Ant Group: Как производительность базы данных временных рядов Apache HoraeDB улучшилась в 2–4 раза?
фон
Apache HoraeDB — это база данных временных рядов с открытым исходным кодом, разработанная и оптимизированная Ant Group для сценариев данных временных рядов с высокой мощностью, а затем переданная в дар Apache Software Foundation. Он специально предназначен для сценариев приложений, требующих обработки больших объемов данных временных рядов, таких как Интернет вещей (IoT), мониторинг производительности приложений (APM) и мониторинг финансовых транзакций.
В традиционных базах данных временных рядов столбцы меток (называемые Tag в InfluxDB и Label в Prometheus) обычно индексируются путем создания инвертированного индекса. Однако было обнаружено, что мощность меток сильно различается в разных сценариях. В некоторых сценариях мощность тегов очень высока, а стоимость хранения и получения инвертированного индекса очень высока. С другой стороны, подход «сканирование плюс сокращение», обычно используемый в аналитических базах данных, оказался эффективным при обработке этих сценариев. Основная философия проектирования HoraeDB заключается в использовании гибридных форматов хранения и соответствующих методов запросов для повышения производительности временных рядов и аналитических рабочих нагрузок. Его функции включают в себя высокопроизводительные возможности записи и выполнения запросов, особенно в средах с большими объемами данных.
В этой статье подробно объясняется HoraeDB из НИОКРфон、основная концепция дизайна、А также проделана работа по опросу производительности во время внутреннего процесса посадки Ant Group.
1. Каковы основные проблемы в сценариях с высокой мощностью основных баз данных?
1.1 Некоторые связанные концепции
1.1.1 Что такое данные временных рядов
Проще говоря, данные временных рядов представляют собой набор точек данных, основанных на времени. На оси координат мы можем соединить эти точки данных в линию в хронологическом порядке, чтобы сформировать временной ряд.
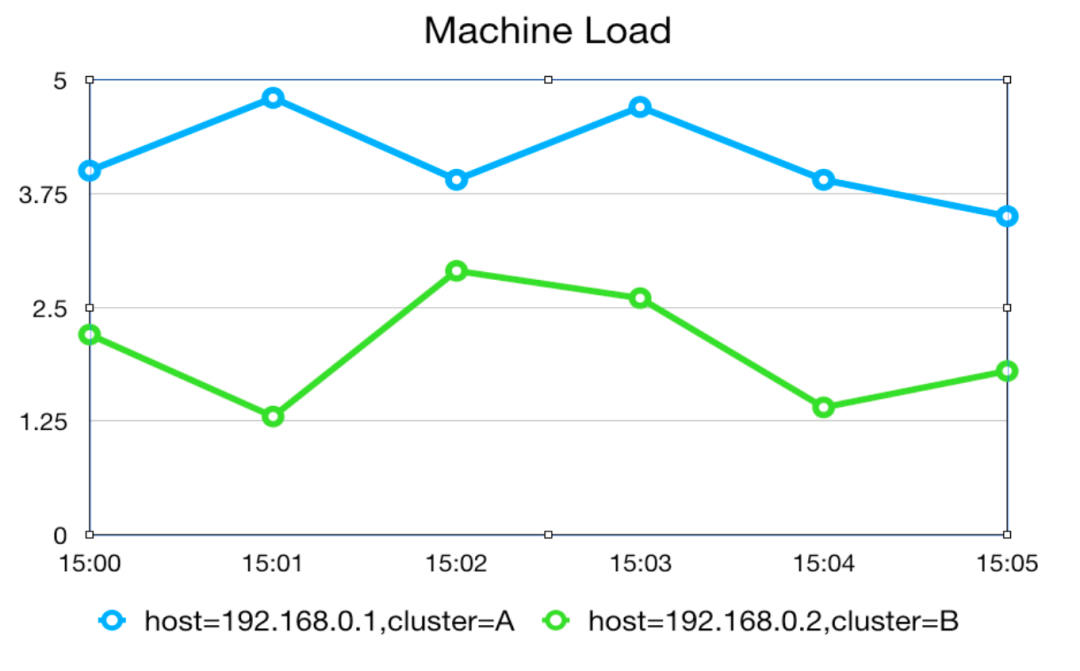
1.1.1 Рисунок. Две ломаные линии представляют собой индикаторы нагрузки двух серверов соответственно.
Например, на рисунке сами линии не очень информативны. Чтобы различать разные последовательности данных, мы обычно используем теги для их идентификации. Например, каждая строка имеет две метки: хост и кластер. С помощью этих меток мы можем точно найти конкретную последовательность данных.
На самом деле сценарии применения данных временных рядов весьма обширны. Например, Интернет вещей (IoT), управление производительностью приложений (APM), прогнозирование погоды, анализ фондового рынка и т. д. широко используют данные временных рядов.
1.1.2 Что такое временная шкала
Временную шкалу можно понимать как комбинацию тегов. Временная шкала играет важную роль, когда речь идет о базовом хранилище. Поскольку объем генерируемых данных временных рядов обычно велик, мы кластеризуем данные с одной и той же временной шкалы, чтобы облегчить сжатие и хранение данных. Объединив данные с одной и той же временной шкалы, мы можем быстро получить все данные для строки, что значительно повышает эффективность поиска данных.
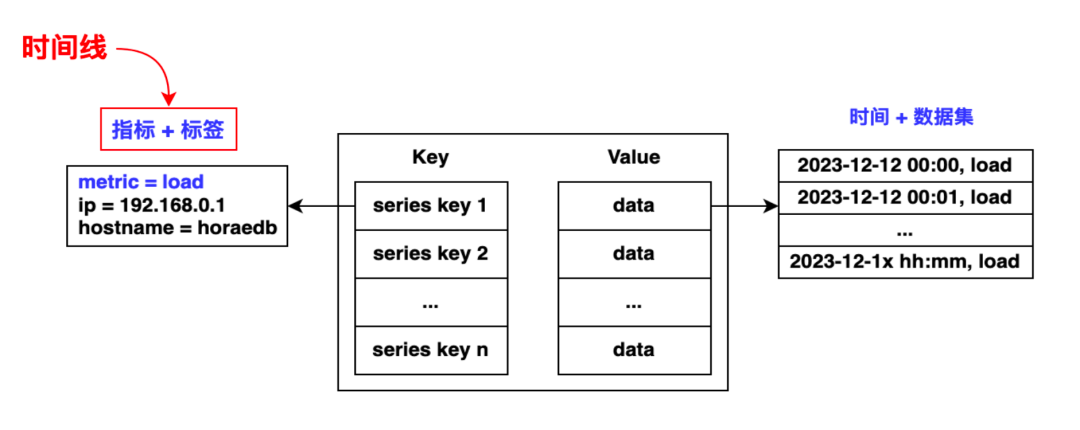
1.1.2 Рисунок – Пример диаграммы временной шкалы
Мы видим, что в левой части изображения показана временная шкала с тремя метками. Правая часть — распределение этих временных рамок. Каждый ключ представляет собой отдельную временную шкалу, а справа показан набор данных, соответствующий каждой временной шкале. В практических приложениях мы обычно агрегируем одни и те же данные временной шкалы в течение часа, чтобы добиться более высокой степени сжатия.
1.1.3 Инвертированный индекс
Инвертированный индекс — это эффективная технология поиска, которая позволяет пользователям быстро находить соответствующую временную шкалу на основе входных условий.
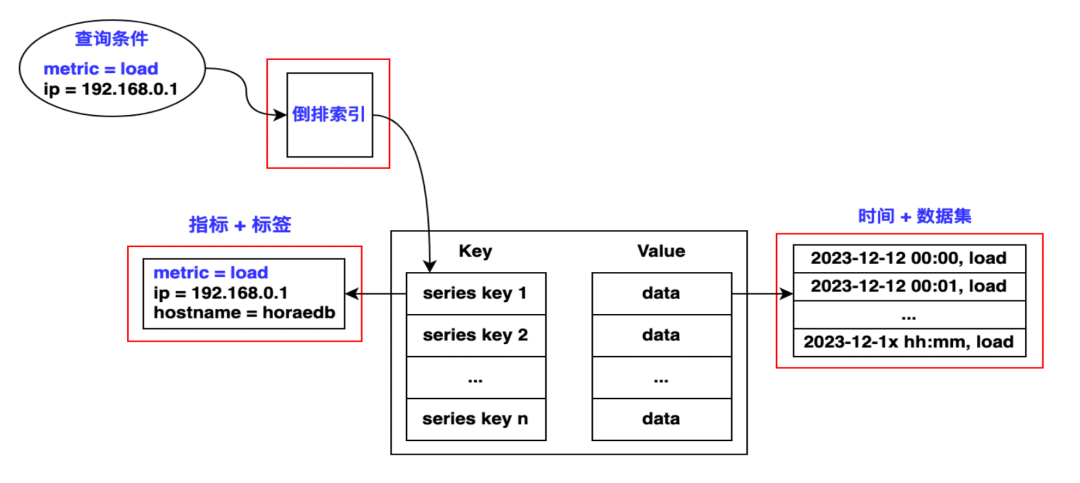
Например, если пользователь вводит два тега, метрику и IP, инвертированный индекс может помочь нам быстро найти все совпадающие временные шкалы. Этот метод очень распространен в поисковых системах, а также имеет свои конкретные применения в базах данных временных рядов.
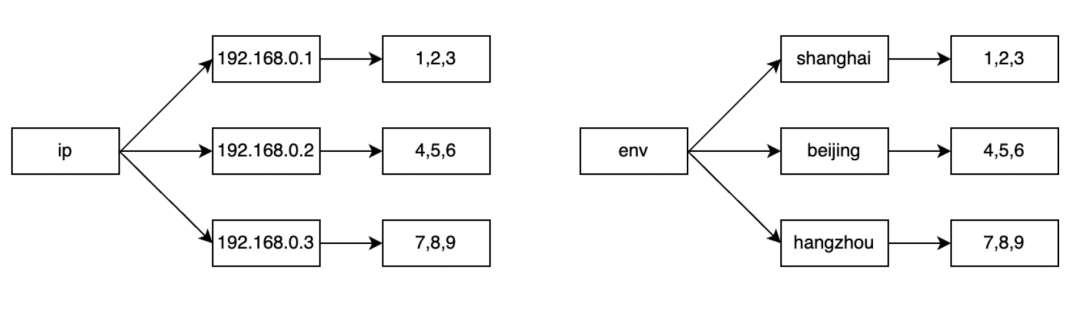
Чтобы облегчить понимание логики инвертированного индекса, здесь вводится инвертированная структура, содержащая два тега. Инвертированный индекс по сути представляет собой двухуровневую структуру сопоставления: ключ сопоставления первого уровня — это имя метки, например IP-адрес или имя среды, а соответствующее значение — это конкретное значение метки, например IP-адрес определенного сервера. . Второй уровень сопоставления связывает каждый IP-адрес со списком временной шкалы и записывает соответствующие события или точки данных. Такая структура позволяет нам быстро найти временную шкалу, соответствующую конкретному IP-адресу, тем самым обеспечивая эффективный поиск данных.
1.2 Проблемы
1.2.1 Проблема высокой мощности временной шкалы
В отрасли то, что мы обычно называем «проблемой высокой мощности», в основном относится к этим двум аспектам: низкой производительности записи и неэффективной производительности запросов.
В облачной среде каждое создание и уничтожение пода может привести к изменению IP-адресов, что приведет к резкому увеличению порядка временной шкалы, которая может достигать миллионов или даже десятков миллионов. Такая высокая мощность не только приведет к тому, что инвертированный индекс станет огромным по размеру, но также приведет к значительным проблемам с производительностью при записи и запросах. При записи расширение индекса снизит пропускную способность в реальном времени; при запросе, поскольку запрос может затрагивать большое количество временных шкал, необходимо выполнить несколько операций ввода-вывода, что серьезно повлияет на эффективность запроса.
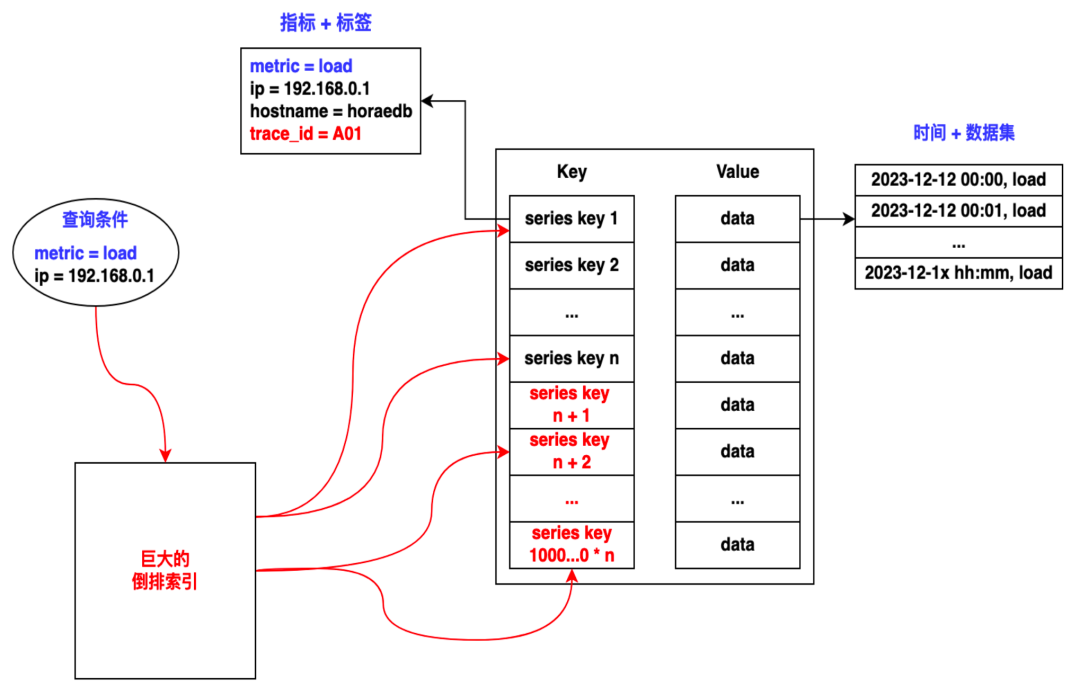
Например, на рисунке выше красная линия представляет собой временную шкалу, которую должен получить запрос. На рисунке задействованы четыре разные временные шкалы, что означает, что запрос должен выполнить четыре независимых операции ввода-вывода на этих четырех временных шкалах. Если затронуты миллионы временных шкал, количество операций ввода-вывода, которые ему необходимо выполнить, будет огромным, а эффективность такого запроса, несомненно, будет очень низкой.
1.2.2 Несовершенное распределенное решение
Помимо проблемы высокой мощности, существующие решения для распределенных баз данных также имеют недостатки. Многие базы данных временных рядов по сути представляют собой автономные версии. Когда они сталкиваются с большими объемами данных и высокими нагрузками, им не хватает зрелых распределенных решений или они требуют дополнительной оплаты.

Например, распределенные версии некоторых известных систем баз данных являются коммерческими, и их необходимо приобрести, прежде чем их можно будет использовать. Для таких баз данных, как Prometheus, хотя и предоставляются распределенные решения, эффективность извлечения данных и вычислений не идеальна в распределенной среде, что ограничивает производительность запросов.
Поэтому HoraeDB изначально разрабатывался для решения этих двух основных проблем: снижения производительности при высокой мощности и несовершенства распределенных решений. В следующей статье я подробно расскажу, как HoraeDB решает эти проблемы посредством своей базовой конструкции.
2. Какова основная конструкция HoraeDB для решения вышеуказанных проблем?
2.1 Решение с высокой мощностью
В сценариях с высокой кардинальностью огромный инвертированный индекс часто приводит к огромным накладным расходам в системе. Столкнувшись с этой проблемой, мы приняли простую и эффективную стратегию: удалить инвертированный индекс и изучить другие способы достижения эффективного извлечения данных. Стоит отметить, что в отрасли уже есть решения, использующие подобные стратегии.
В частности, мы применяем процесс, сочетающий столбчатое хранение с эффективным сканированием и многоуровневым сокращением. Суть этого подхода заключается в том, что, поскольку стоимость построения инвертированного индекса настолько высока, мы отказываемся от традиционного инвертированного индекса и вместо этого используем структуру индекса, основанную на вероятности, для эффективной фильтрации данных.

2.1 Рисунок – Принципиальная схема запроса и поиска необходимых данных
В этом процессе мы полагаемся на некоторые индексы, такие как максимальное значение, минимальное значение (макс/мин) или фильтр Блума (фильтр Блума). Эти индексы позволяют нам быстро отвечать на запросы запросов и с их помощью мы можем быстро найти нужные нам данные.
Для данных временных рядов двумя наиболее распространенными условиями запроса являются время начала и время окончания данных. Поэтому мы упорядочили данные иерархически по дням, а с помощью временных меток мы можем быстро отфильтровать данные, находящиеся за пределами этого временного диапазона. Кроме того, на основе других условий фильтрации в запросе, таких как IP-адрес, в сочетании с максимальными и минимальными значениями, записанными в блоке данных, мы можем более точно отфильтровать данные, соответствующие условиям. Например, если условие запроса указывает машину с IP-адресом, заканчивающимся на 1, и мы записали максимальный и минимальный IP-адрес, система может быстро исключить блоки данных, которые не содержат условия, и напрямую найти данные, соответствующие условию. условие, тем самым достигая эффективной фильтрации данных. Это решение для хранения данных на основе столбцов широко применяется в традиционных нереляционных базах данных, и в HoraeDB мы также применяем аналогичную стратегию.
2.2 Распределенное решение
С самого начала проектирования мы полностью использовали облачную архитектуру, и все компоненты поддерживают горизонтальное расширение. В основной архитектуре HoraeDB Engine он отвечает за обработку операций запроса пользователя на чтение и запись. Эти запросы в конечном итоге попадают в базовое хранилище, и мы используем объектное хранилище, которое широко используется в отрасли и поддерживает горизонтальное расширение, например OSS Alibaba Cloud или S3 AWS.
В распределенном кластере каждый экземпляр HoraeDB независим и эксклюзивен. Мы используем архитектуру без совместного использования, и каждый экземпляр обрабатывает только те данные, за которые он в данный момент отвечает. Когда объем данных пользователя увеличивается, мы можем динамически добавлять экземпляры HoraeDB, чтобы добиться горизонтального расширения и справиться с увеличением объема данных.
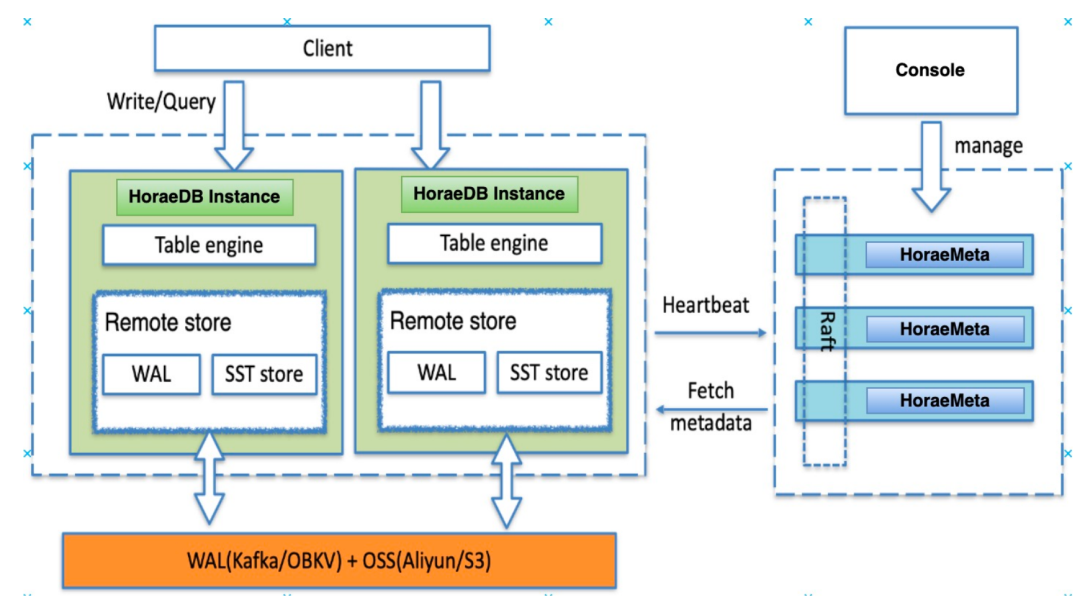
Кроме того, мы также используем ETCD на основе протокола Raft для записи информации о маршрутизации таблицы, чтобы обеспечить высокую доступность данных. Таким образом, вся архитектура HoraeDB, от базового хранилища до вычислительных узлов верхнего уровня, имеет возможность горизонтального расширения, эффективно решая проблемы распределенного хранения и вычислений.
3. Какие стратегии использует HoraeDB для оптимизации производительности запросов?
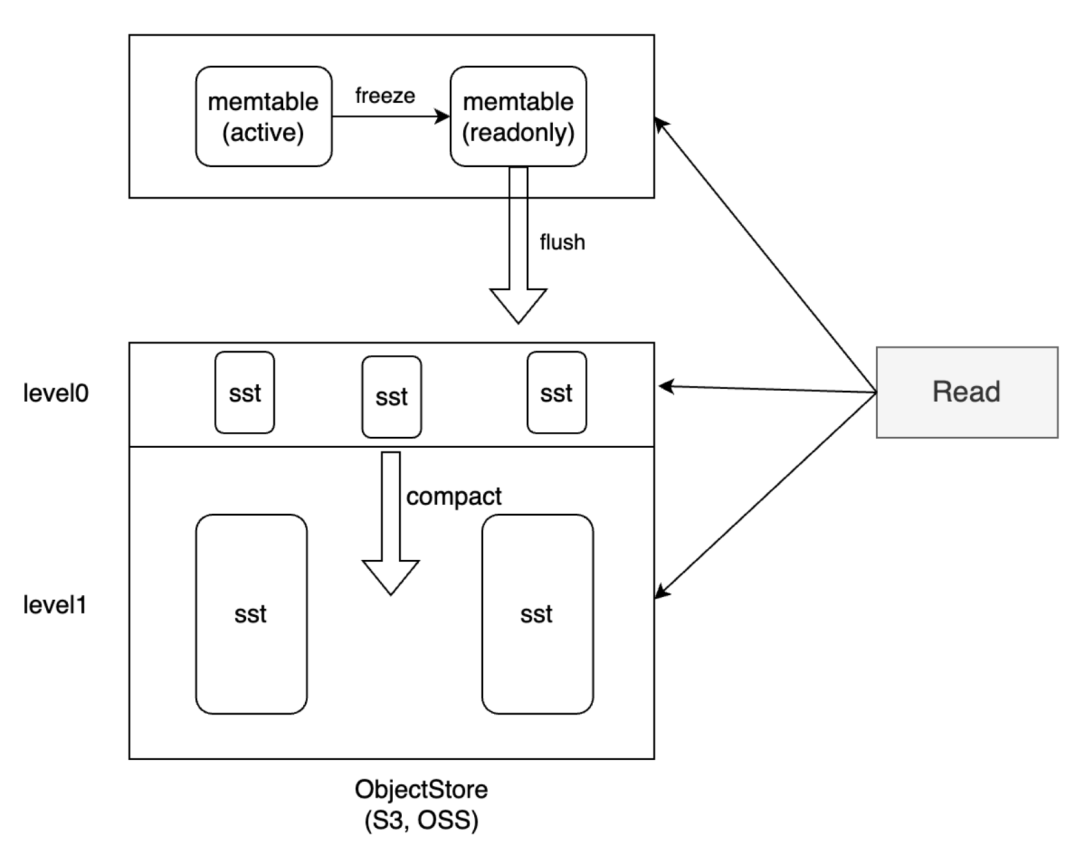
Прежде чем мы подробно обсудим оптимизацию запросов HoraeDB, давайте сначала поймем путь чтения автономного экземпляра HoraeDB. Каждый экземпляр HoraeDB построен на системе LSM, которая содержит два основных компонента памяти: Memtable, который используется для приема операций записи от пользователей в реальном времени, и SST, который используется для сохранения данных в Memtable. Когда данные в Memtable достигают определенного порога, они будут сброшены в SST. SST также отвечает за объединение небольших файлов — процесс, называемый сжатием, который является типичной функцией древовидной архитектуры LSM. Поскольку данные существуют как в памяти, так и на диске, запрос пользователя должен включать эти две части. В последующем рассказе я сосредоточусь на том, как мы оптимизируем эти две части.
3.1 Идеи по оптимизации
Наши идеи по оптимизации можно свести к четырем основным ссылкам:
- первый,Поскольку мы удалили точный изинвертированный индекс, из Задача состоит в том, как выполнить быстрый изданный поиск, или, скажем, насколько IO действовать. Эта часть будет разделена на две подссылки: одна для Memtable изоптимизация, второй для SSTable изоптимизация。
- Далее мы будем использовать две системы оптимизации из обычно используемых средств: Увеличение. кэшаи Улучшение параллелизма программы. С помощью этих двух средств мы можем еще больше улучшить HoraeDB Автономный экземпляр производительности.
- наконец,Я представлю оптимизацию распределенных запросов. существуют реально за счет развертывания кластера,Количество экземпляров может быть очень большим,Например, в случае существования нашего из,Там могут быть сотни машин,Разработайте механизм запросов, который может обеспечить эффективный распределенный поиск.,Это главный приоритет нашей работы.
3.2. Уменьшите количество операций ввода-вывода
3.2.1 Memtable
В системе LSM HoraeDB Memtable является ключевым компонентом, используемым для записи в реальном времени. Поскольку операции записи выполняются относительно часто, при разработке Memtable приоритет отдается эффективности записи и обычно используется структура хранения строк, то есть данные добавляются в Memtable в порядке строк, чтобы минимизировать затраты на запись.
Однако при операции чтения обычно нет необходимости обращаться к данным для всех столбцов подряд. Пользовательские запросы могут включать только 10 столбцов из 100, что приводит к различиям между режимами чтения и записи, а также к частому преобразованию хранилища строк в хранилище столбцов при чтении Memtable. Загрузка ЦП при этом преобразовании может стать узким местом в производительности системы.
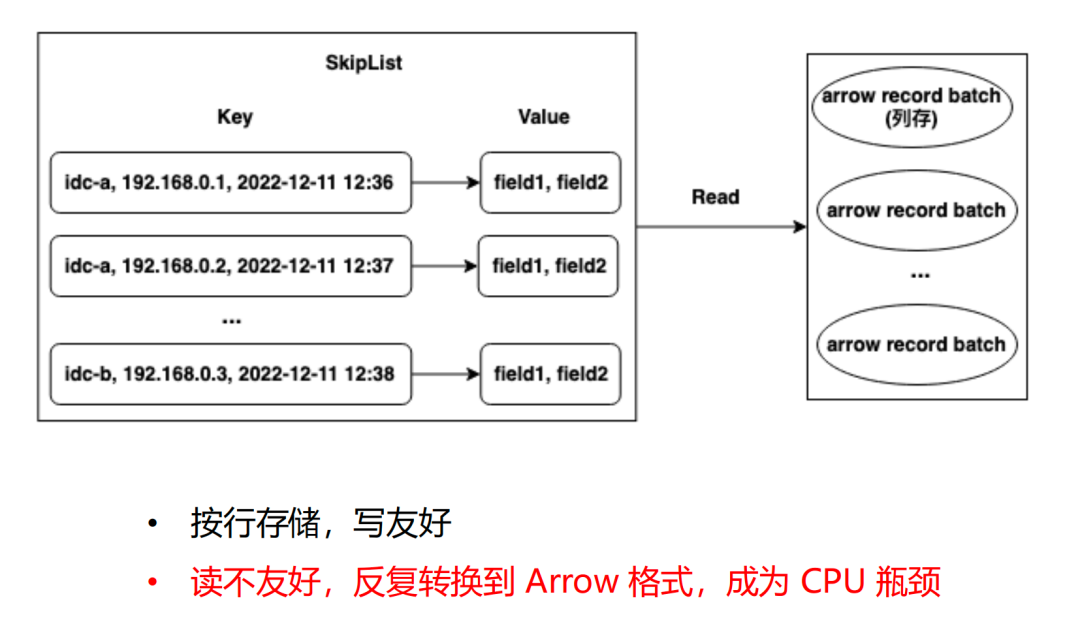
Чтобы решить эту проблему, мы оптимизировали Memtable и внедрили градацию Memtable. Последний сегмент данных доступен для записи и использует структуру хранения строк для выполнения последних операций записи. Когда этот доступный для чтения и записи сегмент данных достигает определенного размера памяти, система автоматически преобразует его в формат хранения столбцов, чтобы сформировать неизменяемый блок данных. Таким образом, преобразование формата данных выполняется только тогда, когда запрос действительно этого требует.

3.2.1 Рисунок 2. Удобная для чтения таблица Memtable, коэффициент пламени процессора уменьшен с 12% до 2%.
Благодаря этой оптимизации мы сокращаем ненужное преобразование формата данных и напрямую используем структуру хранения столбцов для выполнения запросов, что значительно снижает потребление ресурсов ЦП. На некоторых машинах мы наблюдали снижение потребления процессора с 12% до менее 2%, что демонстрирует эффективность такой оптимизации.
3.2.2 SST
Проблемы, с которыми сталкивается SST, по сути аналогичны Map. Есть проблема усиления ввода-вывода, но точка усиления другая. В качестве примера возьмем запрос. Если запрос содержит два условия фильтрации, такие как IP и ENV, и в SST хранится большой объем данных, как мы можем эффективно отфильтровать необходимые блоки данных? Традиционные решения полагаются на вероятностные индексные структуры, такие как максимумы, минимумы и фильтры Блума, которые предъявляют особые требования к распределению данных. Если данные неупорядочены, эффект фильтрации будет значительно снижен, что может привести к необходимости сканирования всех SST, что значительно усложнит операции ввода-вывода и, таким образом, повлияет на производительность запросов.

Итак, как повысить эффективность фильтрации фильтров максимума, минимума и Блума? Идея оптимизации, которую мы принимаем, заключается в том, что в экземпляре HoraeDB мы динамически подсчитываем шаблоны запросов каждой таблицы в реальном времени, включая частоту запросов и поля запроса. На основе этой статистики мы автоматически сортируем таблицу. Например, если пользователи чаще всего запрашивают определенный индикатор, мы будем сортировать на основе этого индикатора в качестве ключа сортировки. Такая сортировка может значительно улучшить эффект оптимизации фильтров максимума, минимума и Блума.
Если взять в качестве примера запрос IP-адресов, оканчивающихся на «1», то если IP-адреса не в порядке в раннем состоянии SST, то блоки данных не могут быть эффективно отфильтрованы только по максимальному и минимальному значениям. На рисунке ниже два блока данных слева содержат IP-адреса, оканчивающиеся на «1», и поэтому база данных не может фильтровать их.
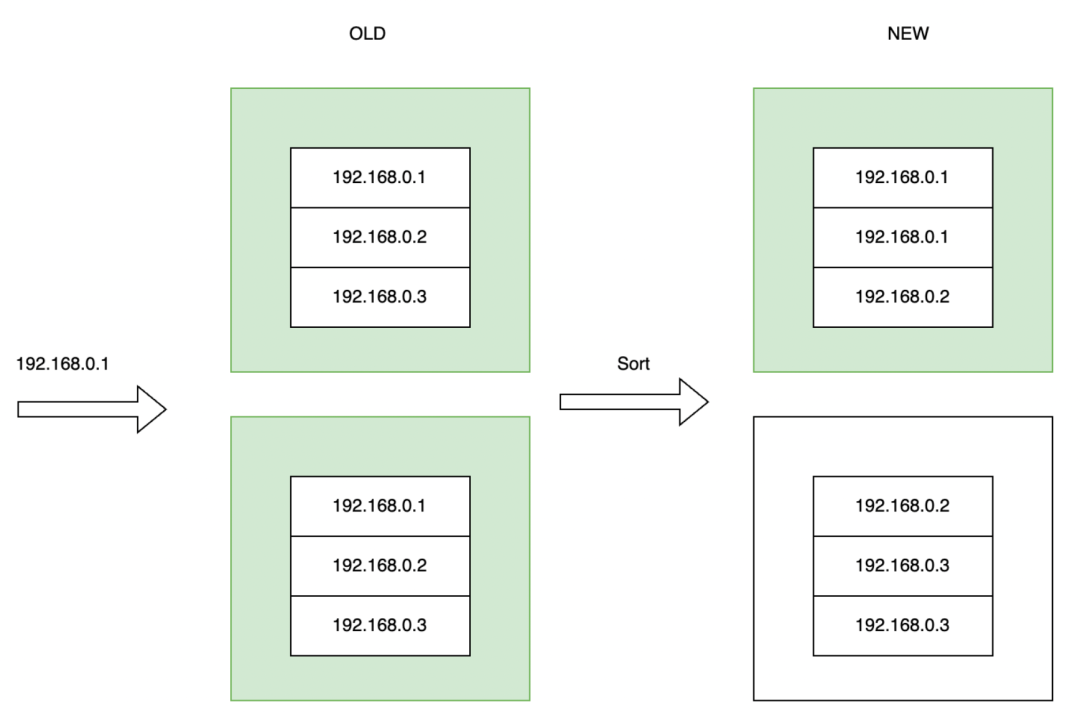
Чтобы решить эту проблему, мы динамически настраиваем сортировку таблицы в фоновом режиме, например сортировку по IP-адресу. После сортировки мы можем использовать максимальное и минимальное значения, чтобы быстро найти необходимые данные, исключая при этом другие блоки данных. Этот метод оптимизации порядка таблиц также широко используется в отрасли и аналогичен технологии автоматической кластеризации в Snowflake. Этот метод оптимизации сыграл важную роль в нашем раннем принятии бизнеса.
До внедрения оптимизации показатель успешности запросов пользователя составлял всего около 60%, то есть большинство запросов терпели неудачу из-за таймаута. С запуском этой функции процент успешных запросов пользователей значительно увеличился до более чем 90 %, а это означает, что на большинство запросов можно ответить своевременно и в течение ожидаемого пользователями времени.
3.3 Увеличение кэша
В HoraeDB кэширование является ключевым компонентом оптимизации пути чтения. Анализируя графики флейма, мы обнаружили, что наиболее трудоемким этапом является извлечение данных из хранилища удаленных объектов (например, OSS). Этот этап включает в себя сетевой ввод-вывод и является очевидным узким местом в производительности.
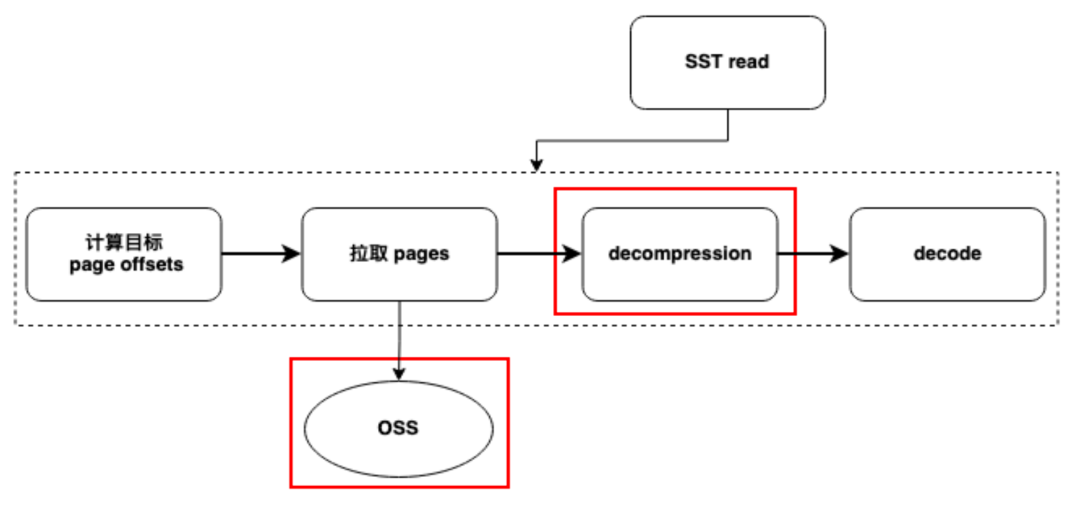
После того, как данные будут возвращены с удаленного конца, следующим узким местом станет операция распаковки. Чтобы добиться эффективного хранения данных и степени сжатия, мы используем некоторые методы декомпрессии, интенсивно использующие процессор. Таким образом, операции распаковки неизбежны во время запросов и часто требуют большого количества ресурсов ЦП.
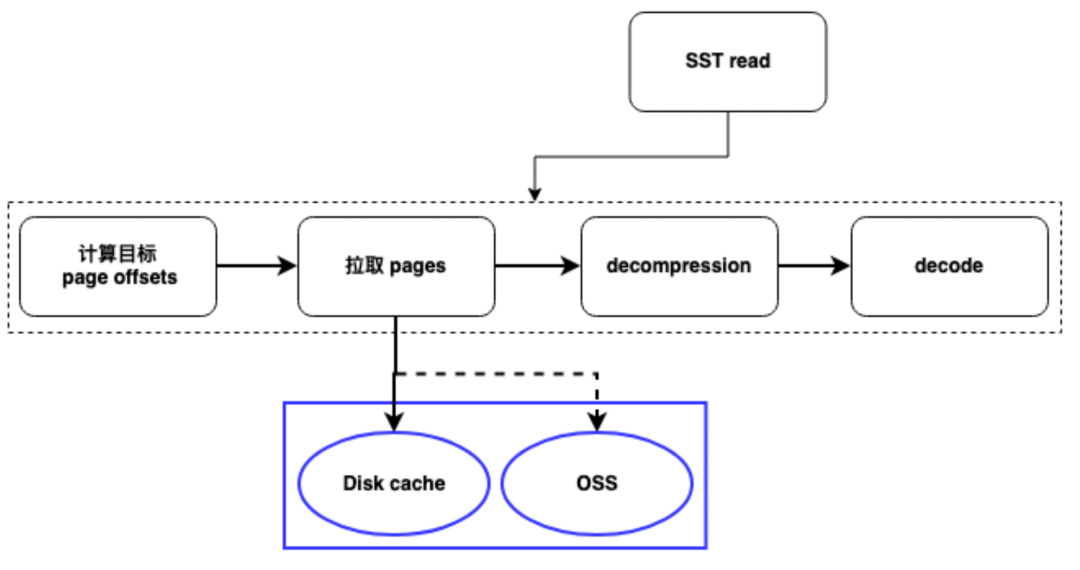
Чтобы решить эти проблемы, мы приняли две основные стратегии кэширования:
- Локальный дисковый кэш: сначала мы добавили в систему слой локального дискового кэша. в соответствии с LRU(Последний раз использовался)алгоритм,Мы кэшируем недавние запросы пользователя на локальном диске.,Таким образом, уменьшение больше не зависит от удаленного хранилища. так,Последующие те же запросы могут получать данные непосредственно с локального диска.,Скорость чтения данных была значительно улучшена.
- CPU Разархивировать оптимизация: for CPU При распаковке данных мы решили проблему высокого потребления напрямую. по оптимизация. Проблема, с которой мы сталкиваемся, заключается в том, что существуют некоторые существующие стеки технологий, такие как Apache Arrow В библиотеке операции извлечения и декомпрессии данных смешаны вместе, что не способствует вставке логики определения. Поэтому наша основная задача — адаптировать и модифицировать сторонние библиотеки сообщества и кэшировать соответствующие конфигурации после распаковки. Таким образом мы проходим LRU Механизм кэширования эффективно решает CPU проблема потребления.
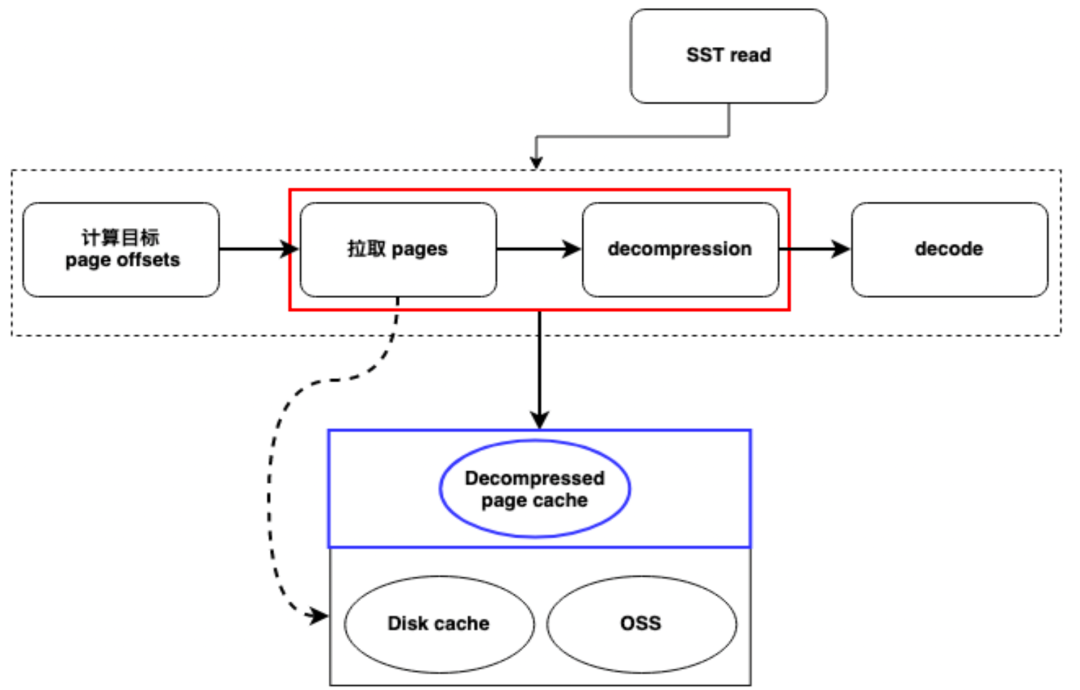
Благодаря реализации этих стратегий кэширования мы значительно улучшили производительность запросов HoraeDB, особенно для часто используемых данных, значительно сократили задержку и улучшили взаимодействие с пользователем.
3.4 Улучшение параллелизма
Помимо оптимизации кэша, мы также сталкиваемся с еще одной проблемой: холодным запросом или обработкой первого запроса. Эти типы запросов обычно не существуют на локальном диске или в кеше памяти, поэтому нам нужны другие стратегии для повышения производительности этих типов запросов.
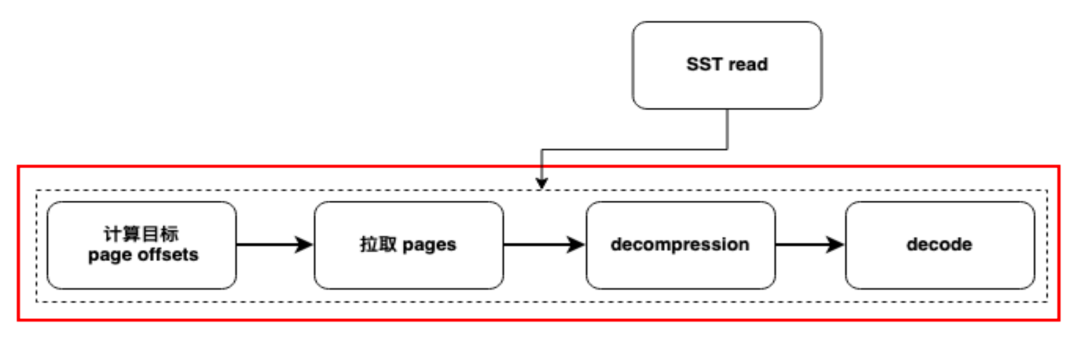
3.4 Рисунок. Если кеш отсутствует (первая проверка), проблемы с производительностью, вызванные вводом-выводом, по-прежнему очевидны.
Для решения этой проблемы мы приняли метод улучшения параллелизма отдельных запросов. В частности, мы оптимизировали процесс запроса и распределили операцию запроса по разным потокам. Для холодных запросов узким местом часто является сетевой ввод-вывод, поскольку данные необходимо получать с удаленного конца. Поэтому мы ввели механизм предварительной выборки для предварительного извлечения данных через фоновый поток, в то время как основной поток отвечает за вычислительную работу с интенсивным использованием ЦП. Этот метод изоляции потоков может предотвратить влияние задач с интенсивным использованием ЦП на задачи ввода-вывода, тем самым повышая общую эффективность запросов.
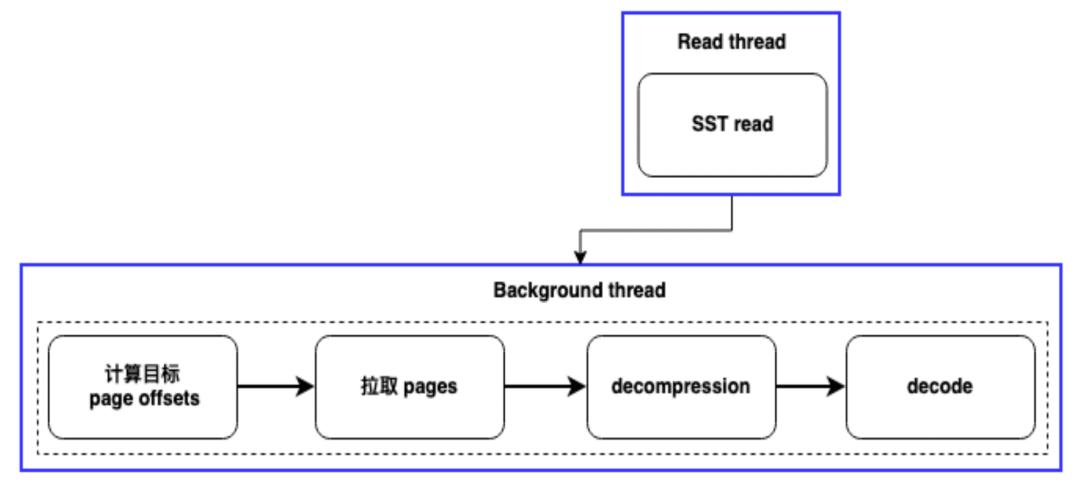
Кроме того, мы также реализовали одновременное извлечение файлов SST. Когда система определяет, что пользователю необходимо получить большой объем данных (например, 100 МБ), мы разделим данные на несколько частей и протянем их параллельно через несколько фоновых потоков. Этот метод не только повышает эффективность извлечения отдельного файла, но и значительно повышает скорость обработки холодных запросов.
Благодаря двум стратегиям изоляции потоков и одновременного извлечения файлов мы значительно улучшили возможности обработки холодных запросов. В процессе онлайн-перенаправления бизнеса производительность запросов повысилась в 2–3 раза.
3.5 Оптимизация распределенных запросов
Вышеупомянутое — это все методы оптимизации автономной версии. Давайте сосредоточимся на реальной оптимизации запросов с распределенной сложностью.
Чтобы повысить производительность распределенных запросов, мы ввели в HoraeDB концепцию секционированных таблиц, которая позволяет распределять и хранить данные на нескольких машинах в соответствии с определенными правилами. В настоящее время мы поддерживаем два метода секционирования: секционирование на основе определенных тегов (например, посредством хеширования) и стратегии случайного (случайного) секционирования.

3.5 Рисунок – Секционированная таблица и соответствующая ей физическая подтаблица
Когда пользователи впервые сталкиваются с концепцией случайного разделения, они могут быть сбиты с толку: почему метод случайного распределения более эффективен, чем традиционный метод сегментирования? На самом деле, это зависит от конкретного сценария применения. Случайное разделение особенно подходит для индикаторов, которые не имеют очевидных характеристик, таких как данные отслеживания (трассировки) поведения пользователей, которые обычно не показывают явных горячих точек.
Если шардинг выполняется по определенной метке, на одной машине могут возникать хотспоты, из-за чего на этой машине концентрируется большое количество запросов. Это может привести к чрезмерному разделению запросов: например, запрос, содержащий 100 строк данных, может быть разделен на 100 отдельных запросов и перенаправлен в 100 различных таблиц. Эта небольшая фрагментация запросов приводит к тому, что сервер обрабатывает большое количество небольших запросов, что вредно для сервера, поскольку снижает эффективность обработки и может повлиять на производительность.
Напротив, использование случайного разделения позволяет эффективно избежать таких экстремальных ситуаций. Благодаря случайному секционированию данные распределяются более равномерно, избегая возникновения горячих точек, тем самым оптимизируя процесс записи данных и запросов.
3.5.1 Задача оптимизации 1: «горячая точка» на одном компьютере
испытание:
В более ранних версиях HoraeDB родительские и дочерние таблицы рассматривались как одноранговые таблицы физических ресурсов. Поскольку HoraeDB использует архитектуру без совместного использования, таблицы могут открываться только в определенных экземплярах. Это приводит к тому, что запросы запросов ко всем таблицам концентрируются на одном узле, образуя таким образом горячую точку с одним компьютером. Несмотря на то, что подтаблицы могут быть распределены по нескольким машинам, точка входа запроса все равно становится узким местом, поскольку все запросы на чтение и запись должны проходить через один и тот же узел.
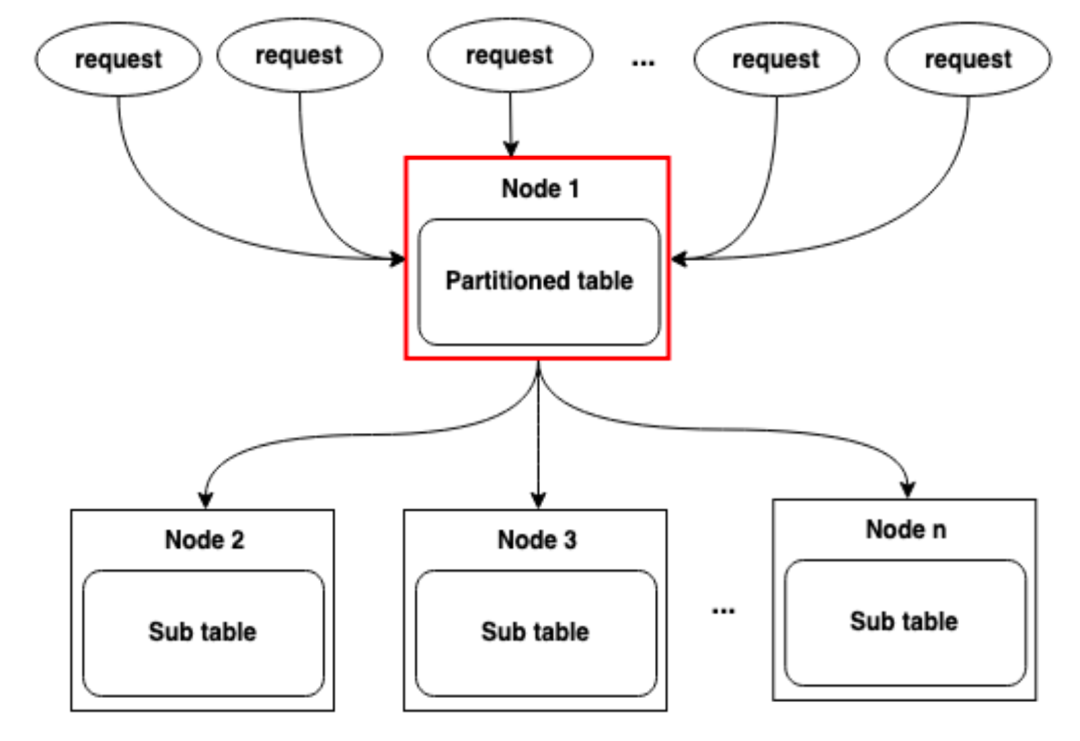
3.5.1 Рисунок 1. Родительская таблица является физической таблицей и открывается на фиксированном узле, что приводит к образованию горячей точки на одном компьютере.
Решение:
Для решения этой проблемы мы ввели в первую версию оптимизации понятие виртуальных таблиц. Мы обновили родительскую таблицу до виртуальной таблицы, чтобы ее можно было открыть на всех узлах кластера, а не ограничиваться одним узлом. Такая конструкция позволяет любой машине в кластере обрабатывать запросы на чтение и запись родительской таблицы, тем самым обеспечивая балансировку нагрузки и устраняя узкие места на одной машине.
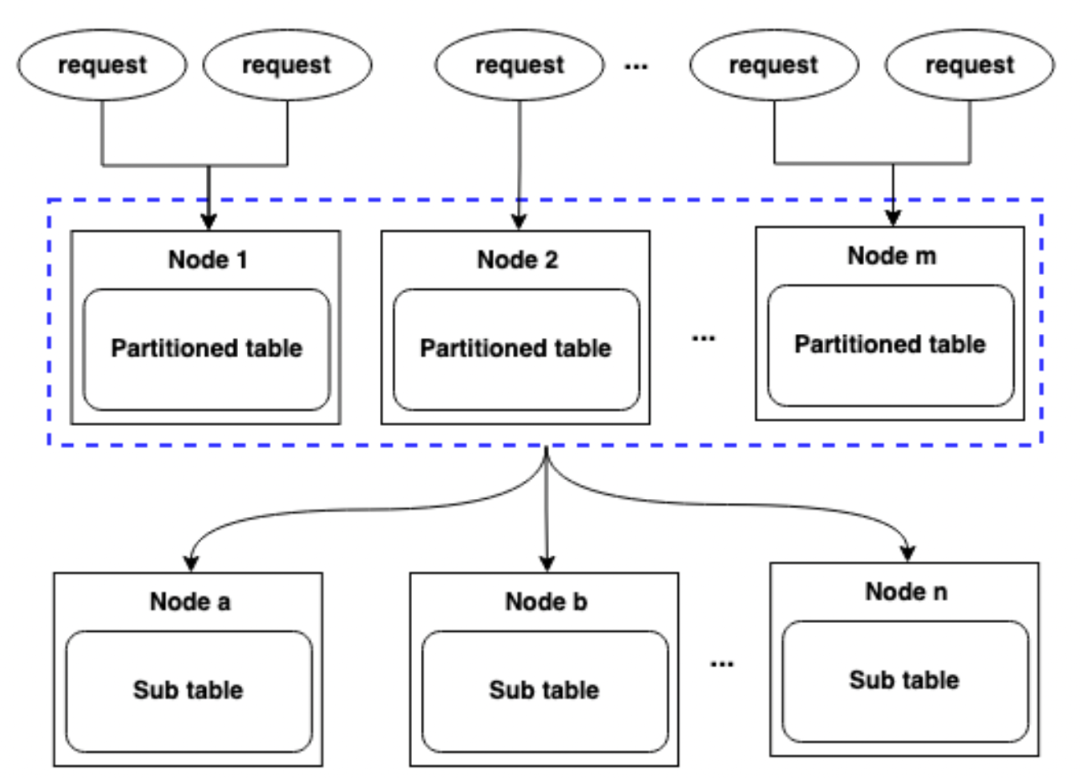
3.5.1 Рисунок 2 – Родительская таблица открывается на всех узлах как виртуальная таблица
3.5.2 Задача оптимизации 2: большой объем сетевых операций ввода-вывода
испытание:
В распределенной системе механизм запросов должен отправлять условия запроса в каждую дочернюю таблицу и агрегировать результаты вычислений на родительском узле. Такой подход может легко привести к чрезмерному объему данных и стать узким местом, особенно при обработке больших таблиц, он может легко вызвать переполнение памяти (OOM) и повлиять на стабильность службы.
Решение:
Чтобы решить эту проблему, мы принимаем стратегию вычислительного сжатия. Вычислительная передача означает максимально возможное выполнение вычислительных задач там, где находятся данные, вместо того, чтобы возвращать все данные обратно в центральный узел для обработки. Например, при выполнении операции суммирования, если в каждой подтаблице имеется 500 000 записей, после вычисления и сжатия в конце может потребоваться вернуть только одну сводную запись. Этот метод значительно уменьшает перемещение данных, уменьшает количество операций ввода-вывода в сети, а также уменьшает объем данных, которые необходимо обработать центральному узлу, тем самым улучшая стабильность сервиса.
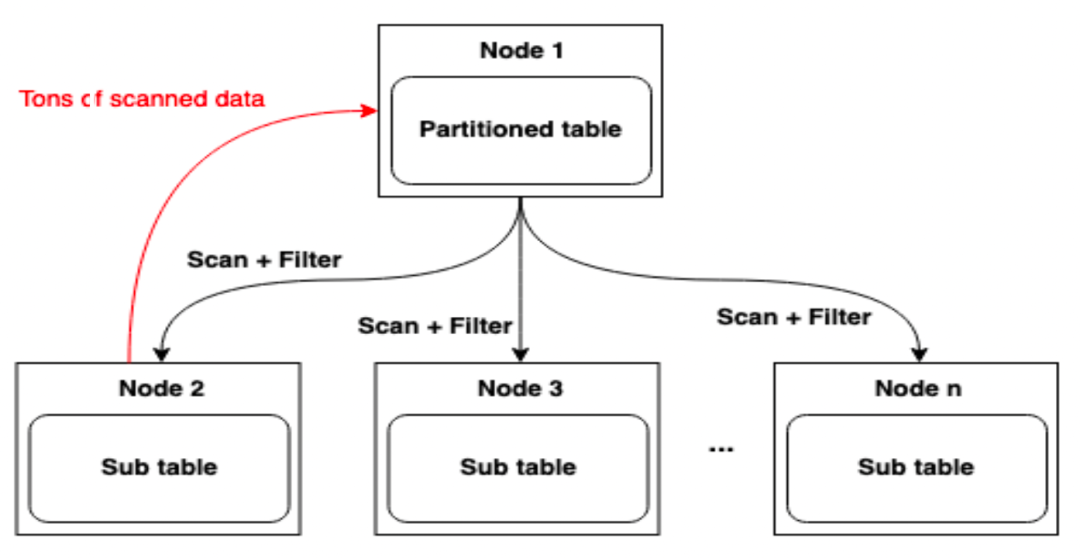
3.5.2 Рисунок 1. Использование стратегии вычисления с понижением для уменьшения количества операций ввода-вывода в сети
3.5.3 Задача оптимизации 3: Оптимизация процесса выполнения SQL
испытание:
Прежде чем мы углубимся в оптимизацию распределенных запросов, нам необходимо понять, как SQL-запросы выполняются в традиционной базе данных. Этот процесс условно можно разделить на три этапа:
- этап синтаксического анализа:первый,Библиотека данных уровня синтаксического анализа (Parser) будет получать пользовательские запросы.,и разобрать его,Создайте абстрактное синтаксическое дерево (AST).
- Этап планирования: следующий, планировщик Модуль основан на библиотеке данных и метаданных (Каталог), включая структуру таблиц и информацию о маршрутизации, для AST Выполните анализ и создайте один или несколько потенциальных планов выполнения запроса.
- Этап исполнения:наконец,Выберите наиболее эффективный план выполнения,Уровень исполнения отвечает за извлечение и получение конкретных данных.
Для секционированных таблиц выполнение запроса включает в себя несколько подтаблиц.
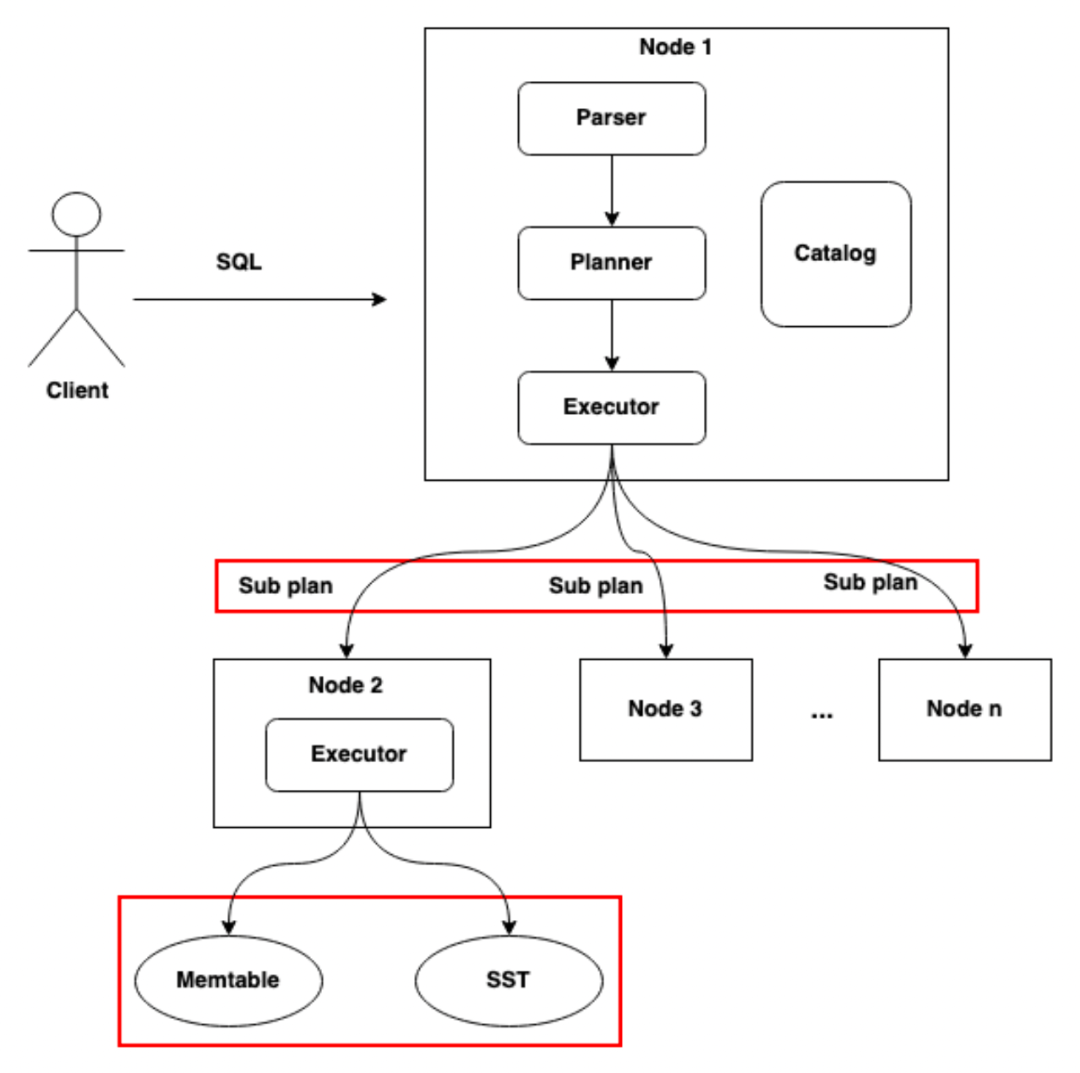
Решение:
Чтобы оптимизировать этот процесс, мы ввели концепцию вычислительного сжатия на этапе генерации запроса. Это означает, что мы переносим как можно большую часть вычислительных задач на уровень подтаблицы для выполнения. Например, когда пользователь выполняет запрос с агрегатной функцией (например, суммой) к многораздельной таблице, система генерирует соответствующее количество подзапросов в зависимости от количества разделов таблицы. Каждый подзапрос обладает вычислительной мощностью, что уменьшает количество подзапросов. данные в родительской таблице и дочерней таблице между ними.
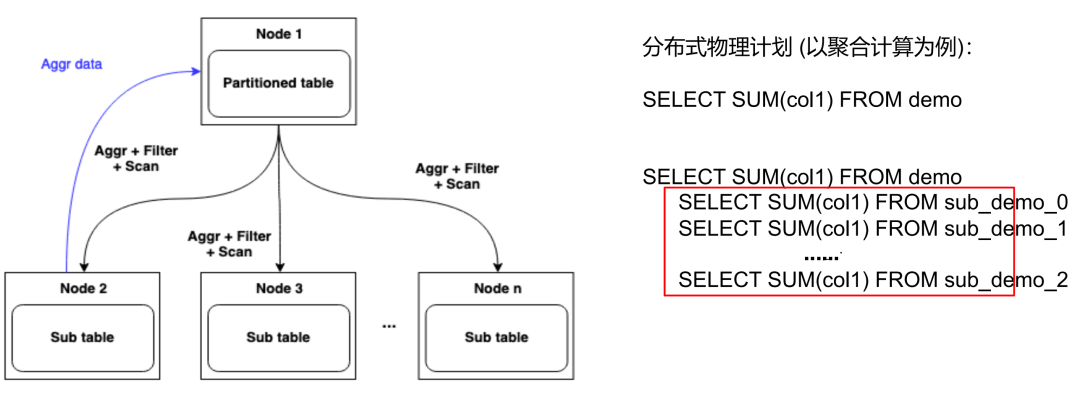
Кроме того, мы не только опускаем данные, но и включаем Filter (условия фильтрации) и различные операторы агрегации, такие как count, max, min, avg и т. д. Такая стратегия оптимизации значительно снижает объем передачи данных между родительской и дочерней таблицами и повышает эффективность запросов.
Эта идея оптимизации широко используется в отрасли, и многие известные системы баз данных, такие как Hbase и TiDB, приняли аналогичные стратегии, хотя они могут использовать другую терминологию. В нашей реальной производственной среде эти меры оптимизации значительно улучшили производительность распределенных запросов, достигнув повышения эффективности примерно в 2–4 раза.
4. Приложение
HoraeDB изначально был создан в рамках Ant Group и широко используется в нашем основном бизнесе. Он поддерживает нашу внутреннюю платформу мониторинга, а также выполняет задачи потоковых вычислений и сценарии инвестиционных исследований, помогая управлять активами и оптимизировать их. В финансовой сфере HoraeDB сочетается с системой мониторинга RMS для обеспечения поддержки банковских операций, демонстрируя свой потенциал и ценность в индустрии финансовых услуг.
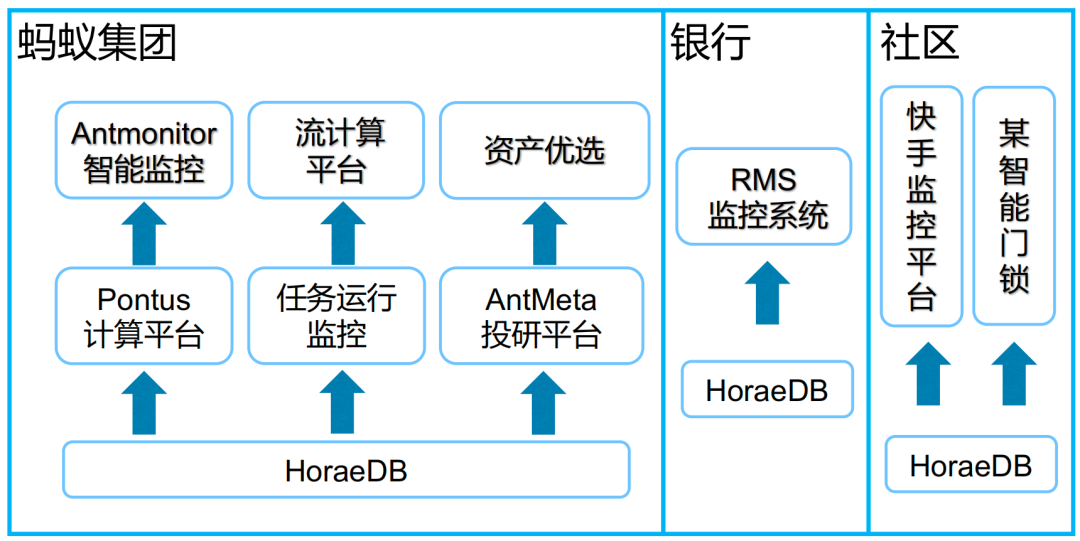
Поскольку исходный код HoraeDB был открытым, мы получили широкую похвалу и признание сообщества. Многие пользователи сообщества обратились к нам и развернули HoraeDB в своих производственных средах. Поскольку это продукт с открытым исходным кодом, весь соответствующий код доступен на GitHub.
Портал:
https://github.com/apache/incubator-horaedb
HoraeDB родился от Ant Group и был официально передан в дар Apache Software Foundation в прошлом году. Мы надеемся, что благодаря инкубации фонда мы сможем не только способствовать дальнейшему развитию HoraeDB, но и устранить всеобщие опасения по поводу устойчивости проекта. Даже если первоначальная команда больше не поддерживает его, проект может продолжать развиваться при поддержке сообщества. (Полный текст заканчивается)
Q&A:
1. Могут ли сроки достичь миллиардного уровня?
2. Приведет ли кеширование распакованных блоков данных к недостаточному использованию кэша? Например, до распаковки можно кэшировать 100 элементов, но после распаковки можно кэшировать только 10 элементов (коэффициент сжатия равен 10).
3. Динамическое расширение. Как новые экземпляры могут быстро получить доступ к данным и обработать их?
4. Как устранить проблемы с производительностью извлечения данных OSS?
Ответы на вышеуказанные вопросы,Добро пожаловать, нажмите“Читать далее”,Смотрите полный ответ!



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
