Анализ состояния работоспособности кластера Elasticsearch и анализ высокочастотных аномальных сценариев
1. Три состояния работоспособности кластера elasticsearch
- Зеленый:Указывает, что кластер находится в хорошем состоянии。Все первичные шарды и реплики обычно распределяются по узлам кластера.,И функционал кластера работает нормально.
- Желтый:Указывает, что кластер частично доступен.。Все первичные шарды обычно распределяются по узлам кластера.,Однако некоторые фрагменты реплик могут не выделяться или работать неправильно из-за некоторых проблем.
- Красный:Указывает, что кластер находится в состоянии недоступности.。На узле кластера не удалось выделить хотя бы один основной сегмент.,Делает связанные индексы недоступными.
Работоспособность кластера elasticsearch определяется путем мониторинга и оценки распределения основных сегментов и реплик в кластере. Проверяя состояние работоспособности, вы можете интуитивно получить текущий статус работы, статус сегментирования и другую информацию о кластере.
2. Как быстро получить статус работоспособности кластера
1. Получить через _cluster API
GET /_cluster/health/<target>Если нагрузка на кластер высока, при запросе состояния работоспособности кластера elasticsearch через API может возникнуть тайм-аут, и состояние работоспособности кластера не может быть получено. Мы можем указать параметр timeout в API, чтобы продлить время запроса. Чтобы получить состояние работоспособности кластера.
В настоящее время API поддерживает следующие параметры:
уровень: мы можем указать уровень для получения статуса работоспособности, который может быть кластером, индексами, сегментами; предоставляется полный детальный уровень состояния работоспособности; Значение по умолчанию — кластер.
локальный: значение true/false. Значение по умолчанию — ложь. Если указано значение true, это означает, что информация для извлечения получается только из локального узла. Если значение по умолчанию равно false, это означает, что возвращаемая информация получена от первичного узла.
master_timeout: таймаут для запроса соединения с главным узлом. Значение по умолчанию — 30 с. При возникновении таймаута будет возвращена информация о таймауте, указывающая, что запрос не выполнен.
таймаут: период ожидания ответа запроса. Значение по умолчанию — 30 с. Если диапазон тайм-аута превышен, будет возвращен период тайм-аута для сбоя запроса.
wait_for_active_shards: указывает, сколько активных сегментов следует ожидать, число, которое ожидает, пока все сегменты в кластере станут активными или не будут ждать. Значение по умолчанию — 0.
wait_for_status: можно использовать для указания состояния ожидающего кластера. Значения параметров: зеленый, желтый, красный.
Когда мы используем для выполнения API по умолчанию, мы получим следующую возвращаемую информацию:
Интерпретация тела возврата:
{
"cluster_name" : "testcluster",#имя кластера
"status" : "yellow",#Состояние здоровья кластера
"timed_out" : false, #Идет ли время ожидания
"number_of_nodes" : 1,#Количество узлов кластера
"number_of_data_nodes" : 1,#Количество узлов данных кластера
"active_primary_shards" : 1,#Количество активных первичных осколков
"active_shards" : 1,#Количество активных шардов
"relocating_shards" : 0,#Количество перемещаемых шардов
"initializing_shards" : 0,#Инициализация количества шардов
"unassigned_shards" : 1,#Количество шардов, которые нельзя выделить
"delayed_unassigned_shards": 0, #Установить количество отложенных фрагментов выделения по таймауту
"number_of_pending_tasks" : 0,#Количество задач в состоянии ожидания
"number_of_in_flight_fetch": 0,#Количество незавершенных задач, которые нужно зафиксировать
"task_max_waiting_in_queue_millis": 0, #время ожидания самого раннего запуска задачи
"active_shards_percent_as_number": 50.0#Количество активных шардов в процентах от общего количества шардов
}2. Получить через _cat API
GET /_cat/healthПосле выполнения этого API вы можете получить следующую возвращаемую информацию:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1475871424 16:17:04 elasticsearch green 1 1 1 1 0 0 0 0 - 100.0%Этот API также может достичь того же эффекта. Он просто поддерживает меньше параметров запроса, чем _cluster.
3. Анализ высокочастотных сценариев аномального состояния работоспособности кластера.
Сценарий 1: количество сегментов кластера достигает верхнего предела, в результате чего сегменты вновь созданного индекса невозможно выделить, что приводит к изменению состояния работоспособности кластера.
Журналы исключений в основном содержат следующее содержимое:
[indices:admin/create]]; nested: IllegalArgumentException[Validation Failed: 1: this action would add [2] total shards, but this cluster currently has [4000]/[4000] maximum shards open;];причина:существоватьelasticsearchв кластере,Существуют ограничения на общее количество шардов, которые могут быть размещены на каждом узле. Когда общее количество шардов на узле достигает верхнего предела,Будет подсказано, что шарды вновь созданного индекса не могут быть выделены узлу. Политика ограничения сегментов в основном направлена на предотвращение чрезмерного распределения шардов. Потому что каждый сегмент индекса потребляет ресурсы ЦП и памяти кластера.
Большинство осколков содержат несколько сегментов. Elasticsearch сохранит метаданные сегмента в куче памяти JVM. По мере увеличения количества сегментов метаданные сегмента, хранящиеся в куче JVM, будут постепенно увеличиваться, что еще больше усугубляет потребление кучи JVM. На данный момент вам необходимо объединить индекс и объединить небольшие сегменты в сегментах в большие сегменты, чтобы улучшить возможности поиска данных и уменьшить потребление памяти кучи JVM.
Решение:
PUT _cluster/settings
{
"persistent":{
"cluster":{
"max_shards_per_node":10000 #Просто настройте в соответствии с реальными потребностями
}
},
"transient":{
"cluster":{
"max_shards_per_node":10000
}
}
}предположение:1GBПоддержка динамической памяти20-30Шардинг более разумен;
Сценарий 2. Повреждение от шардинга приводит к ненормальному состоянию работоспособности кластера.
Журналы исключений в основном содержат следующее содержимое:
index/shard/recovery/prepare_translog] Caused by: org.elasticsearch.index.translog.TranslogCorruptedException: expected shard UUID [57 55 4d 6b 4c 4e 77 53 51 49 2d 31 6a 6a 75 5f 74 70 75 70 35 67] but got: [54 35 69 49 6d 43 70 63 53 61 75 62 4f 65 65 30 6e 6b 6b 57 6c 51] this translog file belongs to a different translog. path:/data1/containers/xxxxxx/es/data/nodes/0/indices/IB9qEdKERzyvWbepTwj4mA/1/translog/translog-1001.tlogпричина:
- Из-за временного сбоя компьютера или неисправности файловой системы осколок поврежден и не может быть выделен узлу.
- Из-за физического повреждения файловой системы или других форс-мажорных обстоятельств.,Вызвать исключение файла транслога,Это, в свою очередь, приводит к осколочным повреждениям.
Когда осколок становится ненормальным, соответствующий ему основной осколок также станет ненормальным. В это время это повлияет на операции чтения и записи индекса кластера.
Решение:
- Повторить выделение фрагментов
#Вызовом _close,_open API Принудительное распределение шардов.
POST /twitter/_close?pretty
POST /twitter/_open?pretty- Выбросить осколки
#Выбросить Действие осколки — это последнее средство в методах восстановления фрагментов. Не используйте без крайней необходимости. После использования это означает удаление данных на осколке.
#Сопутствующее воздействие необходимо тщательно оценить перед использованием.
POST /_cluster/reroute?pretty
{
"commands" : [
{
"allocate_empty_primary" : {
"index" : "{имя индекса}",
"shard" : "{ID осколка}",
"node" : "{имя узла}",
"accept_data_loss": true
}
}
]
}Сценарий 3: выделение сегментов превышает максимальное количество повторов, в результате чего сегменты не распределяются по узлам, что приводит к изменениям в состоянии работоспособности кластера.
Журналы исключений в основном содержат следующее содержимое:
shard has exceeded the maximum number of retries [5]Причина: В большинстве случаев это происходит из-за чрезмерного давления в узле за короткий период времени.,Недолго был офлайн,Приводит к тому, что выделение сегментов превышает максимальное количество повторов.
Решение: В этом случае мы можем вручную запустить задачу выделения шарда после снижения нагрузки на кластер.
POST /_cluster/reroute?retry_failed=trueretry_failed (необязательный, логическое значение) Если true, повторить выделение для сегментов, которые заблокированы из-за слишком большого количества последующих ошибок выделения.
Сценарий 4. Состояние работоспособности кластера меняется из-за частого отключения узла.
Журналы исключений в основном содержат следующее содержимое:
node-left[{bbs-tagdata-es-prd-050201-cvm}{ImUkdwUSRougiS8jdGlh3A}{IuYyXPRWQIa5HqqQz0m5Vw}{10.46.50.201}{10.46.50.201:9300}{ilr}{ml.machine_memory=33565073408, ml.max_open_jobs=20, xpack.installed=true, transform.node=false} reason: disconnected], term: 40, version: 9596, delta: removed {{bbs-tagdata-es-prd-050201-cvm}{ImUkdwUSRougiS8jdGlh3A}{IuYyXPRWQIa5HqqQz0m5Vw}{10.46.50.201}{10.46.50.201:9300}{ilr}{ml.machine_memory=33565073408, ml.max_open_jobs=20, xpack.installed=true, transform.node=false}}
причина:Через анализ журналов,Мы можем обнаружить, что в журнале часто появляются сообщения о выходе/присоединении. Это означает, что текущий узел часто присоединяется к кластеру после выхода. Каждое левое/объединение приведет к инициализации и восстановлению шардов. Заставляет кластер находиться в состоянии восстановления сегмента в течение длительного времени.,Приводит к ненормальному состоянию работоспособности кластера. Если это горячий или холодный кластер, он также может включать в себя задачи перемещения сегментов.
Например:
- Из-за необоснованного планирования сегментирования индекса нагрузка в основном концентрируется на некоторых узлах, когда к индексу поступает большое количество запросов на чтение и запись. В результате нагрузка на узел становится слишком высокой, служба elasticsearch перезапускается, и узел переходит в автономный режим. Обычно, когда происходит перезапуск, мы можем найти в журнале такие ключевые слова, как «перезапуск».
- На узле слишком много осколков. Превышена допустимая нагрузка узла. Время связи между узлом данных и главным узлом истекает, в результате чего главный узел временно исключает узел данных из кластера, что приводит к изменению состояния работоспособности кластера.
- Физический компьютер перезапустился, в результате чего состояние работоспособности кластера стало ненормальным за короткий период времени.
- Давление узла слишком велико, и кластер выходит из строя, что приводит к частому отключению узлов. Вызвать изменения в состоянии работоспособности кластера.
Решение:
PUT _cluster/settings
{
"persistent" : {
"discovery.find_peers_interval": "30s"
},
"transient" : {
"discovery.find_peers_interval": "30s"
}
}В версиях elasticsearch после 7.10.x вы можете в определенной степени избежать исключения узлов из кластера из-за тайм-аута, настроив время обнаружения узла. С точки зрения анализа стабильности разумное планирование индексов и полное использование ресурсов кластера могут фундаментально решить эту проблему.
Идеи анализа:
① Загрузка ЦП слишком высока, и нагрузка продолжает оставаться полной.
Необходимо объединить мониторинг стоек и мониторинг кластера для анализа фактической ситуации текущего бизнеса кластера и состояния кластера, настройки шардинга индекса и т. д. Вы можете использовать GET _tasksAPI для подтверждения текущих основных задач кластера. Затем определите причину высокой загрузки ЦП. Затем предложите пользователю выполнить такие операции, как обновление спецификации узла.
② Использование кучи памяти JVM слишком велико.
Случай 1. Проверьте количество сегментов кластера, соответствующее спецификациям кластера, и определите, может ли текущий кластер содержать существующие сегменты. Если его невозможно перенести, пользователям необходимо предложить удалить фрагменты, чтобы уменьшить нагрузку и обновить характеристики узлов данных.
Случай 2. Объедините журналы кластера и данные мониторинга стойки, чтобы определить конкретную причину сбоя кластера. Если предохранитель вызван чтением и записью. Вы можете сначала попытаться открыть часть пространства памяти вне кучи, чтобы посмотреть, сможет ли это уменьшить нагрузку на память. Приостановите бизнес-доступ на короткий период времени в зависимости от фактической ситуации и дайте кластеру возможность восстановиться. В зависимости от фактического состояния кластера проверьте, необходимы ли обновление и расширение.
Сценарий 5. Файловая система диска доступна только для чтения, что приводит к невозможности выделения сегментов и изменению состояния работоспособности кластера.
Журналы исключений в основном содержат следующее содержимое:
tmp: Read-only file system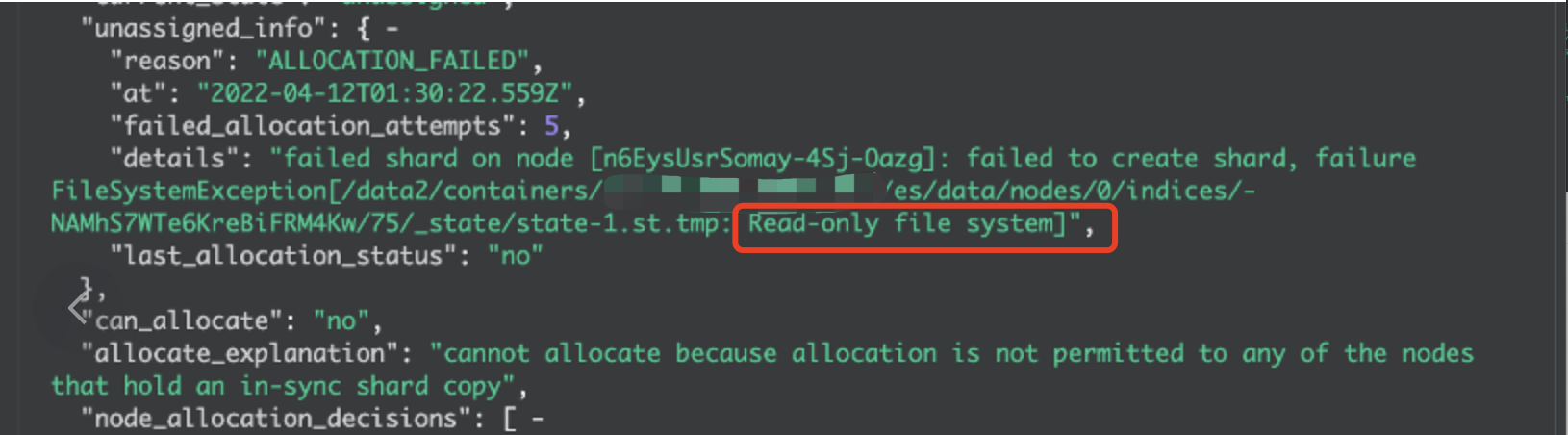
причина:Это может произойти с небольшой вероятностью, когда кластер в течение длительного времени записывает большой объем данных.LinuxФайловая система доступна только для чтения。
Решение:нуждатьсясуществоватьCVMИспользовать в экземпляреfsckКоманда для проверки и восстановления файловой системы,Освободите статус «только для чтения».
ЯсуществоватьучаствоватьНа третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 года будет проводиться конкурс сочинений. Соберите команду, чтобы выиграть приз!



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
