Анализ стратегий разделения Hive и Spark
Автор: vivo Internet Search Team-Дэн Цзе
С непрерывным развитием технологий появляется все больше технических рамок для хранения и обработки больших объемов данных в сфере больших данных. Наиболее представительными механизмами распределенной обработки в экосистеме автономной обработки данных являются Hive и Spark. У них есть некоторые сходства в стратегиях секционирования, но есть и некоторые различия.
1. Обзор
С непрерывным развитием технологий появляется все больше технических рамок для хранения и обработки больших объемов данных в сфере больших данных. Наиболее представительными механизмами распределенной обработки в экосистеме автономной обработки данных являются Hive и Spark. У них есть некоторые сходства в стратегиях секционирования, но есть и некоторые В этой статье будут проанализированы Hive и Искровая. Сходства и различия стратегий перегородки, их преимущества и недостатки, а также некоторые меры по оптимизации.
2. Концепции разделов Hive и Spark
Прежде чем разобраться в содержимом разделов Hive и Spark, давайте сначала рассмотрим концепции разделов Hive и Spark. В Hive секционирование означает разделение данных в таблице на разные каталоги или подкаталоги. Имена этих каталогов или подкаталогов обычно связаны с именами столбцов таблицы. Например, таблицу с именем «t_orders_name» можно разделить на несколько каталогов по дате, и каждое имя каталога соответствует значению даты. Преимущество этого подхода заключается в том, что он может значительно повысить эффективность запросов, поскольку только запросы, связанные с конкретными датами, должны сканировать соответствующий каталог, а не всю таблицу. Концепция секционирования Spark похожа на Hive, но есть некоторые различия, о которых мы поговорим позже.
В Hive секционирование можно выполнить на основе нескольких столбцов, значения которых объединяются для формирования имени каталога. Например, если мы разделим таблицу «t_orders_name» по дате и региону, то имя каталога будет содержать комбинацию значений даты и региона. В Hive данные хранятся в каталоге раздела, а не в каталоге таблицы. Это позволяет Hive быстро получать доступ к необходимым данным без необходимости сканирования всей таблицы. Кроме того, для группировки данных можно использовать концепцию секционирования Hive, которая заключается в разделении данных в таблице на фиксированное количество сегментов, каждый из которых содержит одинаковые строки.
В отличие от Hive, секционирование Spark делит данные на небольшие фрагменты для параллельных вычислений и обработки. В Spark количество разделов автоматически рассчитывается механизмом выполнения Spark на основе размера данных и аппаратных ресурсов. Чем больше разделов имеет Spark, тем больше данных можно обрабатывать параллельно, поэтому вычислительные задачи можно выполнять быстрее. Однако если количество разделов слишком велико, это приведет к чрезмерному планированию задач и накладным расходам на передачу данных, тем самым снижая общую производительность. Таким образом, при выборе количества разделов Spark следует учитывать такие факторы, как размер данных, аппаратные ресурсы и сложность вычислительной задачи.
3. Сценарии применения разделов Hive и Spark
Поняв концепции секционирования Hive и Spark, давайте рассмотрим различные преимущества секционирования Hive и Spark в различных сценариях приложений.
3.1 Раздел улья
Секционирование Hive подходит для сценариев с большими данными. Оно может выполнять многоуровневое секционирование данных для более детального разделения данных и повышения эффективности запросов. Например, данные пополнения баланса игровой платформы могут быть разделены по нескольким измерениям, таким как дата покупки предмета, статус оплаты предмета и идентификатор пользователя игры. Это может облегчить статистику данных, анализ и операции запроса, избегая при этом проблем с производительностью, вызванных чрезмерным количеством данных в одном разделе.
3.2 Искровая перегородка
Секционирование Spark подходит для крупномасштабных сценариев обработки данных и позволяет полностью использовать ресурсы кластера для параллельных вычислений и обработки. Например, в процессе обучения алгоритма машинного обучения можно разделить большой объем данных, а затем данные каждого раздела можно обрабатывать параллельно, тем самым улучшая скорость обучения и эффективность алгоритма. Кроме того, механизм распределенных вычислений Spark также может поддерживать секционирование и вычисления данных на нескольких узлах, тем самым повышая вычислительную мощность и эффективность всего кластера.
Короче говоря, разделы Hive и Spark широко используются в сценариях обработки больших данных и распределенных вычислений. Путем выбора соответствующих стратегий секционирования и мер оптимизации можно еще больше повысить эффективность и производительность обработки данных.
4. Как выбрать стратегию разбиения
После ознакомления с концепциями секционирования и сценариями применения Hive и Spark. Далее давайте посмотрим, как выбрать стратегию секционирования в Hive и Spark. Выбор стратегии секционирования оказывает важное влияние на эффективность и производительность обработки данных. Ниже будут объяснены преимущества и недостатки стратегий разделения Hive и Spark, а также способы выбора стратегии разделения.
4.1 Стратегия разделения улья
преимущество:
Стратегия секционирования Hive может повысить эффективность запросов и производительность обработки данных, особенно для больших наборов данных. Кроме того, Hive также поддерживает многоуровневое секционирование, что позволяет более детально разделить данные.
недостаток:
В Hive разделы существуют в виде каталогов, что приводит к большому количеству каталогов и подкаталогов. Если разделов слишком много, будет занято слишком много места для хранения. Кроме того, при создании таблицы необходимо установить стратегию секционирования Hive. Если распределение данных изменится, стратегию секционирования необходимо сбросить.
4.2 Стратегия разделения Spark
преимущество:
Стратегия секционирования Spark может автоматически рассчитывать количество секций в зависимости от размера данных и аппаратных ресурсов, что позволяет обрабатывать вычислительные задачи параллельно, тем самым повышая эффективность и производительность обработки.
недостаток:
Если количество разделов установлено неправильно, это приведет к чрезмерному планированию задач и накладным расходам на передачу данных, что повлияет на общую производительность. Кроме того, стратегию секционирования Spark также необходимо корректировать с учетом таких факторов, как размер данных, аппаратные ресурсы и сложность вычислительных задач.
4.3 Выбор стратегии разделения
В реальной разработке и использовании проекта выбор подходящей стратегии секционирования может значительно повысить эффективность и производительность обработки данных. Однако выбор стратегии разделения необходимо учитывать в зависимости от конкретных обстоятельств. Вот несколько сценариев выбора стратегии разделения:
Размер набора данных:Если набор данных больше,Вы можете рассмотреть возможность использования стратегии многоуровневого секционирования Hive.,Для более детального разделения данных,Повышение эффективности запросов. Если набор данных меньше,Стратегии разделения можно автоматически рассчитать с помощью Spark.,Чтобы в полной мере использовать аппаратные ресурсы и повысить эффективность вычислений. Рассчитайте сложность задачи:Если задача расчета более сложная,Например, необходимо выполнить несколько операций JOIN.,Вы можете использовать стратегию группировки Hive.,для ускорения доступа к данным,уменьшатьJOINНакладные расходы на операцию。 Аппаратные ресурсы:При выборе стратегии разделения также необходимо учитывать ограничения аппаратных ресурсов.。Если аппаратных ресурсов достаточно,Количество разделов может быть увеличено для повышения эффективности вычислений. Если аппаратные ресурсы ограничены,Количество разделов необходимо уменьшить, чтобы избежать накладных расходов на планирование задач и передачу данных.
Таким образом, выбор подходящей стратегии разделения необходимо учитывать с учетом конкретных обстоятельств, включая такие факторы, как размер набора данных, сложность вычислительных задач и аппаратные ресурсы. В реальных условиях оптимальную стратегию разделения можно найти путем экспериментирования и отладки.
5. Как оптимизировать производительность раздела
Помимо выбора подходящей стратегии секционирования, можно предпринять некоторые меры по оптимизации для дальнейшего повышения производительности секционирования. В Spark большинство задач Spark можно выразить в три этапа: чтение входных данных, обработка с помощью Spark и обслуживание выходных данных. Хотя фактическая обработка данных Spark в основном происходит в памяти, Spark использует данные, хранящиеся в HDFS, в качестве входных и выходных данных. Планирование и выполнение задач будут использовать большой объем операций ввода-вывода, и существует узкое место в производительности.
Данные раздела Hive хранятся в HDFS. Однако HDFS не очень удобна для поддержки большого количества небольших файлов, поскольку каждый файл имеет около 150 байт служебных данных в памяти каждого узла NameNode, а количество операций ввода-вывода в секунду всего кластера HDFS равно. верхний предел. Пиковая запись файла создает узкие места в производительности в определенных частях инфраструктуры кластера HDFS.
5.1 Оптимизация производительности за счет уменьшения пропускной способности ввода-вывода
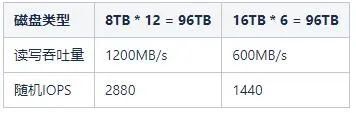
В кластере Hadoop он использует массовый параллельный ввод-вывод для поддержки тысяч одновременных задач. Например, существует узел данных размером 96 ТБ. Есть два размера дисков: 8 ТБ и 16 ТБ. Узел данных с дисками емкостью 8 ТБ имеет 12 таких дисков, а узел данных с дисками емкостью 16 ТБ — 6 таких дисков. Мы можем предположить, что средняя пропускная способность чтения и записи каждого диска составляет около 100 МБ/с, и эти два разных распределения дисков, соответствующая им пропускная способность и количество операций ввода-вывода в секунду, конкретные детали показаны в следующей таблице:
5.2 Оптимизация производительности путем настройки параметров
В кластере Hadoop каждый узел данных запускает сканер томов для каждого тома, который сканирует состояние блоков. Поскольку сканеры томов конкурируют с приложениями за дисковые ресурсы, важно ограничить пропускную способность их дисков. Настройте значение свойства dfs.block.scanner.volume.bytes.per.sec, чтобы определить количество байтов, которые сканер томов может сканировать в секунду. Значение по умолчанию — 1 МБ/с.
Например, если пропускная способность установлена на 5 МБ/с, время, необходимое для сканирования 12 ТБ, составит
12ТБ/5МБ/с = (12*1024*1024/(3600*24)) = 29,13 дней.
5.3 Повышение производительности за счет оптимизации Spark для обработки задач разделов
Если теперь вам необходимо пересчитать таблицу данных исторического раздела, этот сценарий обычно используется для исправления ошибок или проблем с качеством данных. При обработке больших наборов данных (например, более 1 ТБ), содержащих данные за один год, данные можно разделить на тысячи разделов Spark для обработки. Хотя на первый взгляд этот метод обработки не является самым подходящим, использование динамического секционирования и запись результатов данных в таблицу Hive, секционированную по дате, приведет к созданию до миллионов файлов.
Затем мы уменьшаем количество разделов задач. Сейчас у нас есть задача Spark, содержащая 3 раздела, и мы хотим записать данные в таблицу Hive, содержащую 3 раздела. В этом случае требуется отправить 3 файла в HDFS, при этом все данные будут храниться в одном файле для каждого раздела. В конечном итоге будет создано 9 файлов, и в каждом файле будет 1 запись. При записи в таблицу Hive с использованием динамического секционирования каждый раздел Spark обрабатывается исполнителем параллельно.
При обработке данных раздела Spark каждый раз, когда исполнитель встречает новый раздел внутри данного раздела Spark, он открывает новый файл. По умолчанию Spark использует для данных разделители Hash или Round Robin. При применении к произвольным данным можно предположить, что оба метода распределяют данные относительно равномерно и случайным образом по всему разделу Spark. Как показано ниже:

В идеале размер целевого файла должен быть примерно кратен размеру блока HDFS, который по умолчанию составляет 128 МБ. В Hive предусмотрены некоторые параметры конфигурации для автоматической записи результатов в файлы разумного размера, что почти прозрачно с точки зрения разработчика, например установка свойств hive.merge.smallfiles.avgsize и hive.merge.size.per.task. Однако в Spark такой функциональности нет, поэтому нам нужно разработать собственную реализацию, чтобы определить, сколько файлов следует записать для набора данных.
5.3.1 Расчеты на основе размера
Теоретически это самый простой подход: установите целевой размер, оцените размер данных, а затем разделите их. Однако во многих случаях файл сжимается при записи на диск, и его формат отличается от формата записи, хранящейся в куче Java. Это означает, что оценка размера записи в памяти при записи на диск — непростая задача. Хотя можно оценить по размеру данных в памяти с помощью приложения Spark SizeEstimator. Однако SizeEstimator учитывает внутреннее потребление кадров и наборов данных, а также размер данных. Вообще говоря, этот метод нелегко реализовать точно.
5.3.2 Расчет на основе количества строк
Этот подход заключается в том, чтобы установить целевое количество строк, вычислить размер набора данных, а затем выполнить деление для оценки целевого значения. Целевое количество строк можно определить несколькими способами: либо выбрав статическое число для всех наборов данных, либо определив размер одной записи на диске и выполнив необходимые вычисления. Какой подход является оптимальным, зависит от размера вашего набора данных и его сложности. Вычисления относительно дешевы, но требуют кэширования перед вычислением, чтобы избежать пересчета набора данных.
5.3.3 Расчет статического файла
Самое простое решение — просто попросить разработчика сообщить Spark, сколько файлов всего следует записать для каждой задачи записи. Этот подход должен дать разработчикам другой способ получения конкретных чисел, который может заменить дорогостоящие вычисления.
5.4. Оптимизируйте способ распространения данных Spark для повышения производительности.
Несмотря на то, что мы знаем, как записывать файлы на диск, нам все равно нужно позволить Spark реалистично структурировать наши разделы. В Spark имеется множество инструментов для определения того, как данные распределяются по разделам. Однако в различных функциях скрыта большая сложность, и в некоторых случаях их значение неочевидно. Ниже мы представим некоторые параметры, предоставляемые Spark для управления количеством выходных файлов Spark.
5.4.1 Объединение
Spark Coalesce — это специальная версия переразбиения, которая позволяет только уменьшить общее количество разделов, но не требует полного перемешивания и, следовательно, выполняется намного быстрее, чем переразбиение. Это достигается за счет эффективного объединения разделов. Как показано ниже:
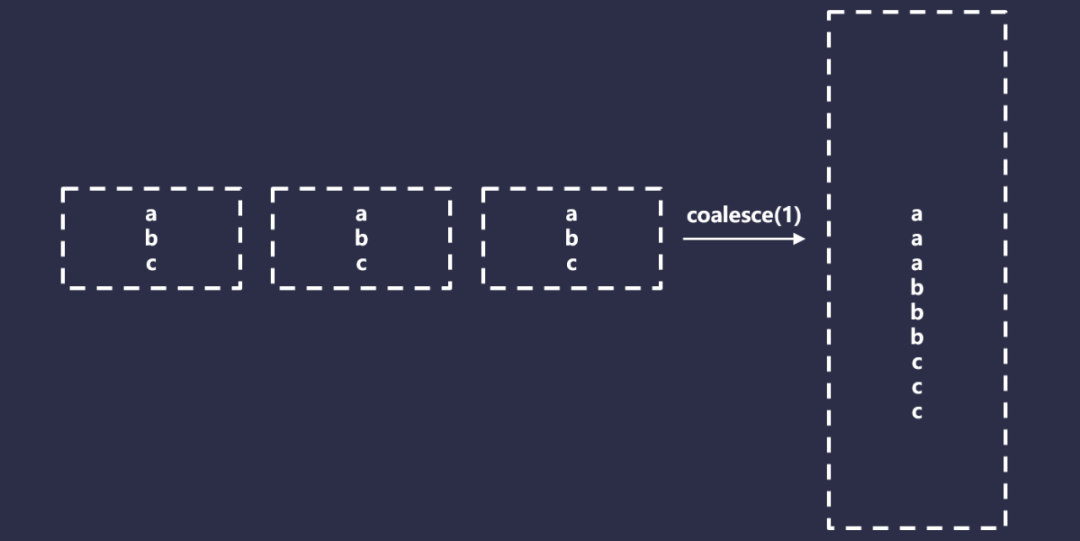
В некоторых ситуациях объединение выглядит хорошо, но у него есть и некоторые проблемы. Во-первых, Coalesce имеет поведение, которое сложно использовать. Если взять в качестве примера очень простое приложение Spark, код выглядит следующим образом:
Spark
load().map(…).filter(…).save()Например, если параметр параллелизма равен 1000, но в итоге вы хотите записать только 10 файлов, вы можете установить его следующим образом:
Spark
load().map(…).filter(…).coalesce(10).save()Однако Spark эффективно завершит операцию слияния как можно раньше, поэтому она будет выполнена в виде следующего кода:
Spark
load().coalesce(10).map(…).filter(…).save()Эффективный способ решить эту проблему — обеспечить принудительное преобразование и слияние. Код выглядит следующим образом:
Spark
val df = load().map(…).filter(…).cache()
df.count()
df.coalesce(10)В Spark кэширование является обязательным, иначе вам придется пересчитывать данные, что может снова потреблять вычислительные ресурсы. Кроме того, для кэширования требуются определенные ресурсы. Если ваш набор данных не может быть помещен в память или память не может быть освобождена для эффективного хранения данных в памяти дважды, то необходимо использовать дисковое кэширование, которое имеет свои ограничения и значительную потерю производительности.
Более того, как мы видели, часто необходимо выполнить перемешивание, чтобы получить желаемые результаты для более сложных наборов данных. Таким образом, Coalesce подходит только для определенных ситуаций, например следующих сценариев:
- Убедитесь, что записан только один раздел Hive;
- Количество целевых файлов меньше количества разделов Spark, которые вы используете для обработки данных;
- Ресурсов кэша достаточно.
5.4.2 Простое перераспределение
В Spark простого перераспределения можно добиться, установив такие параметры, как df.repartition(100). В этом случае используется циклический секционатор, а это означает, что единственной гарантией является то, что выходные данные имеют разделы Spark примерно одинакового размера, что применимо только к следующим ситуациям:
- Убедитесь, что необходимо записать только один раздел Hive;
- Количество записываемых файлов превышает количество разделов Spark, или по какой-то причине вы не можете использовать слияние.
5.4.3 Перераспределение по столбцу
Перераспределение по столбцу получает количество целевых разделов Spark и последовательность столбцов, которые необходимо перераспределить, например df.repartition(100,$"date"). Это полезно, чтобы заставить Spark распространять данные с одним и тем же ключом в один и тот же раздел. В целом это полезно для многих операций Spark (например, JOIN).
Перераспределение по столбцу использует HashPartitioner для распределения данных с одинаковым значением в один и тот же раздел. Фактически он будет выполнять следующие операции:
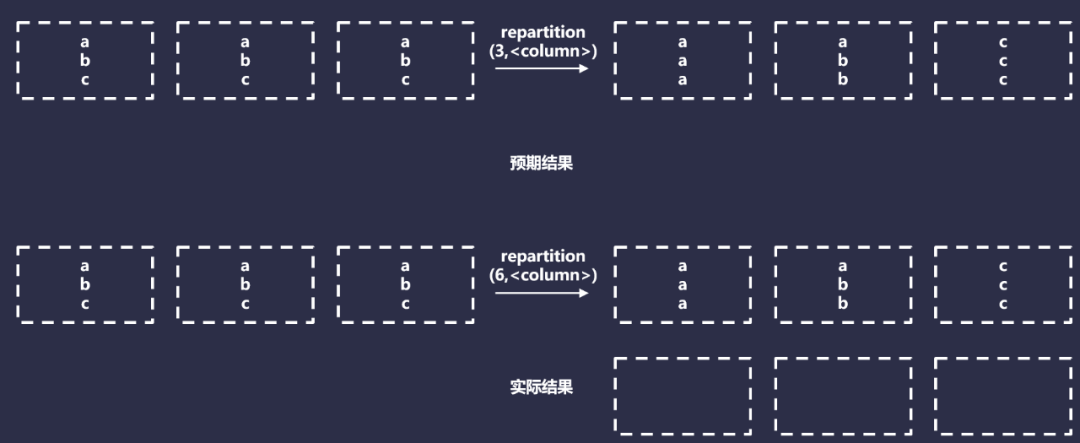
Однако этот подход работает только в том случае, если каждый ключ раздела можно безопасно записать в файл. Это связано с тем, что независимо от того, сколько конкретных значений хеш-функции существует, они окажутся в одном разделе. Перераспределение столбцов работает только в том случае, если вы записываете данные в один или несколько небольших разделов Hive. В любом другом случае это будет неэффективно, поскольку в каждом разделе Hive будет один файл, который будет работать только с наименьшим набором данных.
5.4.4 Перераспределение по столбцам со случайными факторами
Мы можем изменить перераспределение по столбцам, добавив ограниченные случайные факторы. Конкретный код выглядит следующим образом:
Spark
df
.withColumn("rand", rand() % filesPerPartitionKey)
.repartition(100, $"key", $"rand")Теоретически этот подход должен создавать сопоставленные данные и файлы одинакового размера, если соблюдаются следующие условия:
- Разделы Hive примерно одинакового размера;
- Знает количество целевых файлов на раздел Hive и может кодировать их во время выполнения.
Однако даже если мы выполним указанные выше условия, существует еще одна проблема: коллизии хэшей. Предположим, вы обрабатываете данные за один год, используя дату в качестве уникального ключа для раздела. Если для каждого раздела требуется 5 файлов, вы можете выполнить следующие операции кода:
Spark
df.withColumn("rand", rand() % 5).repartition(5*365, $"date", $"rand")на заднем плане,Scala создаст ключ, содержащий дату и случайный фактор.,Например(,<0-4>)。Затем,Если мы посмотрим на код HashPartitioner,Можно обнаружить, что он делает следующее:
Spark
class HashPartitioner(partitions: Int) extends Partitioner {
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
}По сути, это позволяет получить хэш кортежа ключей, а затем получить его мод, используя целевое количество разделов Spark. Мы можем проанализировать, как наши данные будут распределены в этом случае. Конкретный код выглядит следующим образом:
Spark
import java.time.LocalDate
def hashCodeTuple(one: String, two: Int, mod: Int): Int = {
val rawMod = (one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def hashCodeSeq(one: String, two: Int, mod: Int): Int = {
val rawMod = Seq(one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def iteration(numberDS: Int, filesPerPartition: Int): (Double, Double, Double) = {
val hashedRandKeys = (0 to numberDS - 1).map(x => LocalDate.of(2019, 1, 1).plusDays(x)).flatMap(
x => (0 to filesPerPartition - 1).map(y => hashCodeTuple(x.toString, y, filesPerPartition*numberDS))
)
hashedRandKeys.size // Number of unique keys, with the random factor
val groupedHashedKeys = hashedRandKeys.groupBy(identity).view.mapValues(_.size).toSeq
groupedHashedKeys.size // number of actual sPartitions used
val sortedKeyCollisions = groupedHashedKeys.filter(_._2 != 1).sortBy(_._2).reverse
val sortedSevereKeyCollisions = groupedHashedKeys.filter(_._2 > 2).sortBy(_._2).reverse
sortedKeyCollisions.size // number of sPartitions with a hashing collision
// (collisions, occurences)
val collisionCounts = sortedKeyCollisions.map(_._2).groupBy(identity).view.mapValues(_.size).toSeq.sortBy(_._2).reverse
(
groupedHashedKeys.size.toDouble / hashedRandKeys.size.toDouble,
sortedKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble,
sortedSevereKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble
)
}
val results = Seq(
iteration(365, 1),
iteration(365, 5),
iteration(365, 10),
iteration(365, 100),
iteration(365 * 2, 100),
iteration(365 * 5, 100),
iteration(365 * 10, 100)
)
val avgEfficiency = results.map(_._1).sum / results.length
val avgCollisionRate = results.map(_._2).sum / results.length
val avgSevereCollisionRate = results.map(_._3).sum / results.length
(avgEfficiency, avgCollisionRate, avgSevereCollisionRate) // 63.2%, 42%, 12.6%Приведенный выше скрипт вычисляет 3 величины:
- эффективность:непустой Искровая Отношение перегородки к количеству выходных файлов;
- Частота столкновений:(date,rand) хеш-значение для отправки конфликтующей Искровой Процент перегородки;
- Уровень серьезных конфликтов:То же, что и выше,Но количество конфликтов по этому ключу 3 и более.
Конфликты важны, поскольку они означают, что наши разделы Spark содержат несколько уникальных ключей разделов, тогда как мы ожидали, что на каждый раздел Spark будет только один ключ. По результатам анализа мы знаем, что мы используем 63% исполнителей и что могут быть серьезные отклонения. Почти половина наших исполнений обрабатывает в 2–3 раза больше данных, чем ожидалось, а в некоторых случаях и в 8 раз больше данных. .
Теперь есть обходной путь — масштабирование разделов. В предыдущем примере количество выходных разделов Spark было равно ожидаемому общему количеству файлов. Если вы случайным образом назначаете N объектов N слотам, вы можете ожидать, что у вас будет несколько слотов, содержащих несколько объектов, и несколько пустых слотов. Следовательно, для решения этой проблемы необходимо уменьшить соотношение объекта к слоту.
Мы делаем это, масштабируя количество выходных разделов, умножая количество выходных разделов Spark на большой коэффициент, например:
Spark
df
.withColumn("rand", rand() % 5)
.repartition(5*365*SCALING_FACTOR, $"date", $"rand")Конкретный код анализа выглядит следующим образом:
Spark
import java.time.LocalDate
def hashCodeTuple(one: String, two: Int, mod: Int): Int = {
val rawMod = (one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def hashCodeSeq(one: String, two: Int, mod: Int): Int = {
val rawMod = Seq(one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def iteration(numberDS: Int, filesPerPartition: Int, partitionFactor: Int = 1): (Double, Double, Double, Double) = {
val partitionCount = filesPerPartition*numberDS * partitionFactor
val hashedRandKeys = (0 to numberDS - 1).map(x => LocalDate.of(2019, 1, 1).plusDays(x)).flatMap(
x => (0 to filesPerPartition - 1).map(y => hashCodeTuple(x.toString, y, partitionCount))
)
hashedRandKeys.size // Number of unique keys, with the random factor
val groupedHashedKeys = hashedRandKeys.groupBy(identity).view.mapValues(_.size).toSeq
groupedHashedKeys.size // number of unique hashes - and thus, sPartitions with > 0 records
val sortedKeyCollisions = groupedHashedKeys.filter(_._2 != 1).sortBy(_._2).reverse
val sortedSevereKeyCollisions = groupedHashedKeys.filter(_._2 > 2).sortBy(_._2).reverse
sortedKeyCollisions.size // number of sPartitions with a hashing collision
// (collisions, occurences)
val collisionCounts = sortedKeyCollisions.map(_._2).groupBy(identity).view.mapValues(_.size).toSeq.sortBy(_._2).reverse
(
groupedHashedKeys.size.toDouble / partitionCount,
groupedHashedKeys.size.toDouble / hashedRandKeys.size.toDouble,
sortedKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble,
sortedSevereKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble
)
}
// With a scale factor of 1
val results = Seq(
iteration(365, 1),
iteration(365, 5),
iteration(365, 10),
iteration(365, 100),
iteration(365 * 2, 100),
iteration(365 * 5, 100),
iteration(365 * 10, 100)
)
val avgEfficiency = results.map(_._2).sum / results.length // What is the ratio of executors / output files
val avgCollisionRate = results.map(_._3).sum / results.length // What is the average collision rate
val avgSevereCollisionRate = results.map(_._4).sum / results.length // What is the average collision rate where 3 or more hashes collide
(avgEfficiency, avgCollisionRate, avgSevereCollisionRate) // 63.2% Efficiency, 42% collision rate, 12.6% severe collision rate
iteration(365, 5, 2) // 37.7% partitions in-use, 77.4% Efficiency, 24.4% collision rate, 4.2% severe collision rate
iteration(365, 5, 5)
iteration(365, 5, 10)
iteration(365, 5, 100)Поскольку наш масштабный коэффициент приближается к бесконечности, коллизии быстро приближаются к 0, а эффективность приближается к 100%. Однако это создает еще одну проблему: большое количество выходных данных раздела Spark будет пустым. В то же время эти пустые разделы Spark также потребуют некоторых затрат ресурсов. Увеличение размера памяти драйвера облегчит нам проблему неожиданного расширения пространства ключей раздела из-за ненормальных ошибок.
Общий подход здесь заключается в том, чтобы не задавать явно разделение (параллелизм и масштабирование по умолчанию) при использовании этого метода и полагаться на значение Spark по умолчанию spark.default.parallelism, если количество разделов не указано. Хотя обычно степень параллелизма, естественно, превышает общее количество выходных файлов (поэтому неявно предоставляется коэффициент масштабирования больше 1). Этот подход по-прежнему является действительным методом, если выполняются следующие условия:
- Количество файлов в разделе Hive примерно одинаковое;
- Вы можете определить, каким должно быть среднее количество файлов разделов;
- Узнайте приблизительно общее количество уникальных ключей разделов.
5.4.5 Перераспределение по диапазонам
Перераспределение по диапазону — это специальный столбец, который не использует RoundRobin и Hash Partitioner, а использует специальный метод под названием Range Partitioner.
Средство разделения диапазона разделяет строки между разделами Spark на основе порядка некоторых заданных ключей. Однако он выходит за рамки глобальной сортировки и имеет следующие функции:
- Все записи с одинаковым хешем окажутся в одном разделе;
- Все разделы Spark будут иметь связанное с ними минимальное и максимальное значение;
- Минимальные и максимальные значения будут определяться с использованием выборки для обнаружения критических частот и диапазонов, а границы разделов будут изначально установлены на основе этих оценок;
- Точное равенство размеров разделов не гарантируется, их равенство основано на точности выборок, поэтому при прогнозируемых минимальных и максимальных значениях для каждого раздела Spark разделы будут увеличиваться или уменьшаться по мере необходимости, чтобы гарантировать первые два условия.
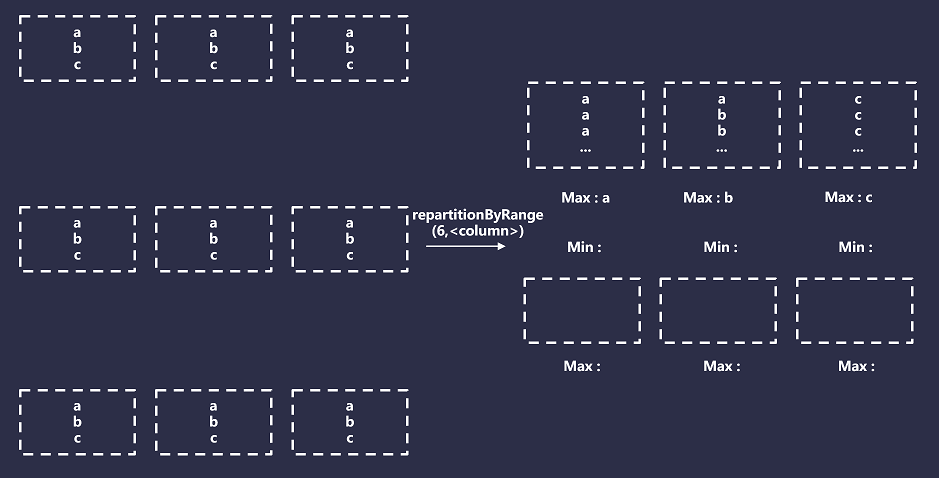
Подводя итог, можно сказать, что секционирование диапазона приведет к тому, что Spark создаст количество сегментов, равное запрошенному количеству разделов Spark, а затем сопоставит эти сегменты с диапазоном указанного ключа раздела. Например, если вашим ключом раздела является дата, диапазон может быть (минимальное значение 2022-01-01, максимальное значение 2023-01-01). Затем для каждой записи ключ раздела записи сравнивается с минимальным и максимальным значениями сегмента хранилища и выделяется соответствующим образом. Как показано ниже:
6. Резюме
При выборе стратегии секционирования вам необходимо сделать выбор, исходя из конкретных сценариев и потребностей приложения. Общие стратегии разделения включают разделение на основе нескольких измерений, таких как время, регион, идентификатор пользователя и т. д. Применяя стратегии секционирования, вы также можете использовать некоторые меры оптимизации для дальнейшего повышения производительности и эффективности секционирования, например, правильно установить количество секций, избежать слишком большого количества столбцов секционирования, уменьшить дублирование данных и т. д.
Короче говоря, секционирование — это очень важная технология в обработке больших данных и распределенных вычислениях. Она может помочь нам лучше управлять и обрабатывать крупномасштабные данные, повысить эффективность и производительность обработки данных и, таким образом, помочь нам лучше справляться с анализом данных и бизнесом. . Проблемы применения.
ссылка:



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
