicationType.NONE;
}
}
//Среда сервлетов
return WebApplicationType.SERVLET;
}
//spring mvc Диспетчер
private static final String WEBMVC_INDICATOR_CLASS = "org.springframework."
+ " web.servlet.DispatcherServlet";
// reactive webДиспетчер
private static final String WEBFLUX_INDICATOR_CLASS = "org."
+ "springframework.web.reactive.DispatcherHandler";
//Jersey Web Класс контейнера проекта
private static final String JERSEY_INDICATOR_CLASS = "org.glassfish.jersey.servlet.ServletContainer";
//Классы, необходимые контейнеру сервлетов
private static final String[] SERVLET_INDICATOR_CLASSES = { "javax.servlet.Servlet",
"org.springframework.web.context.ConfigurableWebApplicationContext" };Как показано в приведенном выше коде, метод deduceFromClasspath определяет текущую среду на основе того, существует ли соответствующий файл байт-кода класса в пути к классам.
Давайте посмотрим, как шаг 3 на рисунке создает и запускает HTTP-сервер. На этапе onRefresh обновления контекста Spring метод createWebServer вызывается для создания веб-сервера, а метод getWebServerFactory вызывается внутренне для получения фабрики веб-сервера. Код getWebServerFactory выглядит следующим образом:
protected ReactiveWebServerFactory getWebServerFactory() {
//d Получите имена всех экземпляров bean-компонентов типа ReactiveWebServerFactory из bean-фабрики.
String[] beanNames = getBeanFactory()
.getBeanNamesForType(ReactiveWebServerFactory.class);
//e Выдает исключение, если оно не существует
if (beanNames.length == 0) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to missing "
+ "ReactiveWebServerFactory bean.");
}
if (beanNames.length > 1) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to multiple "
+ "ReactiveWebServerFactory beans : "
+ StringUtils.arrayToCommaDelimitedString(beanNames));
}
//f Если существует, получить первый экземпляр
return getBeanFactory().getBean(beanNames[0], ReactiveWebServerFactory.class);
}Как показано в приведенном выше коде, получите экземпляр ReactiveWebServerFactory из фабрики компонентов, соответствующий контексту приложения, чтобы позже создать веб-сервер. Итак, когда экземпляр класса реализации ReactiveWebServerFactory вводится в контекстный контейнер? Фактически, это делается с помощью механизма автоконфигурации Springboot. Механизм автоконфигурации автоматически внедрит в контейнер класс реализации ReactiveWebServerFactory NettyReactiveWebServer Factory.
Конкретный класс реализации ReactiveWebServerFactory, который необходимо внедрить, создается ReactiveWebServerFactoryConfiguration на основе механизма автоконфигурации. Код выглядит следующим образом:
class ReactiveWebServerFactoryConfiguration {
//f.1 Внедрить NettyReactiveWebServerFactory в контейнер
@Configuration
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ HttpServer.class })
static class EmbeddedNetty {
@Bean
public NettyReactiveWebServerFactory nettyReactiveWebServerFactory() {
return new NettyReactiveWebServerFactory();
}
}
//f.2 Внедрить экземпляр TomcatReactiveWebServerFactory
@Configuration
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ org.apache.catalina.startup.Tomcat.class })
static class EmbeddedTomcat {
@Bean
public TomcatReactiveWebServerFactory tomcatReactiveWebServerFactory() {
return new TomcatReactiveWebServerFactory();
}
}
//f.3 Внедрить экземпляр JettyReactiveWebServerFactory
@Configuration
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ org.eclipse.jetty.server.Server.class })
static class EmbeddedJetty {
@Bean
public JettyReactiveWebServerFactory jettyReactiveWebServerFactory() {
return new JettyReactiveWebServerFactory();
}
}
//f.4 Внедрить экземпляр UndertowReactiveWebServerFactory
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ Undertow.class })
static class EmbeddedUndertow {
@Bean
public UndertowReactiveWebServerFactory undertowReactiveWebServerFactory() {
return new UndertowReactiveWebServerFactory();
}
}
}Например, в коде f.1, если в текущем контексте контейнера нет экземпляра ReactiveWebServerFactory, а файл класса HttpServer существует в пути к классам, это означает, что текущая среда является реактивной средой, а NettyReactiveWebServerFactory внедряется в контейнер.
Например, код f.2: если в текущем контексте контейнера нет экземпляра ReactiveWebServerFactory, а файл класса org.apache.catalina.startup.Tomcat существует в пути к классам, это означает, что текущая среда является средой сервлетов, а контейнером сервлетов является Tomcat, то в контейнер вводится экземпляр TomcatReactiveWebServerFactory.
После нахождения соответствующего экземпляра фабрики ReactiveWebServerFactory, как показано на рисунке, на шаге 8 создается экземпляр ServerManager, код выглядит следующим образом:
public static ServerManager get(ReactiveWebServerFactory factory) {
return new ServerManager(factory);
}Конструктор ServerManager выглядит следующим образом:
private ServerManager(ReactiveWebServerFactory factory) {
this.handler = this::handleUninitialized;
this.server = factory.getWebServer(this);
}Как видно из вышеизложенного, метод getWebServer NettyReactiveWebServerFactory вызывается для создания веб-сервера. Код выглядит следующим образом:
public WebServer getWebServer(HttpHandler httpHandler) {
//I
HttpServer httpServer = createHttpServer();
//II
ReactorHttpHandlerAdapter handlerAdapter = new ReactorHttpHandlerAdapter(
httpHandler);
//III
return new NettyWebServer(httpServer, handlerAdapter, this.lifecycleTimeout);
}Как показано в приведенном выше коде, он создает HTTPServer с помощью createHttpServer, и его код выглядит следующим образом (HTTP-сервер создается с использованием API реактора Netty):
private HttpServer createHttpServer() {
return HttpServer.builder().options((options) -> {
options.listenAddress(getListenAddress());
if (getSsl() != null && getSsl().isEnabled()) {
SslServerCustomizer sslServerCustomizer = new SslServerCustomizer(
getSsl(), getSslStoreProvider());
sslServerCustomizer.customize(options);
}
if (getCompression() != null && getCompression().getEnabled()) {
CompressionCustomizer compressionCustomizer = new CompressionCustomizer(
getCompression());
compressionCustomizer.customize(options);
}
applyCustomizers(options);
}).build();
}Код II создает класс адаптера ReactorHttpHandlerAdapter, соответствующий Netty.
Код III создает экземпляр NettyWebServer, который обертывает экземпляры адаптера и HTTPserver.
На этом этапе мы закончили объяснять, как создать HTTPServer.
Далее мы рассмотрим, как запустить службу на шаге 11, показанном на рисунке 7-3. На этапе FinishRefresh обновления контекста приложения вызывается метод startReactiveWebServer для запуска службы. Код выглядит следующим образом:
private WebServer startReactiveWebServer() {
ServerManager serverManager = this.serverManager;
ServerManager.start(serverManager, this::getHttpHandler);
return ServerManager.getWebServer(serverManager);
}Как показано в приведенном выше коде, сначала вызывается getHttpHandler для получения процессора:
protected HttpHandler getHttpHandler() {
// Use bean names so that we don't consider the hierarchy
String[] beanNames = getBeanFactory().getBeanNamesForType(HttpHandler.class);
if (beanNames.length == 0) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to missing HttpHandler bean.");
}
if (beanNames.length > 1) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to multiple HttpHandler beans : "
+ StringUtils.arrayToCommaDelimitedString(beanNames));
}
return getBeanFactory().getBean(beanNames[0], HttpHandler.class);
}Как показано в приведенном выше коде, получается класс реализации HttpHandler в контексте приложения, здесь это HttpWebHandlerAdapter. Затем вызовите ServerManager.start, чтобы запустить службу. Код выглядит следующим образом:
public static void start(ServerManager manager,
Supplier<HttpHandler> handlerSupplier) {
if (manager != null && manager.server != null) {
manager.handler = handlerSupplier.get();//Выполняем метод getHttpHandler
Manager.server.start();//Запускаем службу
}
}Как показано в приведенном выше коде, сначала сохраните экземпляр HttpWebHandlerAdapter внутри ServerManager, а затем запустите сервер NettyWebServer в ServerManager. Код метода запуска NettyWebServer выглядит следующим образом:
public void start() throws WebServerException {
//IV специально запускает службу
if (this.nettyContext == null) {
try {
this.nettyContext = startHttpServer();
}
...
//Включаем деамоннит синхронизацию и ждем завершения обслуживания
NettyWebServer.logger.info("Netty started on port(s): " + getPort());
startDaemonAwaitThread(this.nettyContext);
}
}
private BlockingNettyContext startHttpServer() {
if (this.lifecycleTimeout != null) {
return this.httpServer.start(this.handlerAdapter, this.lifecycleTimeout);
}
return this.httpServer.start(this.handlerAdapter);
}Как показано в коде IV выше, он вызывает startHttpServer для запуска службы, затем возвращает объект BlockingNetty Context, а затем вызывает startDaemonAwaitThread, чтобы запустить поток демона для синхронизации и ожидания завершения службы. Код выглядит следующим образом:
private void startDaemonAwaitThread(BlockingNettyContext nettyContext) {
//запускатьнить Thread awaitThread = new Thread("server") {
@Override
public void run() {
//Сервис синхронной блокировки останавливается
nettyContext.getContext().onClose().block();
}
};
//Устанавливаем значение демаона и запускаем
awaitThread.setContextClassLoader(getClass().getClassLoader());
awaitThread.setDaemon(false);
awaitThread.start();
}Причина, по которой здесь открывается поток для асинхронного ожидания завершения службы, заключается в том, что это не блокирует вызывающий поток. Если вызывающий поток заблокирован, все приложение SpringBoot не запустится.
Процесс вызова службы WebFlux
Ранее мы говорили о процессе запуска службы WebFlux. В этом разделе мы объясняем процесс вызова службы на примере процесса вызова метода getPerson в контроллере PersonHandler.
Когда мы печатаем в браузереhttp://127.0.0.1:8080/getPersonчас,Инициирует запрос к Nettyсерверу в WebFlux.,Слушатель Boss в сервернице получит запрос.,И после завершения трехстороннего рукопожатия TCP,Зарегистрируйте канал сокета подключения в NioEventLoop в рабочем пуле для обработки.,Затем соответствующий нит в NioEventLoop будет опрашивать события чтения и записи в сокете и обрабатывать их. Давайте посмотрим на его временную диаграмму ниже.,Как показано ниже.
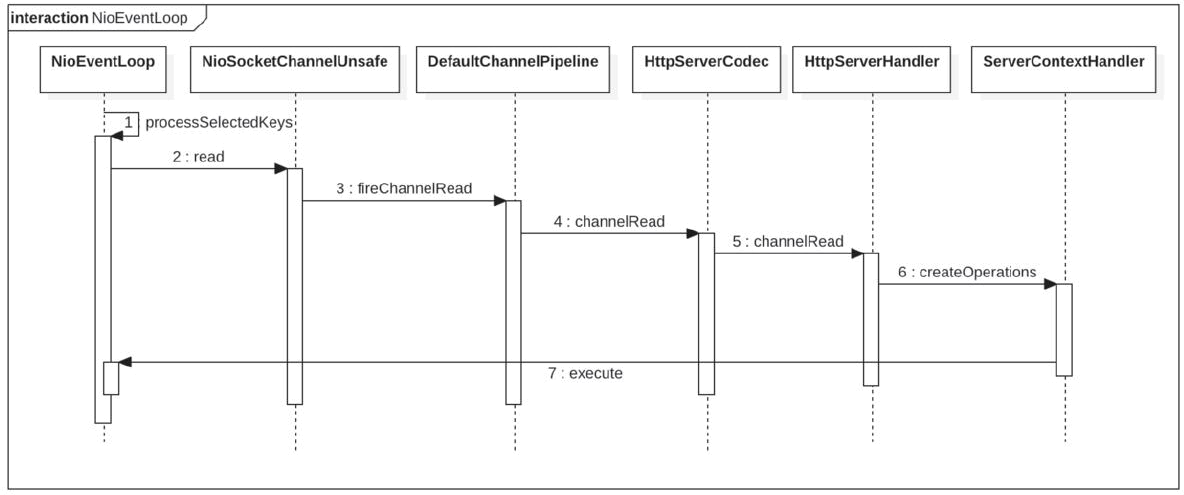
【Процесс вызова службы WebFlux】
Как показано на рисунке, когда сокет подключения, зарегистрированный в NioEventLoop пула рабочих потоков, имеет событие чтения, для обработки будет вызван методprocessSelectedKeys, а затем прочитанные данные будут переданы зарегистрированному событию через конвейер, соответствующий канал, процессор DefaultChannelPipeline для обработки. Процессор HttpServerCodec здесь отвечает за анализ двоичного потока в сообщение HTTP-запроса, а затем передачу его процессору HttpServerHandler за конвейером. HttpServerHandler вызывает createOperation ServerContextHandler. s, отправьте метод onHandlerStart ChannelOperations в качестве задачи в очередь, управляемую NioEventLoop, соответствующую текущему каналу, с помощью кода «channel.eventLoop().execute(op::onHandlerStart);». Давайте посмотрим, как поток в NioEventLoop выполняет эту задачу. Код onHandlerStart выглядит следующим образом:
protected void onHandlerStart() {
applyHandler();
}
protected final void applyHandler() {
try {
//1. Вызов метода Apply адаптера ReactorHttpHandlerAdapter.
Mono.fromDirect(handler.apply((INBOUND) this, (OUTBOUND) this))
.subscribe(this);
}
catch (Throwable t) {
channel.close();
}
}Как показано в приведенном выше коде 1, метод apply адаптера ReactorHttpHandlerAdapter вызывается для конкретной обработки запроса. Код выглядит следующим образом:
public Mono<Void> apply(HttpServerRequest request, HttpServerResponse response) {
ServerHttpRequest adaptedRequest;
ServerHttpResponse adaptedResponse;
try {
//2. Создаем объекты запроса и ответа, соответствующие реактору.
adaptedRequest = new ReactorServerHttpRequest(request, BUFFER_FACTORY);
adaptedResponse = new ReactorServerHttpResponse(response, BUFFER_FACTORY);
}
catch (URISyntaxException ex) {
...
response.status(HttpResponseStatus.BAD_REQUEST);
return Mono.empty();
}
...
//3. Здесь httpHandler — это ServerManager.
return this.httpHandler.handle(adaptedRequest, adaptedResponse)
.doOnError(ex -> logger.warn("Handling completed with error: " + ex.getMessage()))
.doOnSuccess(aVoid -> logger.debug("Handling completed with success"));
}Затем мы посмотрим на метод дескриптора ServerManager, показанный в коде 3:
public Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response) {
//4.Обработчик здесь — HttpWebHandlerAdapter
return this.handler.handle(request, response);
}
Затем вызовите метод дескриптора HttpWebHandlerAdapter, код выглядит следующим образом:
public Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response) {
//5. Создаем объект обмена услугами.
ServerWebExchange exchange = createExchange(request, response);
//6.Здесь getDelegate() — это DispatcherHandler
return getDelegate().handle(exchange)
.onErrorResume(ex -> handleFailure(request, response, ex))
.then(Mono.defer(response::setComplete));
}
protected ServerWebExchange createExchange(ServerHttpRequest request, ServerHttpResponse response) {
return new DefaultServerWebExchange(request, response, this.sessionManager,
getCodecConfigurer(), getLocaleContextResolver(), this.applicationContext);
}Наконец, вызовите метод handle диспетчера DispatcherHandler для маршрутизации:
public Mono<Void> handle(ServerWebExchange exchange) {
...
if (this.handlerMappings == null) {
return Mono.error(HANDLER_NOT_FOUND_EXCEPTION);
}
//7. Находим соответствующий контроллер для обработки.
return Flux.fromIterable(this.handlerMappings)//7.1 Получить все сопоставления процессоров
.concatMap(mapping -> Mapping.getHandler(exchange))//7.2 Преобразование отображения и получение процессора
.next()//7.3 Получить первый элемент
.switchIfEmpty(Mono.error(HANDLER_NOT_FOUND_EXCEPTION))//7.4 не существует процессора
.flatMap(handler -> invokeHandler(exchange, обработчик))//7.5 Использовать процессор для обработки
.flatMap(result -> handleResult(exchange, result));//7.6 Обработка результатов обработки процессором
}Приведенный выше код использует все сопоставления процессоров запросов в качестве источника данных потока Flux для поиска процессора, соответствующего указанному запросу.
Если он не найден, используйте Mono.error(HANDLER_NOT_FOUND_EXCEPTION), чтобы создать сообщение об ошибке в качестве элемента;
Если он найден, вызовите метод ignoreHandler для обработки. После обработки вызовите handleResult для обработки результата. Здесь мы находим процессор PersonHandler, соответствующий getPerson, затем метод getPerson PersonHandler будет рефлексивно вызываться в InvokeHandler для выполнения, а затем результат будет передан в handleResult и записан обратно в объект ответа.
Применимые сценарии WebFlux
Поскольку WebFlux был запущен в Spring 5, следует ли нам использовать Spring MVC или WebFlux при выполнении проектов?
Это вопрос, который естественно приходит на ум, но он неразумен. Поскольку существование этих двух систем не противоречит, их использование расширяет диапазон возможностей, доступных нам при разработке. Оба созданы для обеспечения непрерывности и последовательности, и их можно использовать параллельно, получая обратную связь от каждого из них, принося пользу обоим. На диаграмме ниже показаны взаимосвязи между ними, их общие черты и соответствующие характеристики.
[Сравнение WebFlux и сервлета]
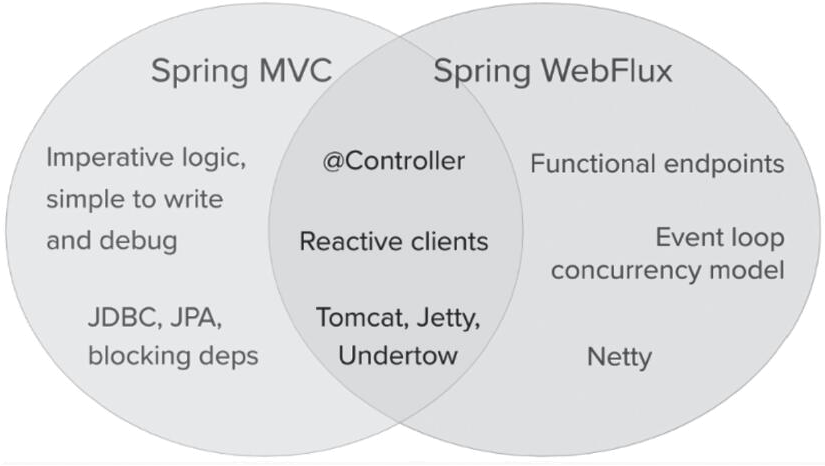
предположение
При выборе весны MVC или WebFlux официальный документ Spring5 дает несколько предположений:
- Если ваше приложение Spring MVC работает нормально, никаких изменений не требуется. Императивное программирование — это самый простой способ писать, понимать и отлаживать код.
- Если вы уже используете неблокирующий веб-стек, вы можете рассмотреть возможность использования WebFlux. Потому что весна WebFlux предлагает те же преимущества модели выполнения с выбором доступных опций (Netty, Tomcat, Jetty, Undertow и Servlet). 3.1+), также предоставляет дополнительные модели программирования (аннотированные контроллеры и функциональные конечные веб-точки) и дополнительные реактивные библиотеки (Reactor, RxJava и другие).
- Если вас интересует легкая функциональная веб-инфраструктура для использования с Java 8 Lambdas или Kotlin, вы можете использовать функциональные конечные веб-точки Spring WebFlux. Это также хороший вариант для небольших приложений или микросервисов с менее сложными требованиями, позволяющий получить выгоду от большей прозрачности и контроля.
- В архитектуре микросервисов вы можете смешивать приложения с контроллерами Spring MVC, Spring WebFlux и функциональными конечными точками Spring WebFlux. Поддержка одной и той же модели программирования на основе аннотаций в обеих средах упрощает повторное использование знаний при выборе правильного инструмента для правильной работы.
- Простой способ оценить приложение — проверить его зависимости. Если вы собираетесь использовать API персистентности блокировки (JPA, JDBC) или сетевой API, Spring MVC — по крайней мере лучший выбор для распространенных архитектур. Технически и Reactor, и RxJava могут выполнять блокирующие вызовы на отдельном нит, но вы не можете в полной мере воспользоваться преимуществами стека неблокирующих веб-технологий.
- Если у вас есть приложение Spring MVC, которое вызывает удаленную службу, вы можете попробовать использовать реактивный WebClient. Вы можете возвращать реактивные типы (Reactor, RxJava или другие) непосредственно из методов контроллера Spring MVC. Чем больше задержка каждого вызова или взаимозависимость между вызовами, тем больше выгода. Контроллеры Spring MVC также могут вызывать другие реактивные компоненты.
краткое содержание
Новый асинхронный неблокирующий стек технологий WebFlux, представленный в Spring 5.0, существует параллельно со стеком технологий Servlet. WebFlux поддерживает асинхронную обработку из спецификации, естественным образом поддерживает реактивное программирование на основе библиотеки Reactor и использует небольшое количество фиксированных потоков для достижения масштабируемости системы.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
