Алгоритм нейронной сети — функция потерь (Loss Function)
Предисловие
Эта статья начнется сПрирода функции потерь、Принцип функции потерь、алгоритм функции потерьтри аспекта,Подробное введениеФункция потерь Функция потерь。
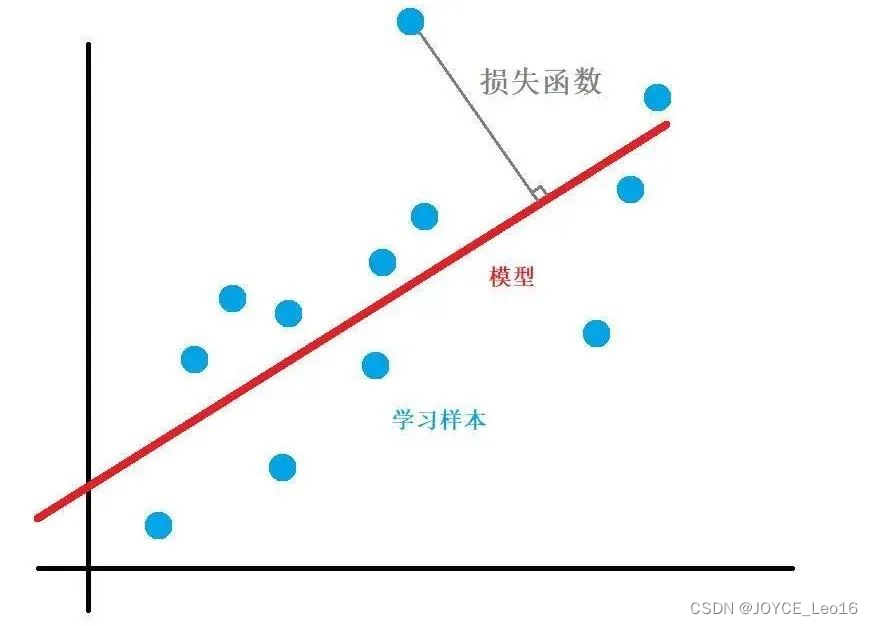
функция потерь
1. Сущность функции потерь
(1) Машинное обучение «три оси»
Выберите семейство моделей, определите функцию потерь для количественной оценки ошибки прогнозирования и найдите оптимальные параметры модели с минимальными потерями с помощью алгоритма оптимизации.
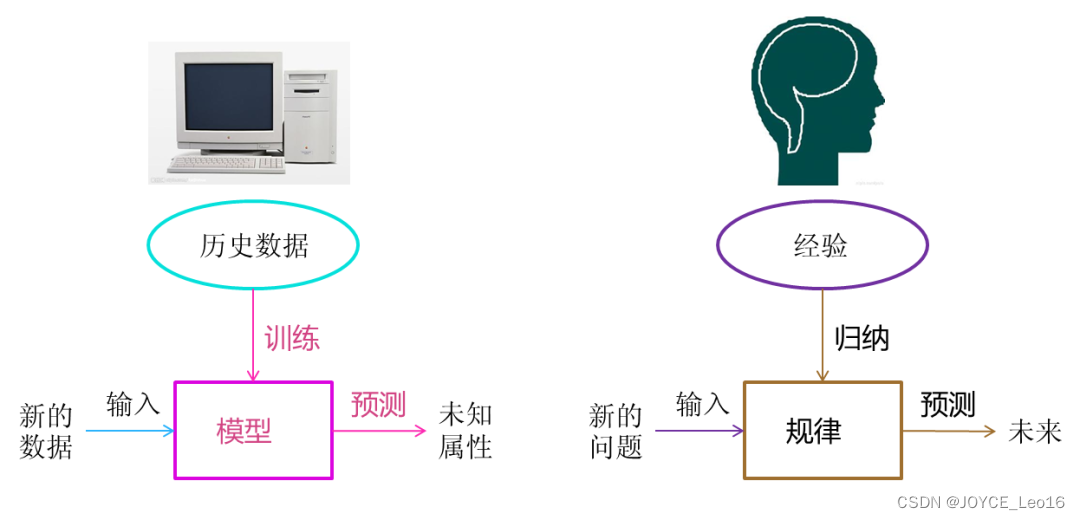
Машинное обучение против человеческого обучения
- Определить набор функций (выбор модели)
Цель:определить подходящее пространство гипотез или Модельсемья。
Пример:Линейная регрессия、логистическая регрессия、нейронная сеть, время принятия решения и т.д.
Факторы, которые следует учитывать:сложность проблемы、характер данных、Вычислительные ресурсы и т.д.
- Определить качество функции (функцию потерь)
Цель:Определите количественную разницу между предсказаниями модели и истинными результатами.
Пример:среднеквадратическая ошибка(MSE)для регресса;Перекрестная потеря энтропии используется для классификации.。
Факторы, которые следует учитывать:характер потери(Выпуклость、дифференцируемость и др.).、Легко оптимизировать、Устойчивость к выбросам и т. д.
- Выберите лучшую функцию (алгоритм оптимизации)
Цель:существоватьфункция Сосредоточьтесь на поиске минимальных потерьфункцияиз Модельпараметр。
Основные методы:Градиентный спуск и его варианты.(стохастический градиентный спуск、пакетный градиентный спуск、Адам и др.).
Факторы, которые следует учитывать:Скорость сходимости、Вычислительная эффективность、Сложность настройки параметров и т.д.
(2) Сущность функции потерь
Определите количественную разницу между предсказаниями модели и истинными результатами.
Природа функции потерь
- Понятие функции потерь:
Функция потерь используется для количественной оценки разницы между предсказаниями модели и истинными значениями.
Это метод расчета разницы между прогнозируемым и реальным значением, инкапсулированный в структуру глубокого обучения (например, PyTorch, TensorFlow).
- Важность функции потерь:
В машинном обучении цель состоит в том, чтобы сделать прогнозируемое значение как можно ближе к истинному значению, поэтому этого необходимо достичь путем минимизации разницы между прогнозируемым значением и истинным значением.
Выбор функции потерь имеет решающее значение для скорости обучения и эффективности модели, поскольку разные функции потерь приведут к разным скоростям градиентного спуска.
- Расположение функции потерь:
Функция потерь находится между прямым и обратным распространением модели машинного обучения.
На этапе прямого распространения модель генерирует прогнозы на основе входных функций.
Функция потерь принимает эти прогнозируемые значения и вычисляет разницу с истинными значениями.
Эта разница затем используется на этапе обратного распространения для обновления параметров модели и уменьшения будущих ошибок прогнозирования.
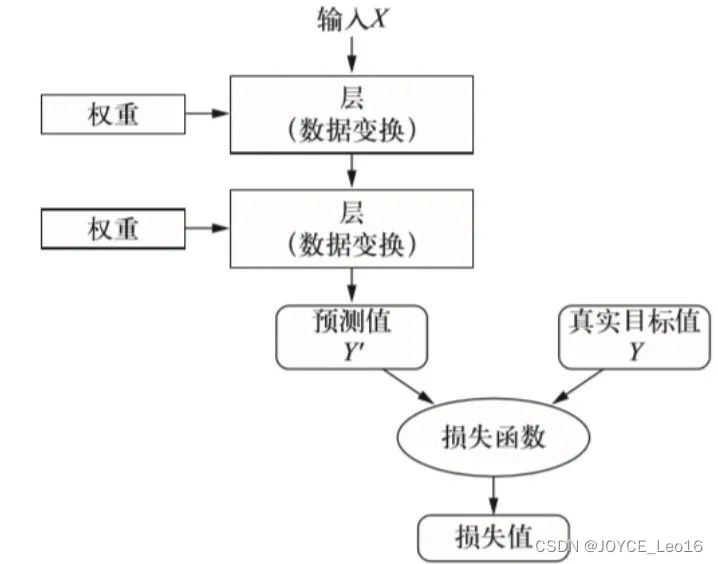
Расположение функции потерь
2. Принцип функции потерь
Ошибка отражает смещение прогноза одной точки данных, а потеря представляет собой сумму смещения прогноза всего набора данных. Функция потерь использует эти два принципа для агрегирования ошибок с целью оптимизации модели и уменьшения общей ошибки прогнозирования.
(1) Ошибка
Разница между прогнозируемым результатом и истинным значением для одной точки данных используется для оценки точности прогнозирования модели в конкретной точке данных.
- определение:
Ошибка относится к разнице или отклонению между результатами прогнозирования модели и истинным значением при прогнозировании одной точки данных. Эта разница отражает неточность или предвзятость прогнозов модели.
- рассчитать:
Погрешность можно рассчитать с помощью различных математических формул. Среди них абсолютная ошибка — это абсолютное значение разницы между прогнозируемым значением и истинным значением, которое используется для количественной оценки фактического отклонения прогноза от истинного значения. Квадрат ошибки — это квадрат разницы между прогнозируемыми значениями; значение и истинное значение, которое часто используется в функции квадратичных потерь, чтобы более заметно выделить более крупные ошибки.
- Столбики ошибок:
Столбики ошибок обычно отображаются в виде линий или прямоугольников выше, ниже или по обе стороны от точки данных, а их длина или размер представляют собой величину ошибки. Этот метод визуализации помогает выявить потенциальные проблемные области и направлять дальнейшие улучшения модели или анализ данных.
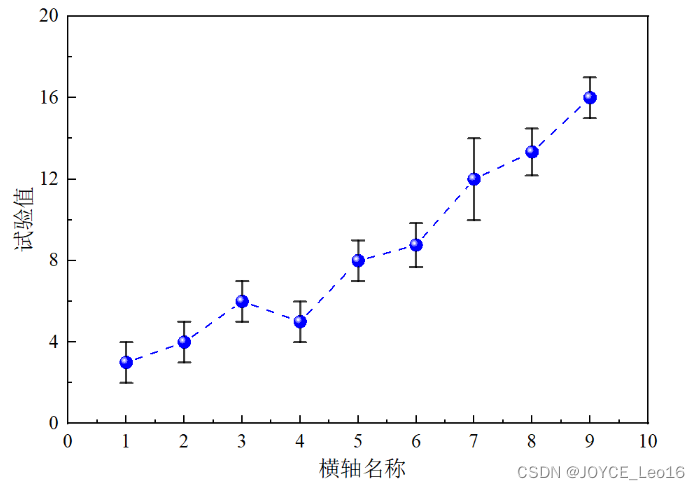
Название горизонтальной оси
(2) Потеря
Потери — это общая мера прогнозной неточности модели машинного обучения по всему набору данных, а минимизация потерь позволяет оптимизировать параметры модели и повысить производительность прогнозирования.
- определение:
Потери измеряются машинное обучение Модельсуществовать Прогнозирование по всему набору данныхизобщая неточностьизиндекс。это отражает Модельмежду прогнозом и фактическим значениемизразница,и объединить эти различия,чтобы предоставить скалярное значение, представляющее общую неточность прогноза。
- рассчитать:
Конкретный расчет потерь осуществляется с помощью функции потерь. Функция потерь принимает прогнозируемые и истинные значения модели в качестве входных данных и выводит скалярное значение, значение потерь, представляющее общую ошибку прогнозирования модели по всему набору данных.
- кривая потерь:
Кривая потерь визуально представляет тенденцию изменения значения потерь модели в процессе обучения. Построив график изменений потерь при обучении и потерь при проверке в зависимости от количества итераций, мы можем получить представление о том, сталкивается ли модель с такими проблемами, как переоснащение или недостаточное оснащение, а затем скорректировать структуру модели и стратегию обучения.
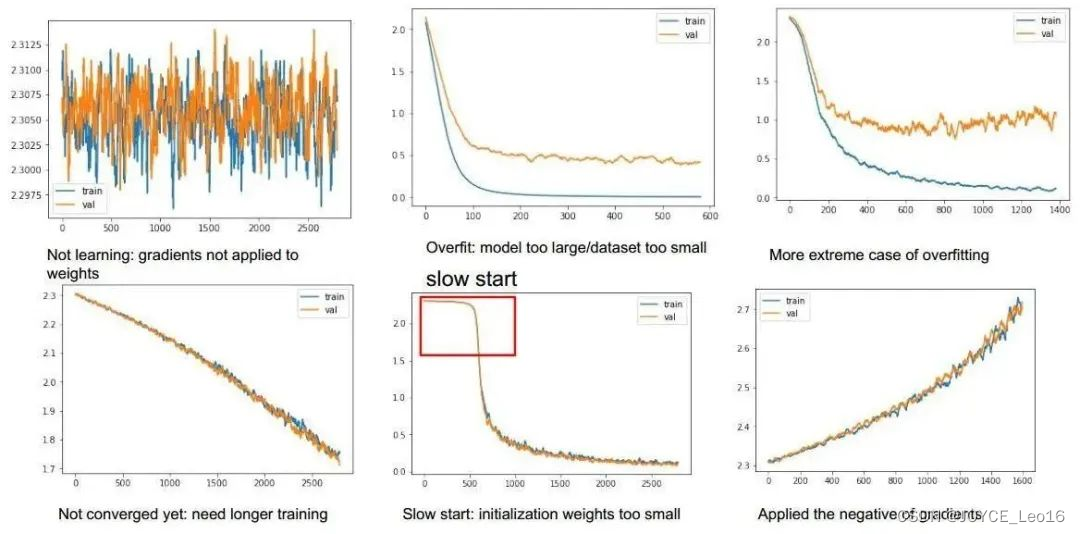
кривая потерь
3. Алгоритм функции потерь
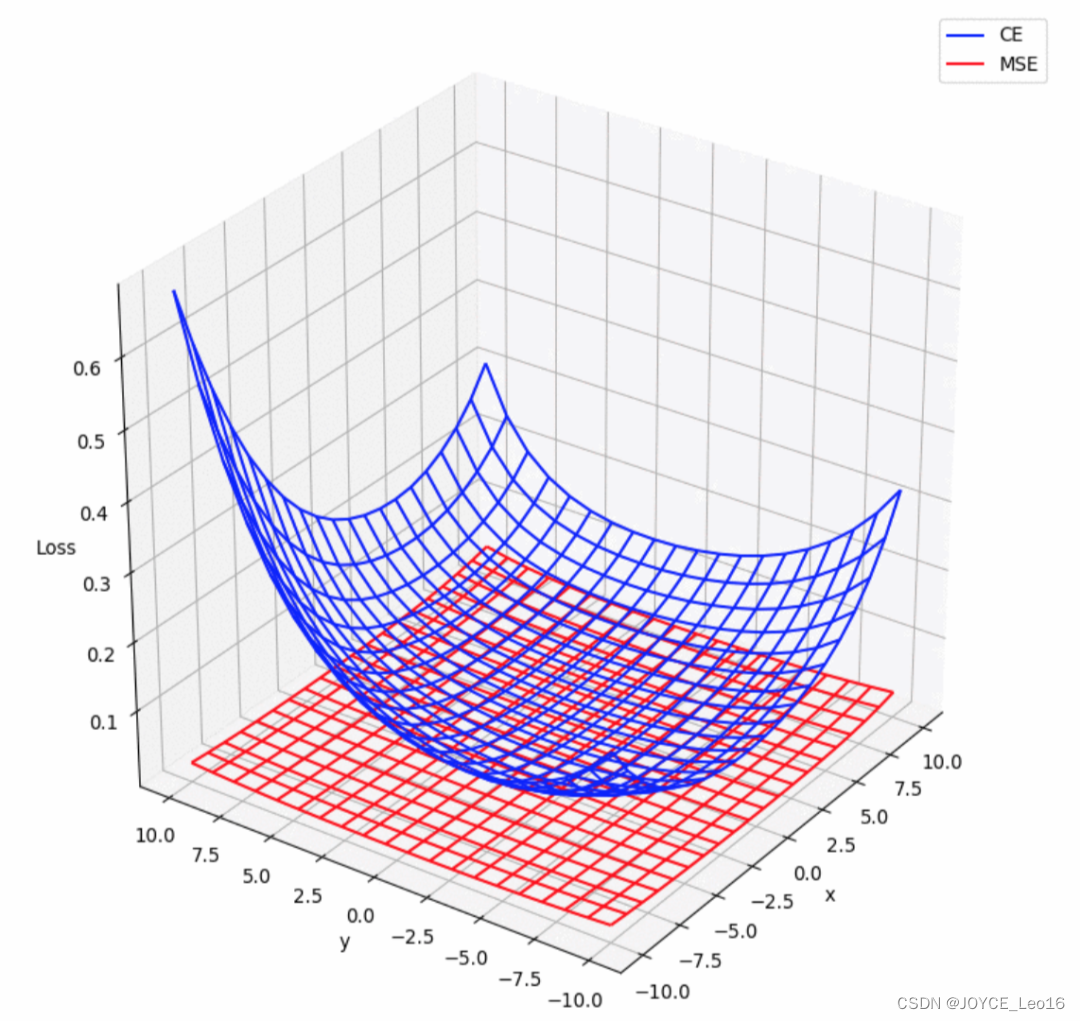
алгоритм функции потерь
(1) Функция потерь среднеквадратической ошибки (MSE)
Точность результатов прогнозирования в задаче регрессии измеряется путем расчета среднего значения квадратов разностей между прогнозируемыми значениями модели и истинными значениями с целью сделать прогнозируемые значения как можно ближе к истинным значениям.
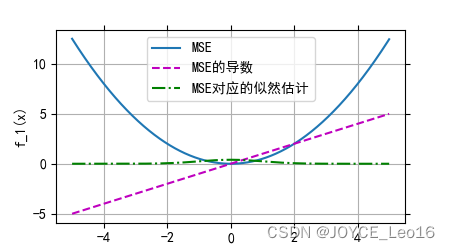
Функция потерь среднеквадратических ошибок (MSE)
- Сценарии применения:
В основном используется в задачах регрессии, т.е. задачах прогнозирования непрерывных значений.
- чиновник:
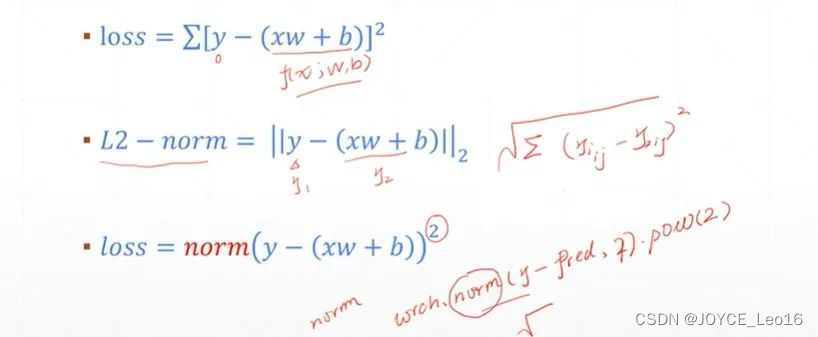
Функция потерь среднеквадратических ошибок (MSE)чиновник
- Функции:
Когда прогнозируемое значение близко к истинному значению, значение потерь меньше.
Когда разница между прогнозируемым значением и фактическим значением велика, значение потерь быстро увеличивается.
Благодаря простой форме градиента его легко оптимизировать.
- Цель оптимизации:
Минимизируйте потери среднеквадратической ошибки, чтобы прогнозируемое значение модели было как можно ближе к истинному значению.
(2) Функция перекрестных энтропийных потерь (CE)
Он используется для измерения разницы между распределением вероятностей, предсказанным моделью, и истинной меткой в задаче классификации с целью приблизить прогноз модели к истинной категории за счет минимизации потерь.
Функция перекрестной энтропийной потери (CE)
- Сценарии применения:
В основном используется для задач классификации, особенно задач мультиклассификации.
- чиновник:
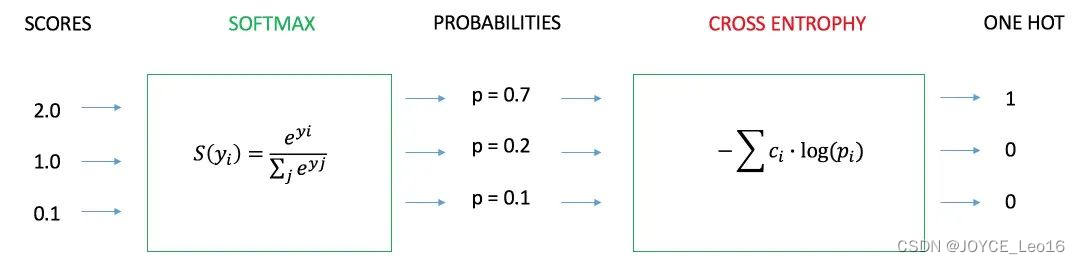
Функция перекрестной энтропийной потери (CE)чиновник
- Функции:
Когда прогнозируемое распределение вероятностей близко к истинному распределению вероятностей, значение потерь невелико.
Очень чувствителен к небольшим изменениям прогнозируемых вероятностей, особенно когда вероятность истинной метки близка к 0 или 1.
Модели, подходящие для вероятностного вывода, такие как логистическая регрессия, классификатор softmax и т. д.
- Цель оптимизации:
Минимизированная потери перекрестной энтропии позволяет прогнозированию модели каждой категории как можно ближе к реальному распределению вероятности.
Ссылка: Architect предлагает вам поиграть с ИИ.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
