Архитектура Greenplum MPP
1. Архитектура Greenplum MPP
Greenplum (далее — GPDB) — хранилище данных с открытым исходным кодом. Основанный на преобразовании PostgreSQL с открытым исходным кодом, он в основном используется для решения крупномасштабных задач анализа данных. По сравнению с Hadoop, Greenplum больше подходит для хранения больших данных, вычислений и анализа.
GPDB — это типичная архитектура «главный/подчиненный». В кластере Greenplum есть главный узел и несколько узлов сегмента, и на каждом узле может работать несколько баз данных. Greenplum использует архитектуру без общего доступа (MPP). Типичная система Shared Nothing собирает базы данных, кэши памяти и т. д. для хранения информации о состоянии; она не сохраняет информацию о состоянии на узлах; Информационное взаимодействие между узлами реализуется через сеть межузловых связей. Распределяя данные по нескольким узлам, достигается крупномасштабное хранение данных, а производительность запросов повышается за счет параллельной обработки запросов. Каждый узел запрашивает только свои собственные данные. Полученные результаты затем обрабатываются главным узлом для получения окончательного результата. Линейное расширение системы достигается за счет увеличения количества узлов.

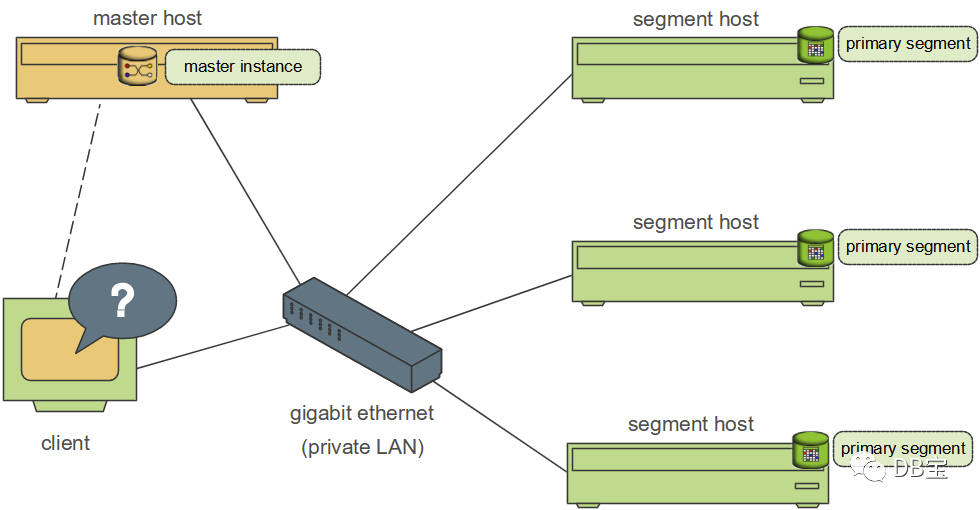
На рисунке выше показана базовая архитектура GPDB. Клиент подключается к gpdb через сеть. Главный узел — это основной узел GP (точка доступа клиента), а узел сегмента — подузел (интерфейс для подключения). и отправка операторов SQL), а главный узел — если пользовательские данные не сохраняются, дочерние узлы хранят данные и отвечают за запросы SQL. Главный узел отвечает за ответ на запросы клиента и преобразование запрошенных операторов SQL. После преобразования. он планирует запрос фоновых дочерних узлов и возвращает результаты запроса клиенту.
1.1.Greenplum Master
Мастер хранит только системные метаданные, а все бизнес-данные распределяются по сегментам. Являясь входом во всю систему базы данных, он отвечает за установление соединения с клиентом, разбор SQL и формирование плана выполнения, распределение задач по экземплярам Сегмента и сбор результатов выполнения Сегмента. Именно потому, что Мастер не отвечает за расчеты, Мастер не станет узким местом системы.

Высокая доступность главного узла аналогична Hadoop NameNode HA. Резервный мастер поддерживает согласованность с каталогом и журналом транзакций Первичного мастера в процессе синхронизации. В случае сбоя Первичного мастера резервный мастер берет на себя всю работу Мастера.
1.2.Segment
В Greenplum может быть несколько сегментов. Сегменты в основном отвечают за хранение и доступ к бизнес-данным, а также выполнение пользовательских запросов. Каждый сегмент хранит часть пользовательских данных, но пользователи не могут напрямую обращаться к сегментам. Весь доступ к сегментам должен осуществляться. через Мастера. При доступе к данным все сегменты сначала параллельно обрабатывают свои собственные данные. Если данные других сегментов необходимо связать и обработать, сегменты могут передавать данные через межсоединение. Чем больше узлов Segment, тем более разбросанными будут данные и тем выше будет скорость обработки. Поэтому, в отличие от кластеров баз данных Share All, при увеличении количества серверов узлов сегмента производительность Greenplum будет увеличиваться линейно.
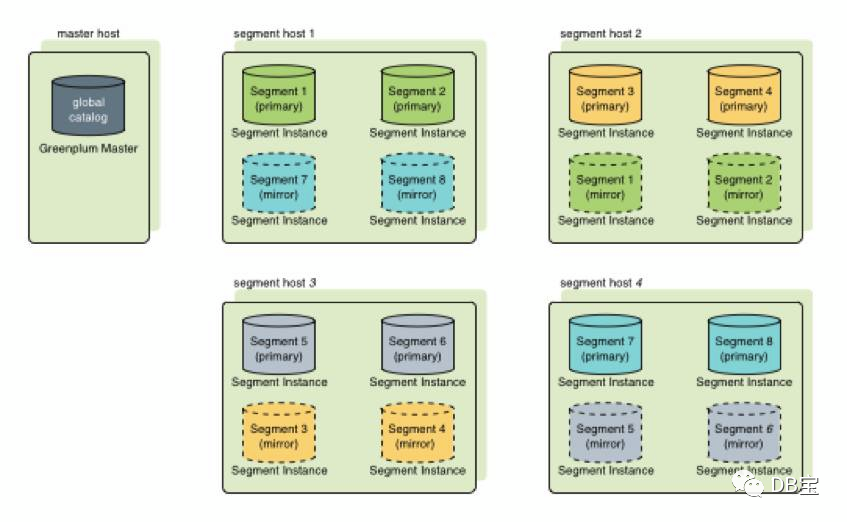
Данные каждого сегмента избыточно сохраняются в другом сегменте, и данные синхронизируются в режиме реального времени. При выходе из строя основного сегмента зеркальный сегмент автоматически предоставляет услуги. Когда основной сегмент возвращается в нормальное состояние, вы можете легко использовать «gprecoverseg». Инструмент -F» для синхронизации данных.
1.3.Interconnect
Interconnect — это сетевой уровень в архитектуре Greenplum и основной компонент системы GPDB. По умолчанию используется протокол UDP, но Greenplum будет проверять пакеты данных, поэтому надежность эквивалентна TCP, но производительность будет выше. При использовании протокола TCP количество экземпляров сегмента не может превышать 1000, но при использовании UDP такого ограничения нет.
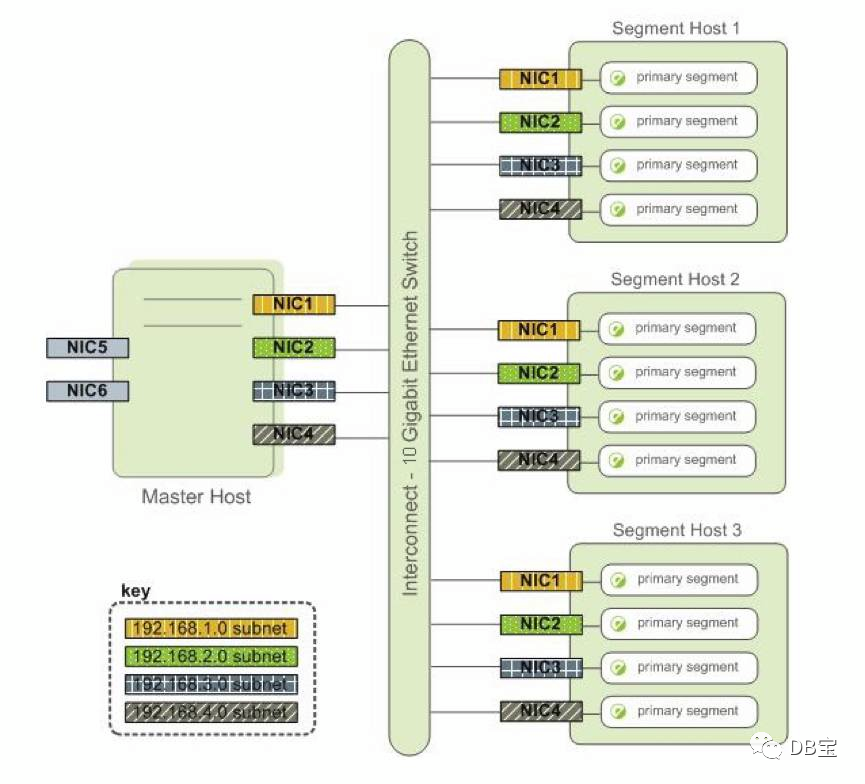
2. Конфигурация кластера

Главный хост — X4200, а резервный главный хост — X4500. Используйте сетевые порты e1000g4 и e1000g5 для создания локальной сети для предоставления внешних услуг.
Хост сегмента 1 — X4500, а резервный хост 2 — X4500. Используйте сетевые порты e1000g1, e1000g2, e1000g3 и e1000g4 для установки сетевых каналов в разных сетях VLAN, чтобы обеспечить создание нескольких сегментов на одном хосте.
Каждый хост использует ilom для подключения к частной сети для управления хостом сервера.
2.1.Архитектура высокой доступности Greenplum
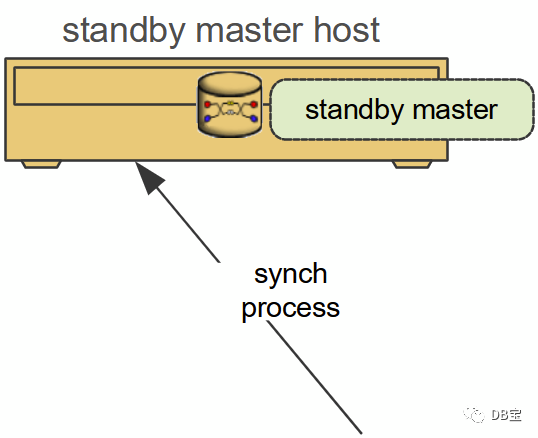
Главный узел и резервный узел используют процесс синхронизации для обеспечения согласованности строк главной и резервной баз данных. Сегментация узла данных имеет mirrio (обычно хранится на ближайшем сервере).
2.2.Защита главного/резервного зеркала

Резервный узел используется для предоставления главных услуг в случае повреждения главного узла. Резервный режим синхронизируется с каталогом главного узла и журналом транзакций в режиме реального времени.

В кластере высокой доступности есть два главных экземпляра: основной и резервный. Как и сегменты, главный и резервный должны быть развернуты на разных хостах, чтобы гарантировать, что кластер не пострадает от сбоя одного узла. Клиенты могут подключаться только к основному мастеру и выполнять к нему запросы. Резервный главный сервер использует потоковую репликацию журнала упреждающей записи (WAL) для обеспечения согласованности данных с основным главным устройством.
Если главный мастер выходит из строя, администратор может переключить резервный главный мастер, чтобы он стал новым основным мастером, запустив инструмент gpactivatestandby. Вы можете настроить виртуальный IP-адрес на главном и резервном устройствах, чтобы при переключении клиенту не приходилось переключаться между разными URL-адресами. В случае сбоя главного хоста виртуальный IP-адрес может перейти к новому активному главному узлу, чтобы продолжить предоставление услуг.
Использование услуги главного зеркала:
- Создайте резервный главный хост
- выключатель
- Активировать мастер
2.3. Избыточность данных – зеркальная защита сегментов.
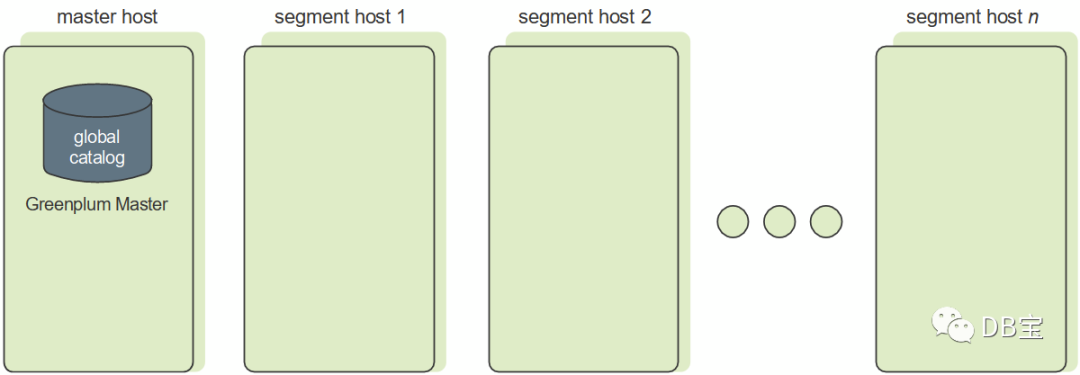
Данные каждого сегмента избыточно сохраняются в другом сегменте и синхронизируются в реальном времени. В случае сбоя основного сегмента зеркальный сегмент автоматически предоставит услуги. После того, как основной сегмент вернется в нормальное состояние, используйте «gprecoverseg –F» для синхронизации данных.
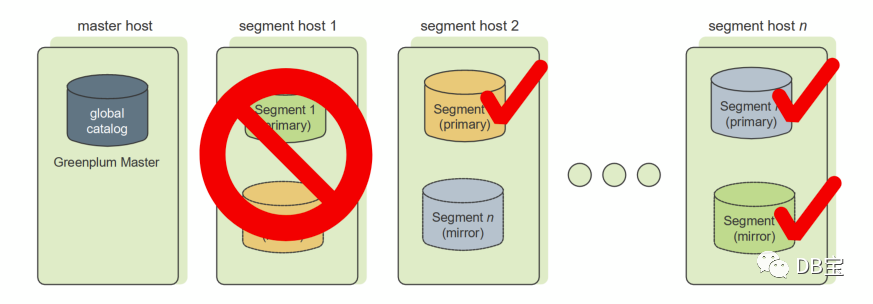
База данных Greenplum хранит данные в нескольких экземплярах сегментов. Каждый экземпляр представляет собой экземпляр базы данных Greenplum PostgreSQL. Данные распределяются между узлами сегментов в соответствии со стратегией распределения, определенной в операторе создания таблицы. Когда зеркалирование сегментов включено, каждый экземпляр сегмента состоит из пары основного и зеркального*. Зеркальный сегмент использует репликацию потока журнала упреждающей записи (WAL) для обеспечения согласованности данных с основным сегментом. Экземпляры зеркала обычно инициализируются с помощью инструментов gpinitsystem или gpexpand. Рекомендуется, чтобы гарантировать, что один компьютер выйдет из строя, зеркало обычно запускается на другом хосте, чем основной сегмент. Существуют также разные стратегии назначения изображений разным хостам. При согласовании размещения зеркал и основных сегментов следует уделить все внимание минимизации неравномерности обработки при возникновении сбоя одной машины.
2.4. Конфигурация оборудования хоста.
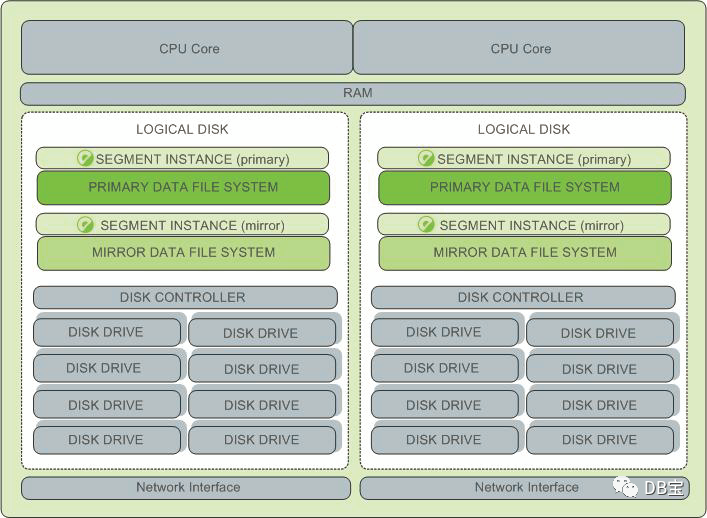

- Главный узел
- сетевая карта 1. Внутреннее соединение 2 сетевых карт 10G. 2. 1-2 гигабитные сетевые карты для внеполосного управления и доступа к сетям клиентов.
- Память DDR4 64 ГБ или выше, рекомендуется 256 ГБ
- диск 1. 6 дисков SAS 600G/900G, 10 тыс. об/мин 2. Используйте RAID5 или RAID10. 3. Зарезервируйте диск горячего резерва отдельно.
- 1 карта RAID, кэш-память 1 ГБ или более, с функцией защиты от отключения питания
- Процессор 1. 2-сторонний 8-ядерный и выше 2. Основная частота 2,5G Гц или выше.
- Узел сегмента
- сетевая карта 1. Внутреннее соединение 2 сетевых карт 10G. 2. 1-2 гигабитные сетевые карты для внеполосного управления и доступа к сетям клиентов.
- Память DDR4 64 ГБ или выше, рекомендуется 256 ГБ
- диск 1. 24 диска SAS 600G/900G, 10 тыс. об/мин. 2. Используйте RAID5 или RAID10. 3. Зарезервируйте диск горячего резерва отдельно. 4. 1-2 RAID-карты, кэш-память 1 ГБ или более, с функцией защиты от отключения питания.
- Процессор 1. 2-сторонний 8-ядерный и выше 2. Основная частота 2,5G Гц или выше.
2.5. Оценка хранилища.
Рассчитать доступное пространство
шаг1:Начальная емкость хранилища=жесткийтарелкаразмержесткийтарелкачисло Шаг 2. Настройте RAID10, отформатируйте дисковое пространство = (начальная емкость хранилища).0.9)/2 шаг3:Доступныйдисккосмос=форматдисккосмос0.7 ;бронировать 0.3 процент пространства для обеспечения места для хранения данных Шаг 4. Использование пространства для пользовательских данных использоватьзеркало:(2пользовательданные)+пользовательданные/3=Доступныйдисккосмос Без зеркалирования: пользовательские данные + пользовательские данные/3 = доступное дисковое пространство.
Рассчитать размер пользовательских данных:
В среднем реально занимаемое место на диске = пользовательские данные * 1,4, из которых 0,4 процента данных составляют следующее:
- Издержки страницы: 20 байт для страницы размером 32 КБ.
- Издержки строк: 24 байта на строку, 4 байта для таблиц, доступных только для добавления.
- Накладные расходы индекса: B-дерево: уникальное значение * (данные размер шрифта + 24 bytes) Bitmap:(уникальная ценностьколичество строк1bitСтепень сжатия/8)+(уникальное значение32)
Рассчитать требования к пространству для метаданных и журналов
- Данные элемента системы: 20M
- Журнал упреждающей записи (WAL): WAL разделен на несколько файлов по 64 МБ. Максимальное количество файлов WAL — 2*checkpoint_segments+1, а значение checkpoint_segments по умолчанию — 8. Это означает, что каждому экземпляру требуется 1088 МБ пространства WAL.
- ГПданные файлы журналов библиотеки: ротация журналов
- Мониторинг производительностиданные
2.6. Резервирование сети.
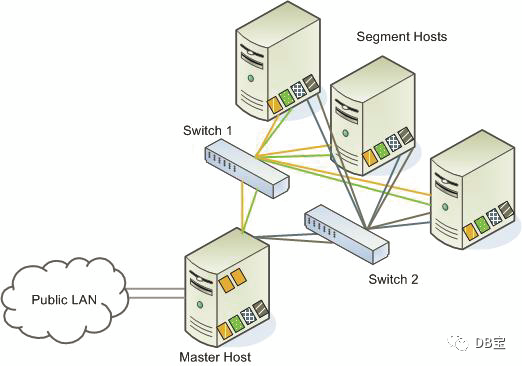
2.7. План развертывания.
- Решение для развертывания группового зеркалирования
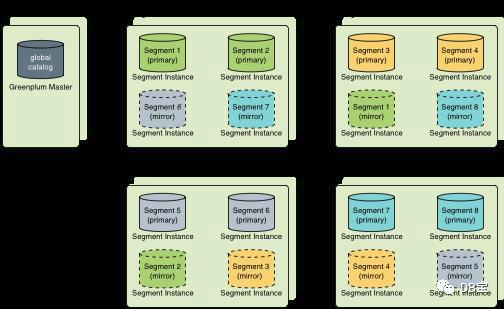
Групповое зеркалирование — это самая простая в настройке конфигурация зеркалирования, которая является конфигурацией зеркалирования Greenplum по умолчанию. Групповое зеркалирование является наименее затратным в масштабировании, поскольку его можно масштабировать, добавив всего два хоста. Нет необходимости перемещать изображение после масштабирования, чтобы сохранить согласованную конфигурацию изображения.
На рисунке ниже показана конфигурация группового зеркалирования с восемью основными сегментами на четырех хостах.

Если и основной сегмент, и зеркало одного и того же экземпляра сегмента не выйдут из строя, до половины хостов могут выйти из строя, и кластер будет продолжать работать до тех пор, пока ресурсов (ЦП, памяти и ввода-вывода) будет достаточно для удовлетворения спроса.
Любой сбой хоста приведет к снижению производительности более чем вдвое, поскольку на зеркальном хосте будет отвечать вдвое больше активных первичных сегментов. Если загрузка ресурсов пользователя обычно превышает 50 %, пользователю придется корректировать нагрузку до тех пор, пока неисправный хост не будет восстановлен или заменен. Если типичное использование ресурсов пользователя составляет менее 50 %, кластер будет продолжать работать с пониженной производительностью до тех пор, пока сбой не будет устранен.
Согласно следующему обзору плана развертывания группового зеркалирования для 4 машин. Недостатки: после выхода из строя машины весь трафик будет передан на следующий узел, а трафик следующего узла станет вдвое больше трафика. Преимущества: после отключения одной машины кластер может нормально предоставлять услуги. Если вы отключите второй кластер, он будет недоступен.
- Spread Mirroring План развертывания по спреду Зеркально отражаясь, зеркало основного сегмента каждого Хозяина распространяется на несколько Хозяинов, а количество задействованных Хозяинов такое же, как и у каждого Хозяина. Количество сегментов одинаковое. Установить распространение во время инициализации кластера Зеркальное отображение легко, но требует, чтобы количество Хозяинов в кластере было не менее 1 на каждого Хозяина. Добавьте единицу к числу сегментов.
На рисунке ниже показана конфигурация распределенного зеркалирования для кластера с тремя основными сегментами на четырех хостах.
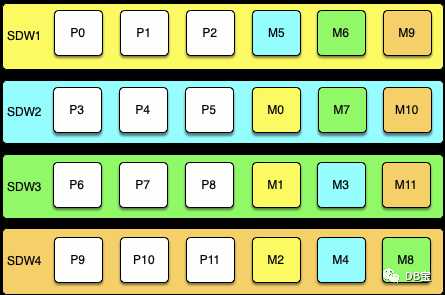
Масштабирование кластера с помощью зеркального отображения требует более тщательного планирования и может занять больше времени. Пользователь должен либо добавить группу хостов, равную числу основных сегментов на каждом хосте плюс один, либо перестроить конфигурацию расширенного зеркала, добавив два узла в конфигурацию группового зеркалирования и переместив зеркала после завершения расширения.
В случае сбоев одного хоста распределенное зеркалирование оказывает минимальное влияние на производительность, поскольку зеркало каждого хоста распространяется на несколько хостов. Увеличение нагрузки составляет 1/Nth, где N — количество первичных сегментов на каждом хосте. Распространенное зеркалирование — это конфигурация, которая с наибольшей вероятностью потерпит катастрофический сбой, если одновременно выйдет из строя более двух хостов.
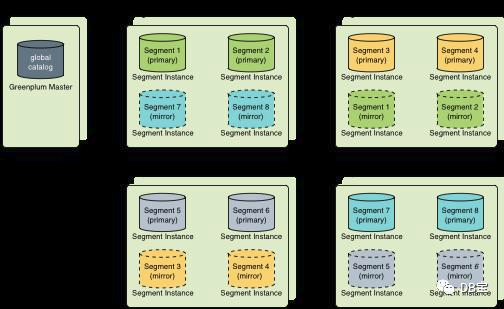
Согласно следующему обзору плана развертывания Spread Mirroring на 4 машинах. Недостаток: после выхода из строя одной машины весь трафик будет передан на следующие два узла. Преимущества: после отключения одной машины кластер может нормально предоставлять услуги. Если вы отключите второй кластер, он будет недоступен.
3.Блокировать зеркалирование Для блочного зеркалирования узлы делятся на блоки, например блоки с четырьмя или восемью хостами, а зеркала сегментов на каждом хосте размещаются на других хостах в блоке. В зависимости от количества хостов в блоке и количества первичных сегментов на каждом хосте каждый хост может поддерживать более одного зеркала для каждого сегмента другого хоста.
На рисунке ниже показана конфигурация зеркалирования одного блока с четырьмя хостами в блоке, каждый с восемью первичными сегментами:
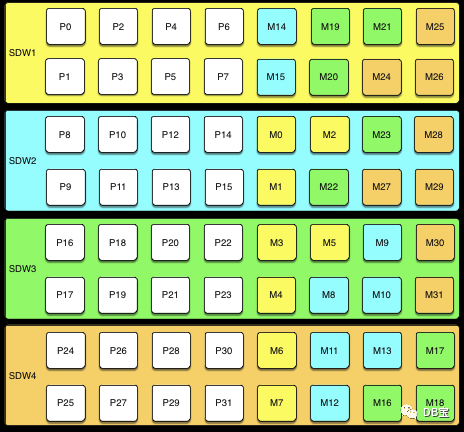
При наличии восьми хостов дополнительный четыреххостовый блок содержит зеркала первичных сегментов с 32 по 63, и настройки находятся в том же режиме.
Кластеры, использующие зеркалирование блоков, легко масштабировать, поскольку каждый блок представляет собой автономную группу первичного зеркала. Кластер можно расширить, добавив один или несколько блоков. Нет необходимости перемещать зеркало после расширения, чтобы поддерживать постоянные настройки зеркала. Эта конфигурация может допускать сбои нескольких хостов, если отказавшие хосты находятся в разных блоках.
Поскольку каждый хост в блоке имеет несколько зеркальных экземпляров каждого другого хоста в блоке, влияние зеркалирования блока на производительность при сбое хоста выше, чем при распространенном зеркалировании, но меньше, чем при групповом зеркалировании. Ожидаемое влияние на производительность зависит от размера блока и количества первичных сегментов на узел. Как и в случае с групповым зеркалированием, если ресурсы доступны, это отрицательно повлияет на производительность, но кластер по-прежнему будет доступен. Если ресурсов недостаточно для обработки возросшей нагрузки, пользователь должен снижать нагрузку до тех пор, пока неисправный узел не будет заменен.
Реализация блока Mirroring Когда пользователи настраивают или расширяют кластер, блокируйте Зеркальное отображение не является автоматической опцией, предоставляемой базой данных Greenplum. Чтобы использовать блок mirroring, Пользователи должны создать свою собственную конфигурацию.
В новой системе Greenplum пользователи могут инициализировать кластер без зеркал, а затем запустить gpaddmirrors -i Mirror_config_file с настраиваемым файлом конфигурации зеркала, чтобы создать зеркала для каждого блока. Прежде чем пользователь сможет запустить gpaddmirrors, он должен создать расположение файловой системы для зеркального сегмента. Подробности см. на справочной странице gpaddmirrors в Руководстве по инструментам администрирования базы данных Greenplum.
Если пользователь расширяет систему с помощью блочного зеркалирования или пользователь хочет реализовать блочное зеркалирование при расширении кластера, пользователю рекомендуется сначала завершить расширение с конфигурацией группового зеркала по умолчанию, а затем использовать инструмент gpmovmirrors для перемещения зеркала в конфигурация блока.
Чтобы реализовать блочное зеркалирование в существующей системе с использованием различных схем зеркалирования, пользователь должен сначала определить местоположение каждого зеркала на основе конфигурации его блока, а затем определить, какие существующие зеркала необходимо переместить. Выполните следующие действия:
Шаг 1. Выполните следующий запрос, чтобы найти текущее местоположение основного и зеркального сегментов:
SELECT dbid, content, role, port, hostname, datadir FROM gp_segment_configuration WHERE content > -1 ;
Таблица системного каталога gp_segment_configuration содержит текущую конфигурацию сегмента.
шаг 2. Создайте список с текущим расположением зеркалирования и желаемым расположением зеркалирования блока, а затем удалите из него зеркало, которое уже находится на нужном хосте. Шаг 3. Создайте входной файл для инструмента gpmovemirrors с каждым элементом (изображением) в списке, который необходимо переместить. Формат входного файла gpmovemirrors следующий:
contentID:address:port:data_dir new_address:port:data_dir
Где contentID — это идентификатор содержимого экземпляра сегмента, адрес — это имя хоста или IP-адрес соответствующего хоста, порт — это порт связи, а data_dir — каталог данных экземпляра сегмента.
Следующий входной файл gpmovmirrors определяет три зеркальных сегмента, которые необходимо переместить.
1:sdw2:50001:/data2/mirror/gpseg1 sdw3:50001:/data/mirror/gpseg1
2:sdw2:50001:/data2/mirror/gpseg2 sdw4:50001:/data/mirror/gpseg2
3:sdw3:50001:/data2/mirror/gpseg3 sdw1:50001:/data/mirror/gpseg3
шаг 4. Запустите gpmovemirrors с помощью следующей команды:
gpmovemirrors -i mirror_config_file
Инструмент gpmovemirrors проверяет входной файл, вызывает gp_recoverseg для перемещения каждого указанного изображения и удаляет исходное изображение. Он создает файл конфигурации отмены, который можно использовать в качестве входных данных для gpmovemirrors для отмены изменений. Файл отмены имеет то же имя, что и входной файл, но к нему добавлен суффикс _backout_timestamp.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
