Анализ и оптимизация производительности современного процессора. Метод анализа производительности. Модель производительности Roofline.
Модель производительности Roofline — это модель производительности, ориентированная на пропускную способность, которая широко используется в области высокопроизводительных вычислений. Он был разработан в 2009 году в Калифорнийском университете в Беркли. «Линия крыши» в модели означает, что производительность приложения не может превышать возможности машины. Каждая функция и каждый цикл в программе ограничены вычислительным объемом или объемом памяти машины. Эта концепция проиллюстрирована на изображении ниже. Производительность приложения всегда будет ограничена определенной функцией «крыши».
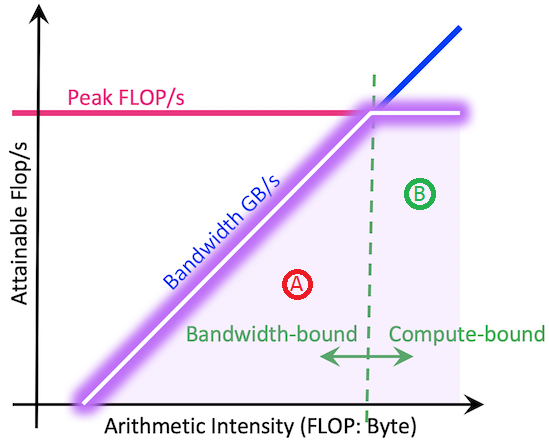
Аппаратное обеспечение имеет два основных ограничения: Скорость вычислений. (Пиковая вычислительная производительность, FLOPS) и скорость перемещения данных (Пиковая пропускная способность памяти, ГБ/с). Максимальная производительность приложения зависит от пика Минимальный предел между FLOPS (горизонтальная линия) и пропускной способностью платформы, умноженной на интенсивность вычислений (диагональная линия). на картинке roofline Диаграмма объединяет два приложения A и B Производительность сравнивалась с аппаратными ограничениями. приложение A требует меньше вычислительных ресурсов, его производительность ограничена пропускной способностью памяти и приложениями. B являются более вычислительно интенсивными,Поэтому на него не будут сильно влиять узкие места памяти. Сходным образом,A и B Может представлять две разные функции в программе и иметь разные характеристики производительности. линия крыши Производительность Модель учитывает это и может отображать несколько индивидуальных функций приложения на одной индивидуальной диаграмме.
Соотношение между арифметической силой (AI) да FLOPS и байтами, которые можно извлечь для каждого индивидуального цикла в программе.
Листинг кода: Наивное параллельное умножение матриц.
void matmul(int N, float a[][2048], float b[][2048], float c[][2048]) {
#pragma omp parallel for
for(int i = 0; i < N; i++) {
for(int j = 0; j < N; j++) {
for(int k = 0; k < N; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
}давайте посчитаем Закодированныйарифметическая сила. Следовательно, в самом внутреннем теле цикла у нас есть одно сложение и одно умножение; 2 индивидуальный ФЛОП. Дополнительно у нас есть три операции чтения и одна операция записи, поэтому переносим; 4 ops * 4 bytes = 16 индивидуальныйбайт。Должен Закодированныйарифметическая силадля 2 / 16 = 0.125。AI даданныйпроизводительность Точка-точка X значение на оси.
Производительность традиционных приложений позволяет максимально эффективно использовать возможности вашей машины. SIMD èМногоядерные возможности. Обычно нам нужно много аспектов: векторизация, память, многопоточность. линия крыши Методы могут помочь оценить эти характеристики приложения. существовать roofline На графике мы можем построить скалярный одноядерный SIMD одноядерный SIMD Теоретический максимум многоядерной производительности
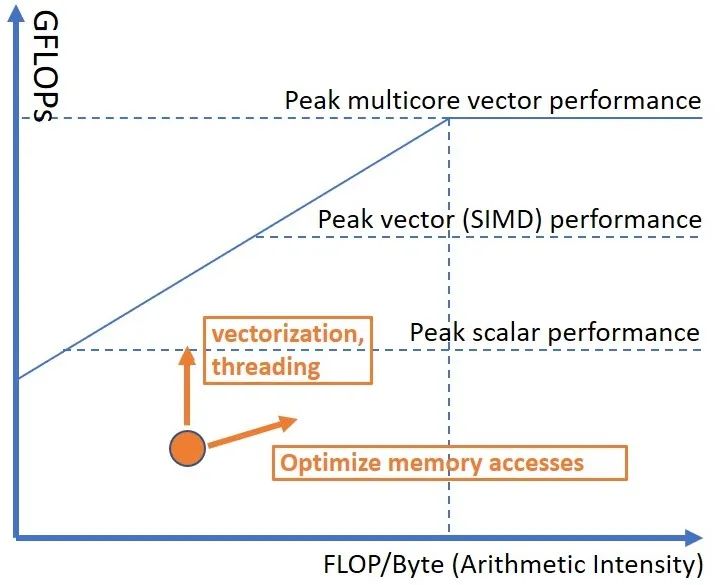
Это позволит нам понять, есть ли возможности для повышения производительности приложения. Если мы обнаружим, что наше приложение ограничено вычислениями (т.е. имеет высокую арифметическую сила) и ниже пиковой скалярной одноядерной производительности, нам следует рассмотреть возможность принудительной векторизации и распределения работы по нескольким отдельным потокам. Напротив, если приложение арифметическое Сильно, мы должны искать способы улучшить доступ к памяти. использовать Roofline Конечная цель Модели оптимизации производительности — поднять эти точки. Векторизация и многопоточность перемещают точку вверх, увеличивая при этом арифметическую силаоптимизация ПамятьAccess переместит точку вправо,А также может улучшить производительность.
Теоретические максимальные значения (линия крыши) обычно указаны в характеристиках оборудования, и с ними легко ознакомиться. Вы также можете рассчитать теоретический максимум, исходя из характеристик используемой машины. Обычно это нетрудно сделать, если знать параметры машины. для Intel Core i5-8259U процессор, использующий AVX2 и 2 индивидуальный Fused Multiply Add (FMA) Максимум единицы FLOP Число (одинарной точности с плавающей запятой) можно вычислить следующим образом:
Пиковое значение FLOPS = 8 (количество логических ядер) × 256 (разрядность AVX) 32 бита (размер с плавающей запятой) × 2 (FMA) × 3,8 ГГц (максимальная турбочастота) = 486,4 GFLOP
Я использовал его для экспериментов Intel NUC Kit NUC8i5BEH Максимальную пропускную способность памяти можно рассчитать следующим образом. Помните, ГДР технология позволяет осуществлять любую передачу доступа к памяти 64 немного или 8 индивидуальныйбайт。
Пиковая пропускная способность памяти = 2400 (скорость передачи данных памяти DDR4) × 2 (каналы памяти) × 8 (байты на доступ к памяти) × 1 (слот) = 38,4 Ги Б/с
картина Empirical Roofline Tool: https://bitbucket.org/berkeleylab/cs-roofline-toolkit/src/master/2 и Intel Advisor: https://software.intel.com/content/www/us/en/develop/tools/advisor.html3 Такие автоматизированные инструменты способны эмпирически определять теоретические максимумы путем запуска набора заранее подготовленных тестов производительности. Более высокая производительность может быть достигнута, если вычисление может повторно использовать данные из кэша. FLOP скорость. линия крыши Этого можно добиться, внедрив специальные roofline чтобы добиться этого(
Как только аппаратные ограничения определены, мы можем начать оценивать приложение относительно roofline производительность. для автоматического сбора Roofline Два наиболее распространенных метода выборки данных (путем likwid: https://github.com/RRZE-HPC/likwid4 Toolsuse) и Binary Instrumentation (от Intel Эмулятор разработки программного обеспечения (SDE: https://software.intel.com/content/www/us/en/develop/articles/intel-software-development-emulator.html5 ) использовать). Выборка требует меньше накладных расходов при сборе данных, а двоичный инструментарий обеспечивает более точные результаты. 6 Intel Advisor Автоматическая сборка Roofline графики и давать советы по оптимизации производительности данного цикла. На рисунке ниже показано Intel Advisor созданный Roofline Пример диаграммы. Обратите внимание, что линия крыши Для диаграммы используйте логарифмический масштаб.
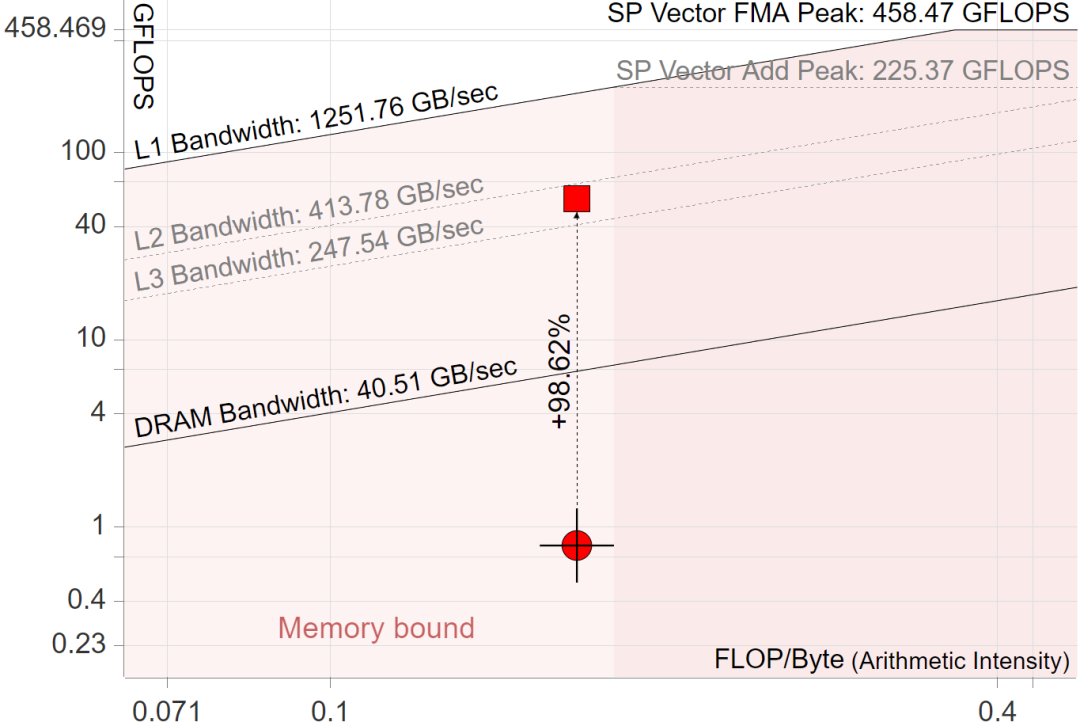
Метод Roofline позволяет отслеживать прогресс оптимизации, печатая точки «до» и «после» на одной и той же индивидуальной диаграмме. поэтому,Это итерационный процесс,Помогите разработчикам помочь своим приложениям в полной мере использовать возможности оборудования. На рисунке показано улучшение производительности, достигнутое за счет внесения следующих двух изменений в предыдущий код:
- Поменяйте местами самые внутренние петли двух лицевых (поменяйте местами 4 и сначала 5 ХОРОШО). Это обеспечивает удобный для кэша доступ к памяти (см. [@sec:MemBound])。
- Включите автовекторизацию самого внутреннего цикла с помощью инструкций AVX2.
Подводя итог, можно сказать, что модель производительности Roofline может помочь:
- идентифицироватьпроизводительностьузкое место。
- Оптимизация программного обеспечения наведения.
- Определите, когда оптимизация закончится.
- Оценка производительности относительно возможностей машины.
Другие ресурсы и ссылки:
- Документация NERSC доступна по адресу https://docs.nersc.gov/development/ Performance-debugging-tools/roofline/.
- Национальная лаборатория исследований Лоуренса Беркли, https://crd.lbl.gov/departments/computer-science/par/research/roofline/
- о Roofline Модельи Intel Advisor Коллекция видеодемонстраций на https://techdecoded.intel.io/. (поиск "Roofline")。
Perfplotиндивидуальная коллекция инструментов сценариев, которая позволяет пользователям выполнять новейшие Intel Платформа измеряет счетчик производительности и генерирует результаты использования. roofline картина ипроизводительность. URL: https://github.com/GeorgOfenbeck/perfplot
2. Empirical Roofline Tool - https://bitbucket.org/berkeleylab/cs-roofline-toolkit/src/master/. ↩
3. Intel Advisor - https://software.intel.com/content/www/us/en/develop/tools/advisor.html. ↩
4. Likwid - https://github.com/RRZE-HPC/likwid. ↩
5. Intel SDE - https://software.intel.com/content/www/us/en/develop/articles/intel-software-development-emulator.html. ↩
6. Более детальное сравнение методов сбора данных о линии крыши можно увидеть в этой презентации: https://crd.lbl.gov/assets/Uploads/ECP20-Roofline-4-cpu.pdf ↩



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
