Apache Hudi +MinIO + HMS создают современное озеро данных
Мы изучили [1], как MinIO и Hudi работают вместе для создания современного озера данных. Целью этой публикации в блоге является развитие этих знаний и предоставление альтернативной реализации Hudi и MinIO, использующей службу Hive Metastore Service (HMS[2]). Отчасти из-за истории происхождения экосистемы Hadoop многие крупномасштабные реализации данных Hudi до сих пор используют HMS. Часто истории миграции из устаревших систем связаны с некоторой степенью гибридности, поскольку успех достигается за счет использования лучших из всех задействованных продуктов.
Hudi и MinIO: выигрышная комбинация
Эволюция Hudi от использования HDFS к облачному объектному хранилищу, такому как MinIO, идеально согласуется с отходом индустрии данных от монолитных и неподходящих устаревших решений. Производительность[3], масштабируемость[4] и экономичность[5] MinIO делают его идеальным для хранения и управления данными Hudi. Кроме того, оптимизации Hudi для Apache Spark, Flink, Presto, Trino, StarRocks и других современных данных легко интегрируются с MinIO для обеспечения производительности в облаке в любом масштабе. Эта совместимость представляет собой важную закономерность в современной архитектуре озера данных.
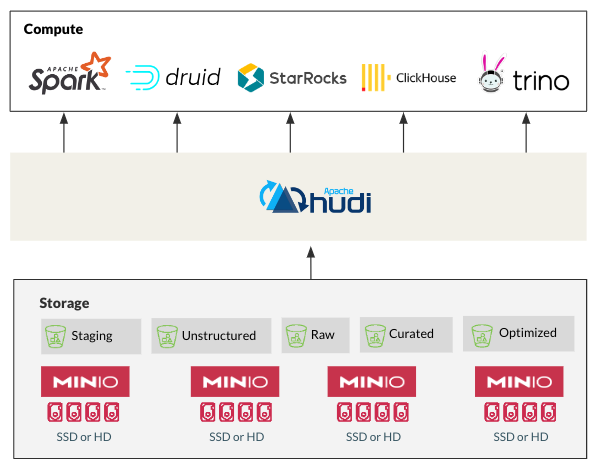
Интеграция HMS: улучшенное управление данными
Хотя Hudi предоставляет основные возможности управления данными «из коробки», интеграция с HMS добавляет еще один уровень контроля и видимости. Вот как интеграция HMS дает преимущества крупномасштабному развертыванию Hudi:
- • Улучшенное управление данными:HMS Источник концентрацииданныеуправлять,существоватьвесьозеро Обеспечьте постоянный контроль доступа и отслеживание данных. и аудит родословной. Это обеспечивает качество данных、соблюдение требований и оптимизация процессов управления.
- • Упрощенное управление архитектурой:существовать HMS определены и реализованы в Hudi Таблица из схемы для обеспечения согласованности и совместимости между конвейерами, приложениями и зданиями. ГМС Функция эволюции шаблона позволяет существованию адаптироваться к изменению изданных структур, не повреждая трубопровод из.
- • Улучшенная видимость и возможность обнаружения:HMS для всех информационных активов, включая Hudi table) предоставляет центральный каталог. Это помогает аналитикам и данным ученым легко находить и исследовать данные.
Начало работы: соответствие предварительным требованиям
Для завершения этого руководства вам потребуется настроить некоторое программное обеспечение. Вот подробности:
- • Docker Engine: этот мощный инструмент позволяет упаковывать и запускать приложения в стандартизированных единицах программного обеспечения, называемых контейнерами.
- • Docker Составление: выступает в качестве координатора для упрощения иурегулирования многоконтейнерных приложений. Это помогает легко определять и запускать сложные приложения.
Установка. Установщик Docker Desktop предоставляет удобное универсальное решение для установки Docker и Docker Compose на определенной платформе (Windows, macOS или Linux). Обычно это проще, чем загружать и устанавливать их по отдельности. После установки Docker Desktop или комбинации Docker и Docker Compose вы можете проверить их наличие, выполнив в терминале следующую команду:
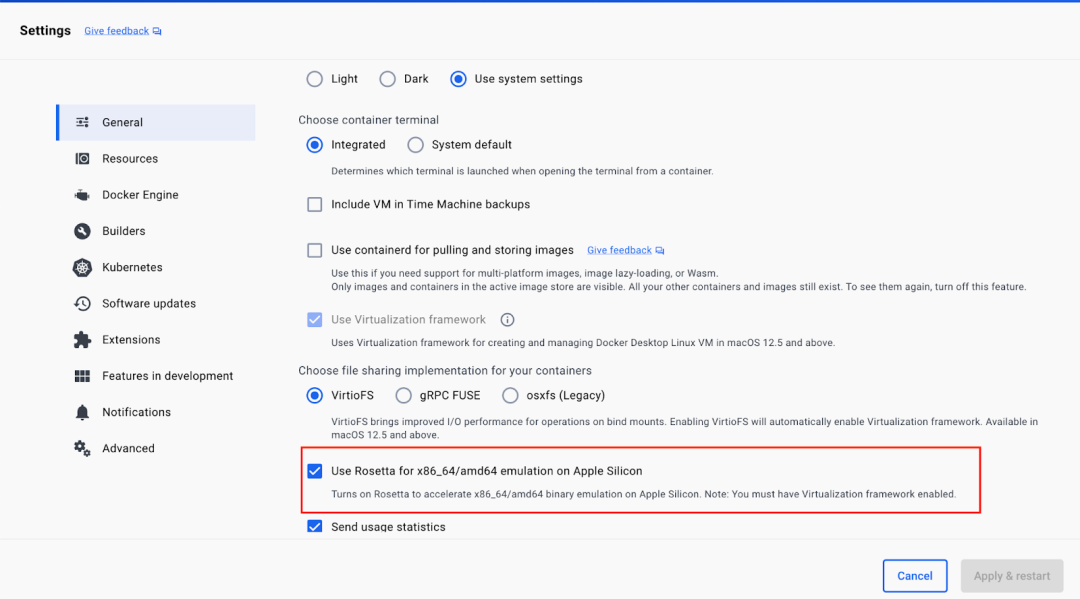
docker-compose --versionОбратите внимание, что это руководство создано для Linux/amd64, и для его работы с чипом Mac M2 также необходимо установить Rosetta 2. Вы можете сделать это в окне терминала, выполнив следующую команду:
softwareupdate --install-rosettaRosetta также необходимо включить двоичную эмуляцию x86_64/amd64 на Apple Silicone в настройках Docker Desktop. Для этого перейдите в «Настройки» → «Основные» и установите флажок Rosetta, как показано ниже.
Интеграция HMS и Hudi на MinIO
В этом руководстве используется демонстрационный репозиторий StarRocks. Клонируйте репозиторий, найденный здесь [6]. В окне терминала перейдите в каталог document-samples, затем перейдите в папку hudi и выполните следующую команду:
docker compose upПосле выполнения приведенной выше команды вы должны увидеть работающие StarRocks, HMS и MinIO. Получите доступ к консоли MinIO через http://localhost:9000/ и войдите в систему, используя учетные данные admin:пароль. Вы увидите, что хранилище сегментов хранилища было создано автоматически.
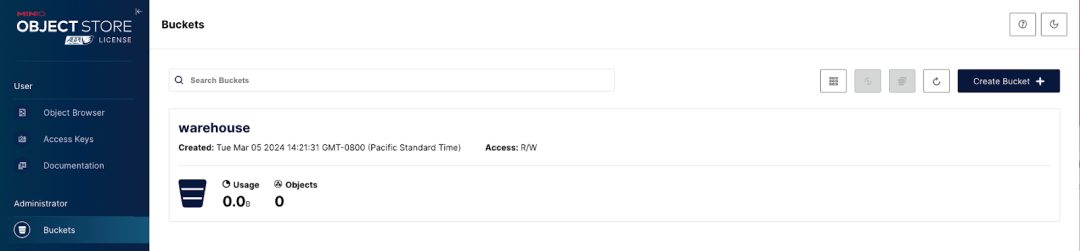
Вставка данных с помощью Spark Scala
Выполните следующую команду, чтобы получить доступ к оболочке внутри контейнера spark-hudi:
docker exec -it hudi-spark-hudi-1 /bin/bash
Затем выполнение следующей команды приведет к входу в Spark REPL:
/spark-3.2.1-bin-hadoop3.2/bin/spark-shellПосле входа в оболочку выполните следующие строки Scala, чтобы создать базу данных, таблицу и вставить данные в таблицу:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType(Array(
StructField("language", StringType, true),
StructField("users", StringType, true),
StructField("id", StringType, true)
))
val rowData= Seq(
Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c")
)
val df = spark.createDataFrame(rowData, schema)
val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://warehouse/hudi_coders"
df.write.format("hudi").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
option(RECORDKEY_FIELD_OPT_KEY, "id").
option(PARTITIONPATH_FIELD_OPT_KEY, "language").
option(PRECOMBINE_FIELD_OPT_KEY, "users").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", databaseName).
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", "language").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").
mode(Overwrite).
save(basePath)
Озеро данных MinIO теперь настроено с использованием Hudi и HMS. Вернитесь по адресу http://localhost:9000/, чтобы увидеть заполненную папку репозитория.
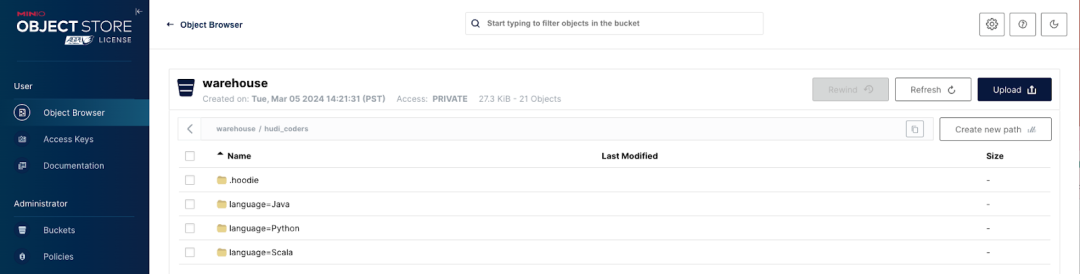
Исследование данных
При желании вы можете использовать следующую Scala в той же оболочке для дальнейшего изучения данных.
val hudiDF = spark.read.format("hudi").load(basePath + "/*/*")
hudiDF.show()
val languageUserCount = hudiDF.groupBy("language").agg(sum("users").as("total_users"))
languageUserCount.show()
val uniqueLanguages = hudiDF.select("language").distinct()
uniqueLanguages.show()
// Stop the Spark session
System.exit(0)Создайте современное облачное озеро данных
Hudi, MinIO и HMS работают вместе, обеспечивая комплексное решение для создания и управления современными озерами данных в любом масштабе. Интеграция этих технологий обеспечивает гибкость, масштабируемость и безопасность, необходимые для раскрытия всего потенциала ваших данных.
Справочная ссылка
[1] Уже исследовано: [https://blog.min.io/streaming-data-lakes-hudi-minio/?utm_term=&utm_campaign=&utm_source=adwords&utm_medium=ppc&hsa_acc=8976569894&hsa_cam=20466868543&hsa_grp=&hsa_ad=&hsa_src=x&hsa_tgt=&hsa_kw=&hsa_mt=&hsa_net=adwords&hsa_ver=3&gad_source=1&gclid=CjwKCAiA0PuuBhBsEiwAS7fsNQanvkO02hS9l_MY0HTiH2XjcPVJVDITKXq4ydcHFmDYUGrwgVH0WBoCXtEQAvD_BwE](https://blog.min.io/streaming-data-lakes-hudi-minio/?utm_term=&utm_campaign=&utm_source=adwords&utm_medium=ppc&hsa_acc=8976569894&hsa_cam=20466868543&hsa_grp=&hsa_ad=&hsa_src=x&hsa_tgt=&hsa_kw=&hsa_mt=&hsa_net=adwords&hsa_ver=3&gad_source=1&gclid=CjwKCAiA0PuuBhBsEiwAS7fsNQanvkO02hS9l_MY0HTiH2XjcPVJVDITKXq4ydcHFmDYUGrwgVH0WBoCXtEQAvD_BwE)
[2] HMS: [https://hive.apache.org/?ref=blog.min.io](https://hive.apache.org/?ref=blog.min.io)
[3] производительность: [https://blog.min.io/nvme_benchmark/](https://blog.min.io/nvme_benchmark/)
[4] Масштабируемость: [https://min.io/product/scalable-object-storage?ref=blog.min.io](https://min.io/product/scalable-object-storage?ref=blog.min.io)
[5] Экономическая эффективность: [https://blog.min.io/the-long-term-costs-of-storage-in-the-cloud/](https://blog.min.io/the-long-term-costs-of-storage-in-the-cloud/)
[6] Здесь: [https://github.com/StarRocks/demo?ref=blog.min.io](https://github.com/StarRocks/demo?ref=blog.min.io)



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
