Архитектура больших данных Lambda-Architect (шестьдесят девять)
сейчас
день
один
код
С развитием технологий в информационную эпоху быстрое увеличение объема данных постепенно достигло поразительного уровня. А технологии сбора и обработки данных все еще совершенствуются и ускоряются. В больших данных на структурированные данные приходится около 15%, а остальные 85% — это неструктурированные данные. Они существуют в больших количествах в таких областях, как социальные сети, Интернет и электронная коммерция.
Характеристики одной большой архитектуры системы данных
1. Надежный и отказоустойчивый
В крупномасштабных распределенных системах машины могут выходить из строя, но система должна быть надежной и работать правильно, даже если она сталкивается с машинными ошибками. Как машинные, так и человеческие ошибки существуют и неизбежны каждый день.
2. Возможности чтения и обновления с низкой задержкой.
Некоторым требуется возможность обновления в течение миллисекунд, а некоторые допускают задержку обновлений на несколько часов. Пока требуется низкая задержка, система должна обеспечивать надежность.
3. Горизонтальное расширение
Когда нагрузка увеличивается, вы обычно можете выполнить масштабирование, добавив больше компьютеров.
4. Универсальность
Для поддержки подавляющего большинства приложений, включая финансовую, социальную и электронную коммерцию.
5. Расширяемость
При возникновении новых потребностей в систему можно добавить новые функции.
6. Возможность запроса
Пользователи могут запрашивать информацию в соответствии со своими потребностями, что может принести более высокую ценность.
7. Минимальные возможности обслуживания.
Большую часть времени система остается сбалансированной, что является важным способом сокращения времени обслуживания системы.
8. Регулируемость
система работает,Каждая произведенная ценность,Все можно отследить и отладить.
2. Лямбда-архитектура
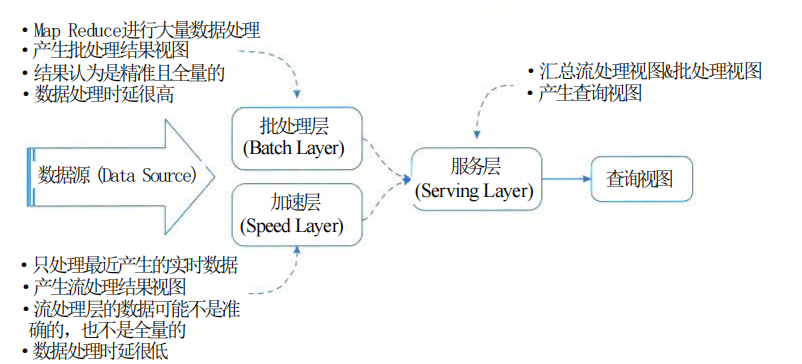
Архитектура Lambda в основном разделена на три уровня: уровень пакетной обработки, уровень ускорения и уровень обслуживания.
(1) Пакетный уровень: хранит наборы данных, предварительно рассчитывает функции запросов и создает представления, соответствующие запросам. Пакетный уровень подходит для пакетной обработки автономных данных. Когда многие сценарии требуют запроса в реальном времени, требуется Speed Layer.
(2) Уровень скорости: пакетный уровень обрабатывает все данные, а уровень скорости обрабатывает дополнительные данные. Уровень скорости будет постоянно обновлять представление в реальном времени после получения данных.
(3) Уровень обслуживания: уровень обслуживания используется для объединения наборов данных результатов в пакетном представлении и представлении в реальном времени в окончательный набор данных.
1. Пакетная обработка
Пакетная обработка имеет две основные функции: хранение наборов данных и создание пакетных представлений. Этот уровень в основном отвечает за основной набор данных, который имеет следующие три атрибута:
(1) Данные оригинальные
(2) Данные неизменяемы.
(3) Данные всегда верны
2. Слой ускорения
Он хранит представления в реальном времени и передает потоки данных для обновления этих представлений.
Какая между ними разница?
(1) Данные, обрабатываемые на уровне скорости, представляют собой инкрементальные данные, а пакетный уровень — это общие данные.
(2) В целях эффективности уровень скорости обновляет представление в реальном времени при получении данных, в то время как пакетный уровень напрямую получает пакетное представление на основе всех автономных данных.
Каковы преимущества разделения на уровни ускорения и пакетной обработки?
Отказоустойчивость: при перерасчете уровня скорости текущее представление в реальном времени можно отбросить, а пакетное представление также пересчитывается.
Изоляция сложности. Пакетную обработку автономных данных легко освоить, а уровень ускорения обрабатывает дополнительные данные, чтобы изолировать их.
Масштабирование: горизонтальное расширение, расширение за счет добавления машин вместо увеличения производительности машин.
3. Сервисный уровень
Используется для ответа на запросы пользователей и объединения наборов результатов в пакетном представлении и представлении в реальном времени для получения окончательного набора данных.
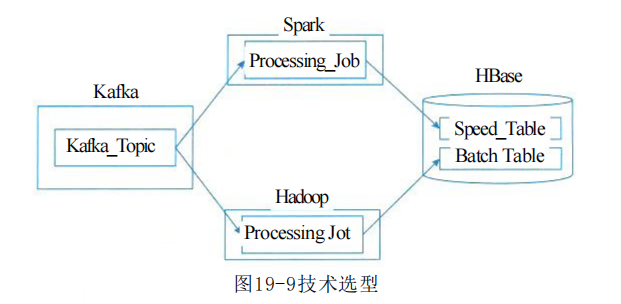
Реализация архитектуры Lambda?
Hadoop (HDFS) используется для хранения наборов данных, Spark (или Storm) формирует уровень скорости, HBase служит уровнем обслуживания, а Hive создает представления с возможностью запроса.
Hadoop предназначен для работы в распределенной файловой системе общего назначения (Distributed File System),Имеет много общего с текущей распределенной системой.,HDFS — это высокоотказоустойчивая база данных.,Может предоставить данные доступа к пропускной способности.
Apache Spark — это быстрый вычислительный механизм, специально разработанный для больших данных.
База данных HBase-Hadoop — это высокодоступная、высокая производительность、столбчатый、Масштабируемая распределенная система.
Преимущества лямбды:
1. Хорошая отказоустойчивость: при возникновении ошибки начните с исправления алгоритма или вычислений с нуля.
2. Высокая гибкость запросов: пакетная обработка позволяет временно запрашивать любые данные.
3. Простота масштабирования. Все пакетные процессы, уровень ускорения и уровень обслуживания легко расширяются.
4. Расширение: добавлять представления легко, просто добавьте новые функции к основным данным.
недостаток:
1. Полное покрытие сцены требует дополнительных затрат на программирование.
2. Переподготовка для конкретных сценариев приносит мало пользы.
3. Затраты на перераспределение и миграцию высоки.
Сравнение архитектуры Lambda с другими архитектурами:
1. Источник событий и лямбда-архитектура
Вся система управляется событиями, а бизнес-данные представляют собой представление, созданное событиями.
2. CQRS и лямбда-архитектура
Архитектура CQRS разделяет операции чтения и записи данных, а также отделяет команды изменения состояния модели данных от запросов состояния модели.
сосредоточиться на Я...сопровождаю вас учиться и добиваться прогресса каждый день



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
