Анализ оптимизации Hive CBO
Предыстория
Hive — это более ранняя версия SQL в системе Hadoop, которая оказывает широкое и далеко идущее влияние на выполнение SQL для больших данных. Первоначально он был разработан Facebook, а затем стал проектом с открытым исходным кодом Apache Software Foundation. Пользователи могут читать, записывать и управлять крупномасштабными наборами данных, хранящимися в распределенных системах хранения, с помощью SQL.
Помимо Hive SQL, Hive Metastore также оказывает большое влияние на систему метаданных систем больших данных и стал фактическим стандартом определения метаданных в области больших данных. И Spark, и Presto расширяют соответствующий каталог Metastore. В последующих статьях Hive Metastore будет подробно описан.
процесс синтаксического анализа
Hive Базовый процесс SQL синтаксического Анализ заключается в следующем: семантический анализ получает дерево операторов дерева логического плана (Оператор Tree),использоватьLogical Optimizer(Optimizer#optimize)Получите оптимальное дерево операторов。
- Parser:ВоляHiveSQLзаявление, основанное наANTLR4Скомпилировано и проанализировано какASTабстрактное синтаксическое дерево ASTNode;
- Semantic Analyzer:на основеSemanticAnalyzer#genResolvedParseTreeметод,Синтаксический анализ в режиме посетителя (ContextVisitor),Рекурсивно пройти по синтаксическому дереву AST.,пройтиdoPhase1иgetMetaDataабстрактныйSQLосновная единицаQB(QueryBlock,то есть подзапрос,блок запроса),QBВключает в себя три части:источник входного сигнала、Процесс расчета、выход;
- Logical Plan Generator:на основеSemanticAnalyzer#genOPTreeметод,Внедрите QB для получения дерева операторов логического плана. Дерево операторов.,Operator(объект дерева операторов)Передача данных представляет собой потоковый процесс.,Отец ОператорОперация будет переданаДетский операторвычислить;
- Logical Optimizer:на основеOptimizer#optimize Дерево логических операторовOperatorОптимизировать,Выполните встроеннуюtransformдействовать,Например: оператор слияния,Сокращение количества выполняемых заданий MapReduce,Уменьшите количество случайного расчесывания,Рассчитать отжимание и т. д.;
- Physical Plan Generator:на основеTaskCompiler#compile,Выполнить глубокую оптимизацию сверху вниз от корневого узла дерева логических операторов. Оператор,Преобразование для создания дерева операторов физического планаTask;
- Physical Optimizer:на основеTaskCompiler#optimizeOperatorPlan Оптимизация физических планов на основе различных механизмов выполнения,TaskCompilerВ настоящее время существуютMapReduceCompiler、SparkCompiler、TezCompiler。

Поток объектов данных, соответствующий синтаксическому анализу SQL, выглядит следующим образом:
- HiveSQL анализируется в объект абстрактного синтаксического дерева ASTNode
- ASTNode преобразован в блок подзапроса QB (QueryBlock)
- QB преобразуется в дерево логического плана оператора для облегчения последующей логической оптимизации реляционной алгебры.
- Оператор преобразуется в дерево физического плана задач для реализации преобразования логического плана в физический план.

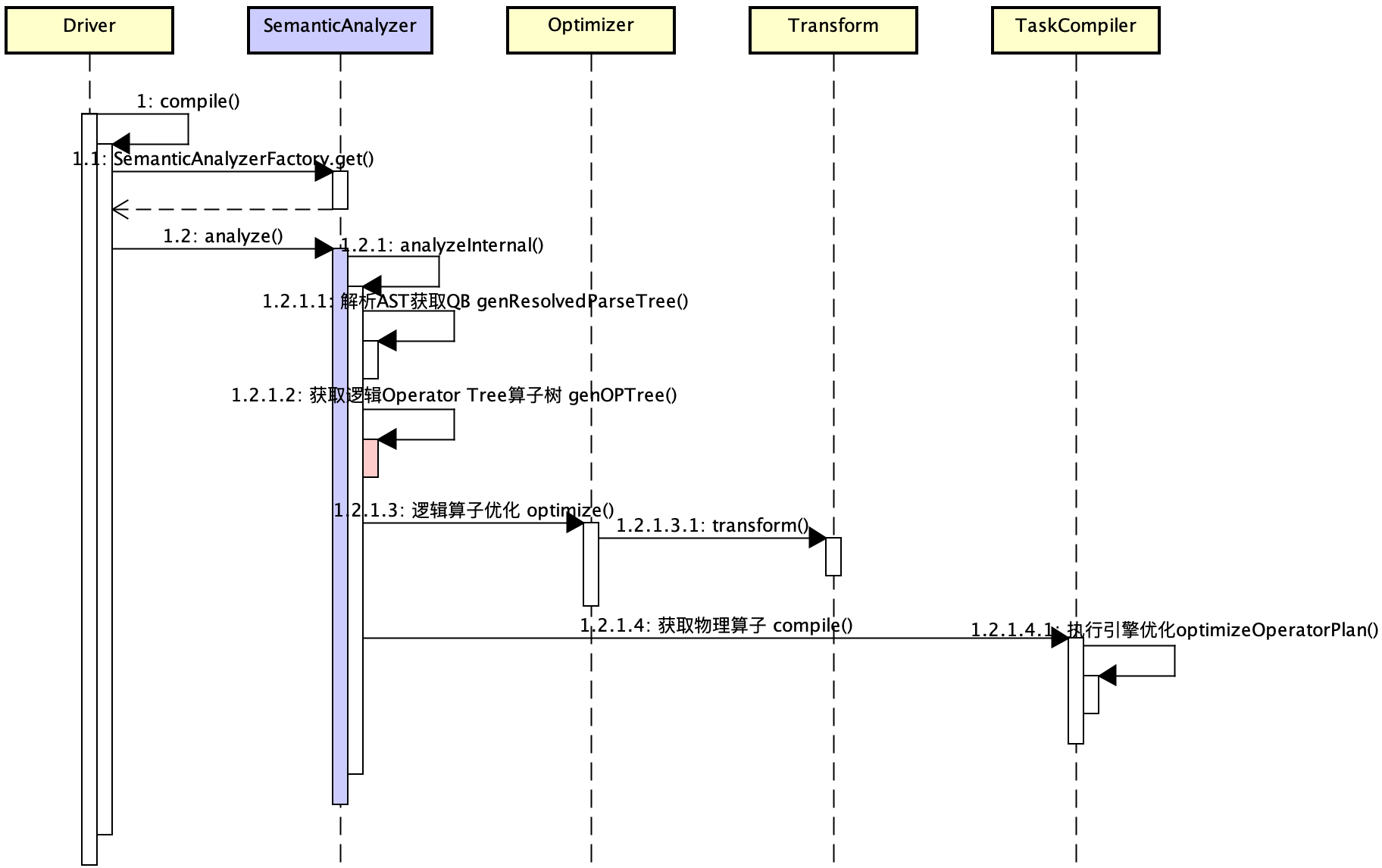
SQLВременная диаграмма анализа и исполнения следующая::Ядро заключается в обработке SemanticAnalyzer.,включать:
- Получите QB на основе AST
- Преобразование в оператор на основе QB, реализация логической оптимизации на основе дерева логического плана (дерева операторов).
- Преобразование в задачу на основе оператора и достижение физической оптимизации на основе дерева физического плана (дерева операторов).
оптимизация CBO
Принцип реализации
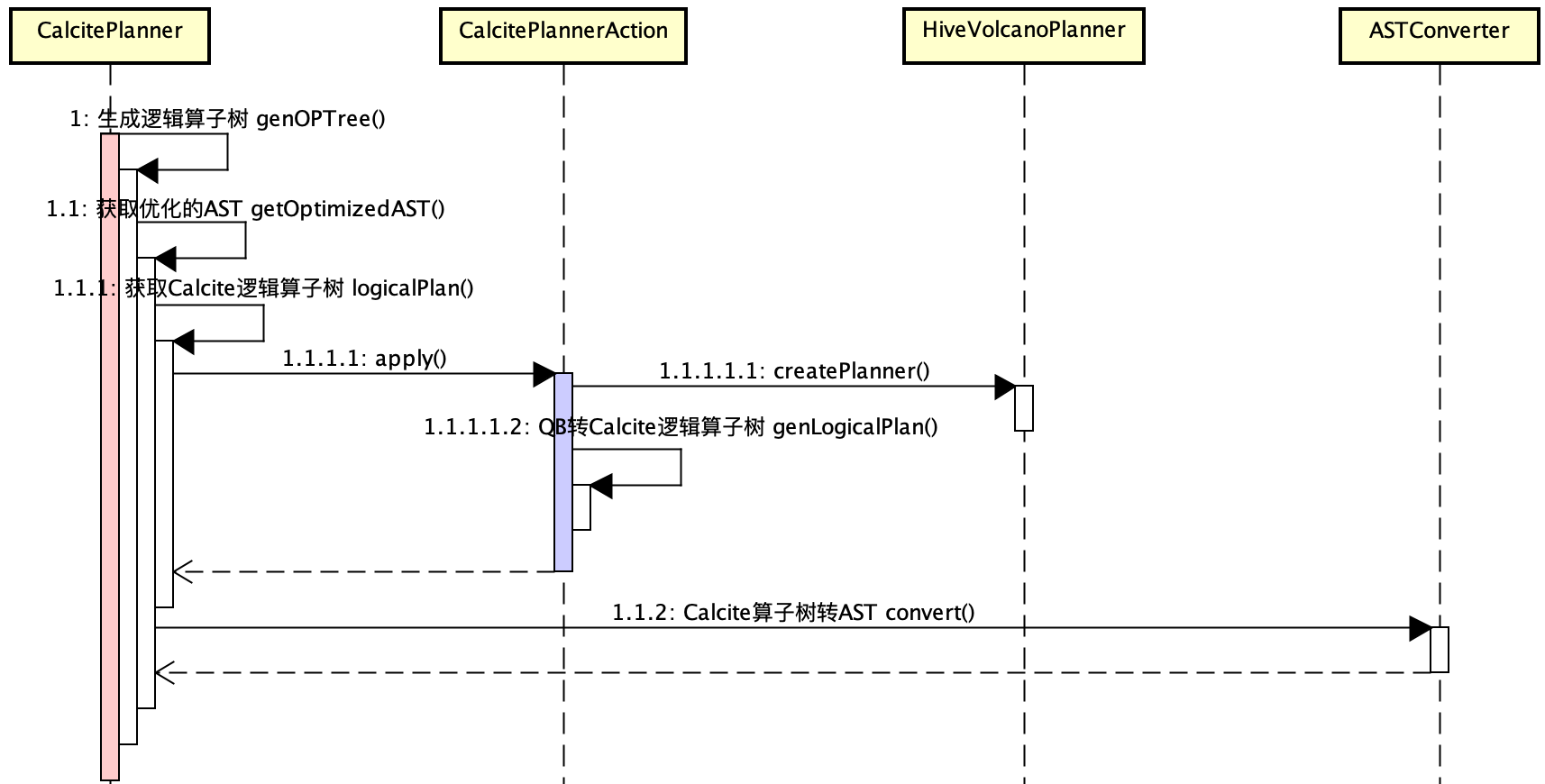
HiveиспользоватьHiveVolcanoPlanner Наследовать родной кальцит VolcanoPlanner выполнитьоптимизация устройство СВО,CalcitePlannerнаследоватьHiveизSemanticAnalyzer(Семантический анализ),Overrideпереписанна основеQBПолучить логическое дерево операторовOperatorизgenOPTreeметод。Временная диаграмма следующая,CalcitePlannerActionвыполнитьCalcite PlannerAction,вызовapplyметод После оптимизацииизCalciteДерево логических операторов RelNode,на основеASTConverterКонвертироватьRelNodeдляHiveиз После оптимизацииизASTNode,на основе После оптимизацииизASTNodeгенерироватьHiveДерево логических операторовOperator,и выполнять последующие операции синтаксического анализа.
CBOизстатистикаи Информация о системесуществоватьсоздаватьCalcitePlannerActionобъект передается в,включать:partitionCache、colStatsCache、columnAccessInfo。
Поток анализируемых объектов данных Hive на основе CBO выглядит следующим образом:
Ядро реализации Hive CBO:существоватьQBизменятьOperatorОбработка расширения во время логического планирования,QB → Calcite оптимизация CBO → Operator。

HiveсерединаRelOptHiveTableрасширение классаCalciteизRelOptTable,Внутреннее поддержание количества строк и статистических значений поля.,Предоставить статистические методы:
- getRowCount: получить количество строк
- getColStat: Получить Поле Статистику,Базовый RPC-интерфейс статистики метаданных вызовов: get_table_statistics_req, get_partitions_statistics_req.
Статистика
Время запуска обновления статистических метаданных должно быть гарантировано для операций ALTER и INSERT. hive.stats.autogather = true;
- ANALYZE:AnalyzeTableCommand、AnalyzeColumnCommand、AnalyzePartitionCommand;
- ALTER:AlterTableMergeFileCommand、TruncateTableCommand;
- INSERT:LoadDataCommand;
Statistics Статистика,ссылка:org.apache.hadoop.hive.ql.plan.Statistics
Поле | Имя поля |
|---|---|
numRows | количество строк |
runTimeNumRows | время выполненияколичество строк |
dataSize | Размер файла данных |
basicStatsState | Статус статистики таблицы: НЕТ, ЧАСТИЧНЫЙ, ПОЛНЫЙ |
columnStats | Поле Статистика,Map<String,ColStatistics> |
columnStatsState | Поле Статистический статус: НЕТ, ЧАСТИЧНЫЙ, ПОЛНЫЙ |
runtimeStats | Разрешена ли статистика |
ColStatistics Полеуровень Статистика
Поле | Имя поля |
|---|---|
colName | Имя поля |
colType | ПолеType |
countDistinct | Статистика количества различных значений Поле |
numNulls | Количество нулей |
avgColLen | Полесредняя длина |
numTrues | Количество истинных |
numFalses | Количество ложных |
range | Поле Максимальный и минимальный диапазон значений |
isPrimaryKey | Это первичный ключ? |
isEstimated | Это ориентировочная стоимость? |
Запрос статистических метаданных:РасширятьCalciteизRelOptTable,вызовHive Metastore RPC-интерфейс для получения метаданных;
Обновления статистических метаданных:
- Статистические метаданные таблиц и разделов: на основе RPC-клиента, вызывающего интерфейс Metastore, alterTable и alterPartitions обновляют соответствующие атрибуты параметров;
- ПолеMetadata: вызов интерфейса Metastore на основе RPC-клиента, setPartitionColumnStatistics. Обновить Статистику Поле/раздела;
АНАЛИЗВыполнение
Hive Статистика CBO в основном получается путем АНАЛИЗВыполнения и соответствующего АНАЛИЗА. Синтаксис определен следующим образом:
ANALYZE TABLE [db_name.]tablename [PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS
[FOR COLUMNS] -- (Note: Hive 0.10.0 and later.)
[CACHE METADATA] -- (Note: Hive 2.1.0 and later.)
[NOSCAN];Выполнение статистических метаданных:использоватьфизические операторыStatsTask,вызовIStatsProcessor#processметод执行元数据статистика,IStatsProcessorвыполнить Подкласс:
- BasicStatsTask: базовая статистика метаданных таблицы.,траверсLocationВнизизHDFSсписок файлов(List<FileStatus>),Подсчитайте общее количество файлов данных и общий размер хранилища.,ЧтосерединаStatsAggregatorСтатистика Краткое содержание,Агрегация статистических результатов по нескольким задачам;
- BasicStatsNoJobTask: статистические операции, которые не запускают выполнение задачи.,Например, файлы данных ORC хранят столбцы Статистика в атрибутах файла.,Этот метод считает быстрее,Запуск многопоточного выполнения файла Сводка статистики;
- ColStatsProcessor: столбцы, статистика для каждого раздела.,на основеFetchOperatorИтеративно прочитать таблицуизданные строки,ColumnStatisticsObjTranslatorруководить Полесорт Статистика Собрать;
Подвести итог
С бурным развитием больших данных вычислительный механизм Hive, как предшественник, постепенно заменяется другими механизмами из-за таких факторов, как ограничения среды выполнения и длительное время выполнения. Однако Hive, являющийся фактическим стандартом SQL в Hadoop, всегда влиял на развитие SQL для больших данных, и большое количество существующих предприятий предприятий построено с использованием Hive SQL.
Автор этой статьи: Предыстория、процесс синтаксического анализа、оптимизация Детали CBO из трёх частей Hive Принцип CBO. Улей Базовый процесс SQL синтаксического Анализ включает в себя синтаксический анализ, семантический анализ, логическую оптимизацию и этапы физической оптимизации. Улей оптимизация CBO полагается на кальцит Реализация оптимизатора модели вулкана. В этой статье представлен соответствующий CBOПринцип. реализация, статистические метаданные CBO и реализация АНАЛИЗВыполнение.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
