8000 слов! Подробное объяснение истории развития, принципов и технической архитектуры ChatGPT, а также будущего индустрии искусственного интеллекта.

Привет всем, это программист Ван Фэн.
1 декабря прошлого года OpenAI запустила прототип чата искусственного интеллекта ChatGPT. В феврале этого года он снова привлек внимание, вызвав большую дискуссию в сообществе ИИ, похожую на то, как AIGC лишила художников безработных.
- 💻ChatGPT + Python одна строка кода
- 📱Интеллектуальный процесс обработки ChatGPT + DingTalk
- ⭐ChatGPT + ExcelАвтоматизированный офис
- 🤖ChatGPT+ развертывается на вашем компьютере по низкой цене.
ChatGPT — это языковая модель, ориентированная на создание диалогов. Он может генерировать соответствующие интеллектуальные ответы на основе ввода текста пользователем.
Этот ответ может быть коротким предложением или длинным заявлением. Среди них GPT — это аббревиатура Generative Pre-trained Transformer (модель генеративного предварительно обученного преобразования).
Обучаясь на основе большого количества готовых коллекций текстов и диалогов (например, Wiki), ChatGPT может мгновенно общаться, как люди, и свободно отвечать на различные вопросы. (Конечно, скорость ответа все еще медленнее, чем у людей) Будь то английский или другие языки (например, китайский, корейский и т. д.), от ответов на исторические вопросы до написания рассказов и даже написания бизнес-планов. и отраслевой анализ «почти» может все. Некоторые программисты даже публиковали в ChatGPT разговоры о модификациях программ.
В нашей группе читательского обмена,Некоторые люди даже упаковали ChatGPT в исполняемый файл, который можно использовать, дважды щелкнув его.,Ссылка на группу👉Нажмите на меня, чтобы перейти напрямую
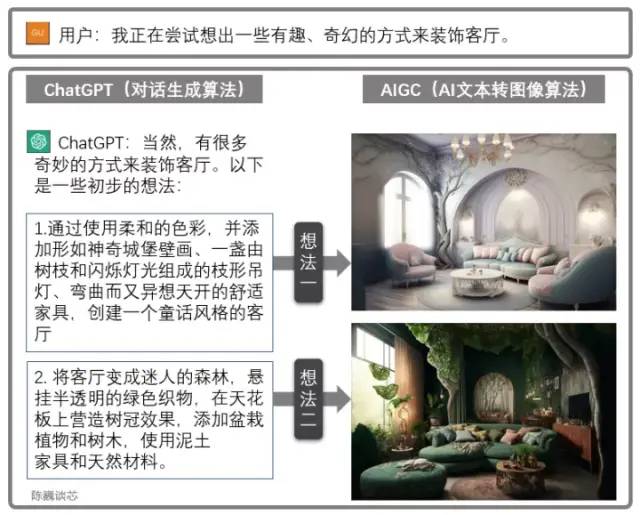
Совместное использование ChatGPT и AIGC
ChatGPT также можно использовать в сочетании с другими моделями AIGC для получения более интересных и практичных функций.
Например, чертеж дизайна гостиной создается с помощью диалога выше. Это значительно расширяет возможности приложений ИИ взаимодействовать с клиентами, позволяя нам увидеть начало широкомасштабного внедрения ИИ.
1. Наследование и характеристики ChatGPT

▌1.1 Семейство OpenAI
Давайте сначала разберемся, кто такой OpenAI.
OpenAI со штаб-квартирой в Сан-Франциско была основана в 2015 году Маском из Tesla, Сэмом Альтманом и другими инвесторами с целью разработки технологии искусственного интеллекта, приносящей пользу всему человечеству. Маск ушел в 2018 году из-за разногласий в направлении развития компании.
Ранее OpenAI прославилась запуском серии моделей обработки естественного языка GPT. С 2018 года OpenAI начала выпускать генеративную предварительно обученную языковую модель GPT (Generative Pre-trained Transformer), которую можно использовать для генерации различного контента, такого как статьи, коды, машинный перевод и вопросы и ответы.
Количество параметров каждого поколения моделей GPT резко возросло, и можно сказать, что «чем больше, тем лучше». GPT-2, выпущенный в феврале 2019 года, имел 1,5 миллиарда параметров, а GPT-3 в мае 2020 года — 175 миллиардов параметров.
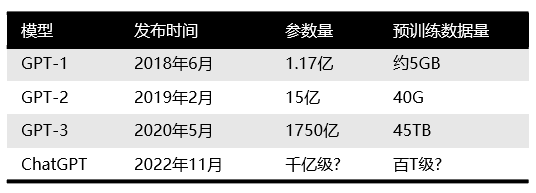
Сравнение основных моделей семейства GPT
▌1.2 Основные возможности ChatGPT
ChatGPT — это диалоговая модель искусственного интеллекта, разработанная на основе архитектуры GPT-3.5 (генеративный предварительно обученный трансформатор 3.5) и являющаяся братской моделью InstructGPT.
ChatGPT, скорее всего, будет разработкой OpenAI перед официальным запуском GPT-4 или для сбора больших объемов данных разговоров.
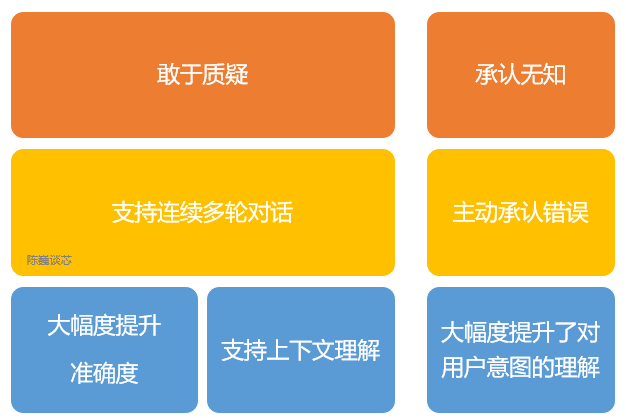
Основные возможности ChatGPT
OpenAI использовала технологию RLHF (Reinforcement Learning from Human Feedbac, обучение с подкреплением обратной связи от человека) для обучения ChatGPT и добавила дополнительный ручной контроль для тонкой настройки.
Кроме того, ChatGPT имеет следующие возможности:
1) Вы можете активно признавать свои ошибки. Если пользователь указывает на свою ошибку, модель слушает и уточняет ответ.
2)ChatGPT Можно усомниться в неправотеизвопрос. Например, когда его спрашивают «Колумб 2015 Каково это — приехать в США в 2017 году» По запросу бот объяснит, что Колумб не принадлежит этой эпохе, и скорректирует вывод.
3) ChatGPT может признаться в собственном невежестве и непонимании профессиональных технологий.
4) Поддерживает несколько раундов непрерывного диалога.
Со всевозможными умными колонками и «искусственным интеллектом», которыми каждый пользуется в жизни,умственно отсталый“другой,ChatGPT запомнит предыдущие сообщения пользователя и разговора во время разговора.,понимание контекста,ответить на некоторые гипотетические вопросы.
ChatGPT может осуществлять непрерывный диалог, значительно улучшая взаимодействие с пользователем в режиме диалогового взаимодействия.
Для точного перевода (особенно китайского языка и транслитерации имен) ChatGPT все еще далек от совершенства, но он похож на другие инструменты онлайн-перевода с точки зрения беглости текста и идентификации конкретных имен.
Поскольку ChatGPT представляет собой большую языковую модель и еще не имеет возможностей веб-поиска, он может отвечать только на основе набора данных, который у него есть в 2021 году.
Например, он не знает о чемпионате мира по футболу 2022 года, не ответит, какая сегодня погода, и не поможет вам найти информацию, как Siri от Apple. Если ChatGPT сможет самостоятельно находить учебные материалы и знания в Интернете, ожидается, что произойдет еще больший прорыв.
Даже если полученные знания ограничены, ChatGPT все равно может непредвзято ответить на многие странные вопросы людей. Чтобы предотвратить появление у ChatGPT вредных привычек, ChatGPT защищен алгоритмами, позволяющими уменьшить вредные и вводящие в заблуждение входные данные обучения.
Запросы фильтруются через API модерации, и потенциально расистские или сексистские советы отклоняются.
2. Принцип ChatGPT/GPT
▌2.1 NLP
Известные ограничения в области НЛП/НЛУ включают неправильное понимание повторяющегося текста, узкоспециализированных тем и неправильное понимание контекстных фраз.
Людям или ИИ обычно требуются годы обучения, чтобы вести нормальный разговор.
Модели типа НЛП должны не только понимать значение слов, но и понимать, как формировать предложения и давать контекстуально значимые ответы, и даже использовать соответствующий сленг и профессиональную лексику.
Области применения технологии НЛП
По сути, GPT-3 или GPT-3.5, лежащий в основе ChatGPT, представляет собой очень большую статистическую языковую модель или модель последовательного прогнозирования текста.
▌2.2 GPT v.s. BERT
Подобно модели BERT, ChatGPT или GPT-3.5 автоматически генерирует каждое слово (слово) ответа на основе входного предложения и вероятности языка/корпуса.
С точки зрения математики или машинного обучения, языковая модель представляет собой моделирование вероятностного корреляционного распределения последовательностей слов, то есть использование уже произнесенных утверждений (в математике утверждения можно рассматривать как векторы) в качестве входных условий для прогнозирования следующего. Распределение вероятностей появления разных предложений или даже языковых наборов одновременно.
Благодаря более высокой производительности и огромным параметрам ChatGPT,Он содержит больше данных по большему количеству тем и может обрабатывать больше нишевых тем.
ChatGPT теперь может выполнять такие задачи, как ответы на вопросы, написание статей, обобщение текста, языковой перевод и генерация компьютерного кода.
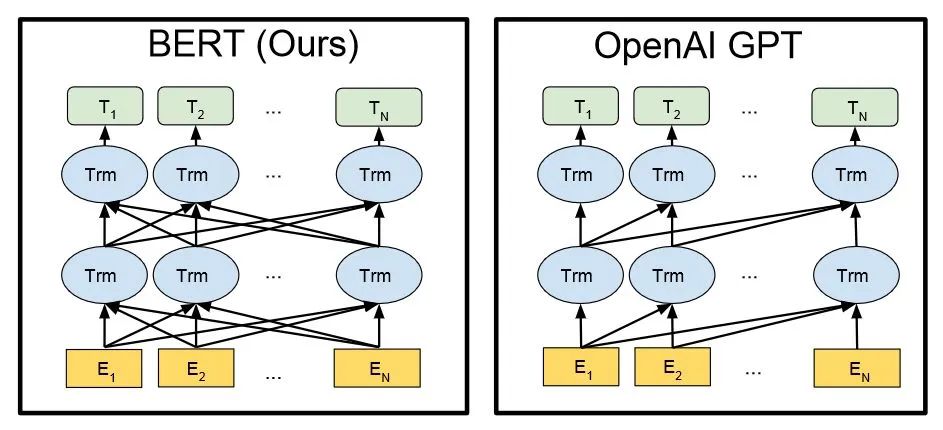
Техническая архитектура BERT и GPT (En на рисунке — каждое слово входного ответа, а Tn — каждое слово выходного ответа)
Независимо от отрасли, вы можете следить за этим старшим архитектором на JD.com, чтобы узнать о рабочих идеях на основе искусственного интеллекта. Отсканируйте QR-код ниже, чтобы получить прямой доступ к курсу 👇.
3. Техническая архитектура ChatGPT
▌3.1 Эволюция семейства GPT
Говоря о ChatGPT, нельзя не упомянуть семейство GPT.
До ChatGPT было несколько известных собратьев, включая GPT-1, GPT-2 и GPT-3. Каждый из этих братьев больше другого, а ChatGPT больше похож на GPT-3.
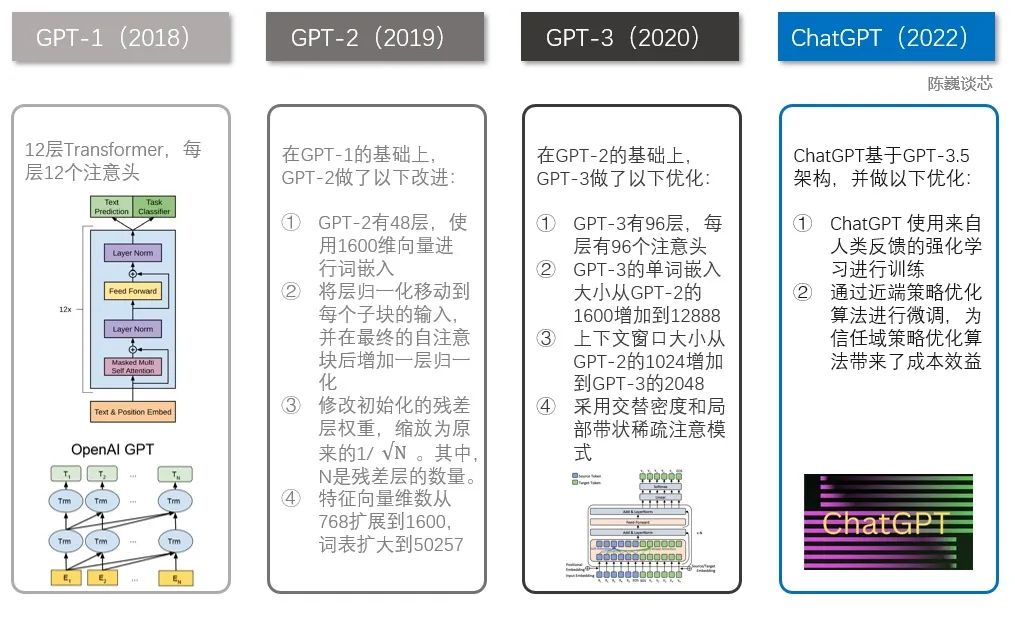
Техническое сравнение ChatGPT и GPT 1–3
Семейство GPT и модель BERT являются хорошо известными моделями НЛП, обе основаны на технологии Transformer. GPT-1 имеет только 12 слоев преобразователя, но в GPT-3 их число увеличилось до 96 слоев.
▌3.2 Обучение с подкреплением обратной связи от человека
Основное различие между InstructGPT/GPT3.5 (предшественником ChatGPT) и GPT-3 заключается в добавлении так называемого RLHF (Reinforcement Learning from Human Feedback, обучение с подкреплением обратной связи от человека).
Эта парадигма обучения улучшает настройку результатов модели человеком и приводит к более понятному ранжированию.
В InstructGPT ниже приведены критерии оценки «качественности предложений».
- Подлинность: это ложь или заблуждение?
- Безвредность: наносит ли он физический или психический вред людям или окружающей среде?
- Полезность: Решает ли задачу пользователя?
▌3.3 Структура ТАМЕР
Я должен упомянуть здесь систему TAMER (обучение агента вручную посредством оценочного подкрепления).
Эта структура вводит человеческие маркеры в цикл обучения агентов и может обеспечивать обратную связь с агентами через людей (то есть направлять агентов к обучению), тем самым быстро достигая целей задач обучения.
Основная цель внедрения человеческих маркеров – ускорить обучение. Хотя обучение с подкреплением Технология демонстрирует выдающиеся результаты во многих областях.,Но есть еще много недостатков,Например, обучениеОн имеет характеристики медленной скорости сходимости и высокой стоимости обучения.
TAMER может использовать знания людей-теггеров для вознаграждения за информацию.обратная связьизобучение формеAgent,Ускорить его быстрое сближение.
TAMER не требует от тагера профессиональных знаний или навыков программирования, а стоимость корпуса ниже. С помощью TAMER+RL (обучение с подкреплением) процесс обучения с подкреплением (RL) на основе вознаграждений марковского процесса принятия решений (MDP) можно улучшить с помощью обратной связи от человеческих маркеров.
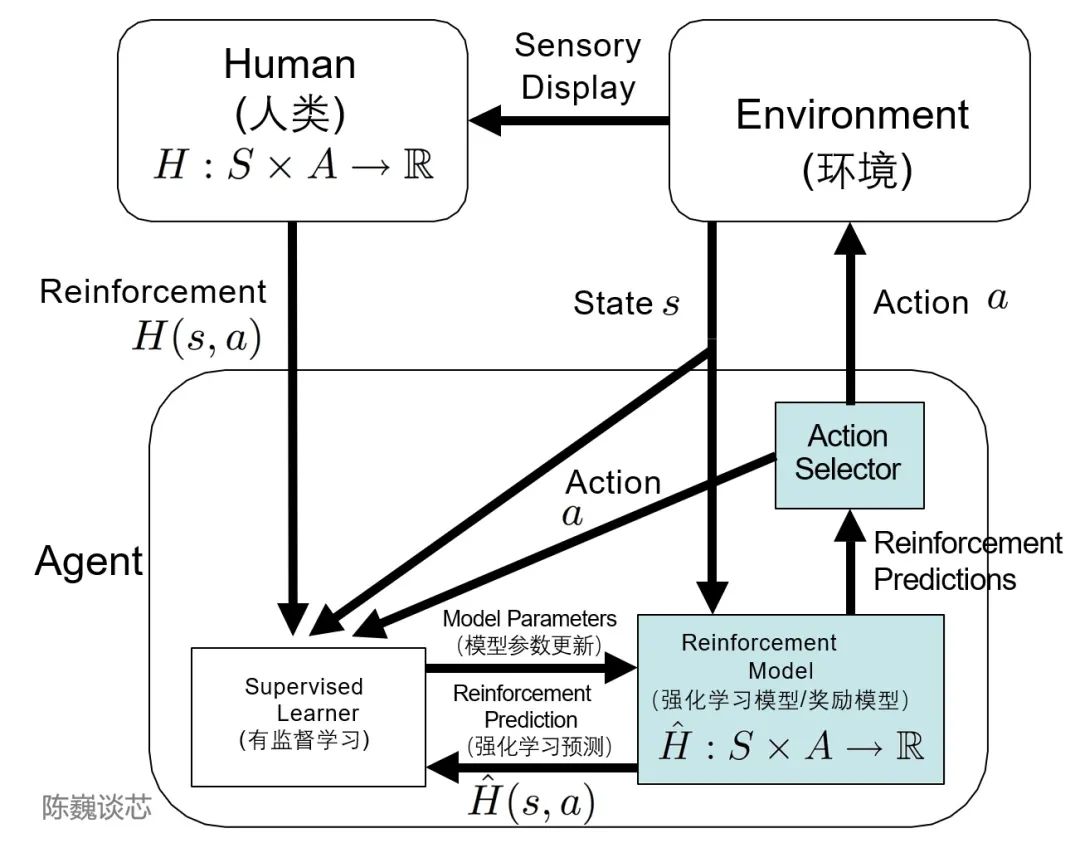
Применение архитектуры TAMER в обучении с подкреплением
С точки зрения конкретной реализации, тегеры-люди действуют как диалоговые пользователи и помощники с искусственным интеллектом, предоставляя образцы разговоров и позволяя модели генерировать некоторые ответы. Затем тегеры оценивают и ранжируют варианты ответа и возвращают модели лучшие результаты.
Агенты учатся одновременно в двух режимах обратной связи — человеческом подкреплении и вознаграждении процесса принятия Марковских решений как интегрированной системы, тонкой настройке модели и непрерывной итерации стратегий вознаграждения.
Благодаря этому ChatGPT может понимать и выполнять человеческий язык или инструкции лучше, чем GPT-3, имитировать людей и предоставлять связную и логичную текстовую информацию.
▌3.4 Обучение ChatGPT
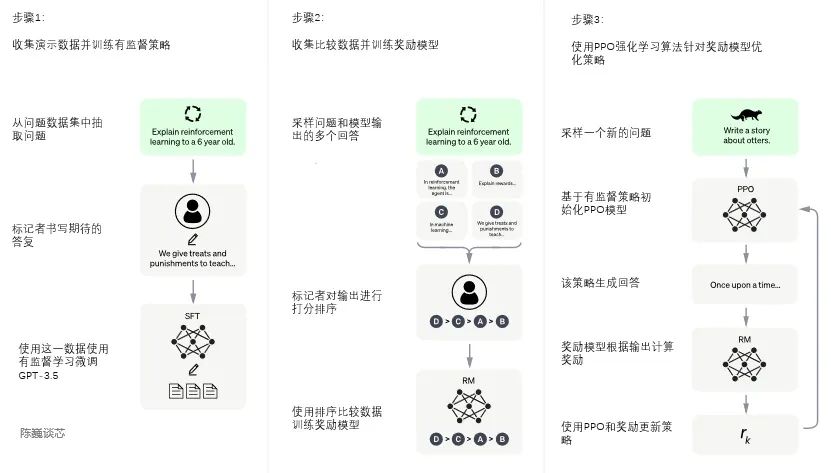
Процесс обучения ChatGPT разделен на следующие три этапа:
Первый этап: обучение модели контролируемой политики
GPT 3.5 сам по себе сложен для понимания различных намерений, содержащихся в разных типах человеческих инструкций, а также сложно судить, является ли сгенерированный контент высококачественным результатом.
Чтобы GPT 3.5 изначально намеревался понять инструкции, вопросы сначала будут выбраны случайным образом из набора данных, а аннотаторы-люди будут давать высококачественные ответы. Затем эти аннотированные вручную данные будут использоваться для точной настройки GPT-. Модель 3.5 (для получения модели SFT, контролируемая точная настройка).
Модель SFT на данный момент уже лучше, чем GPT-3, в следовании инструкциям/диалогам, но она не обязательно соответствует человеческим предпочтениям.
Процесс обучения модели ChatGPT
Второй этап: модель вознаграждения за обучение (Reward Mode, RM)
На этом этапе в основном обучается модель вознаграждения посредством ручного аннотирования обучающих данных (около 33 КБ данных).
Случайным образом отберите вопросы из набора данных и используйте модель, созданную на первом этапе, для создания нескольких разных ответов на каждый вопрос. Аннотаторы-люди принимают эти результаты во внимание и определяют порядок ранжирования. Этот процесс похож на коучинг или наставничество.
Затем используйте эти данные результатов ранжирования для обучения модели вознаграждения. Множественные результаты сортировки объединяются в пары для формирования нескольких пар обучающих данных.
Модель RM принимает входные данные и выдает оценку, которая оценивает качество ответа. Таким образом, для пары обучающих данных параметры корректируются таким образом, чтобы ответы высокого качества оценивались выше, чем ответы низкого качества.
Третий этап: используйте обучение с подкреплением PPO (оптимизация проксимальной политики, оптимизация проксимальной политики) для оптимизации стратегии.
Основная идея PPO — преобразовать процесс обучения On-policy в Policy Gradient в Off-policy, то есть преобразовать онлайн-обучение в офлайн-обучение. Этот процесс преобразования называется выборкой по важности.
На этом этапе используется модель вознаграждения, обученная на втором этапе, и на основе оценок вознаграждения обновляются параметры предварительно обученной модели. Случайным образом выберите вопросы из набора данных, используйте модель PPO для генерации ответов и используйте модель RM, обученную на предыдущем этапе, для получения оценок качества.
Оценки вознаграждения передаются последовательно, что приводит к градиенту политики, а параметры модели PPO обновляются посредством обучения с подкреплением.
Если мы продолжим повторять второй и третий этапы посредством итерации, будет обучена модель ChatGPT более высокого качества.
4. Ограничения ChatGPT
Пока пользователь вводит вопрос, ChatGPT может на него ответить. Означает ли это, что нам больше не нужно передавать ключевые слова в Google или Baidu и мы можем немедленно получить нужный ответ?
Хотя ChatGPT показывает отличные возможности контекстного диалога и даже возможности программирования.,Завершено изменение впечатления общественности о человеко-машинном переговорном роботе (Чат Бот) с «искусственно отсталого» на «интересного».,Нам также нужно увидеть,Технология ChatGPT все еще имеет некоторые ограничения.,Все еще продолжаетсяиз Входитьшаг.
1) ChatGPT не хватает «человеческого здравого смысла» и возможностей расширения в областях, где он не был обучен на большом объеме корпуса, и может даже говорить серьезную «ерунду». ChatGPT может «создавать ответы» во многих областях, но когда пользователи ищут правильные ответы, ChatGPT также может давать вводящие в заблуждение ответы. Например, пусть ChatGPT задаст вопрос о поступлении в начальную школу. Хотя он может написать длинную серию вычислительных процессов, окончательный ответ будет таким.это ошибкаиз。 Так стоит ли нам верить результатам ChatGPT или нет?

ChatGPT дает неправильные ответы на математические вопросы
2) ChatGPT не может обрабатывать сложные, длинные или особо профессиональные языковые конструкции. На вопросы из очень специализированных областей, таких как финансы, естественные науки или медицина, ChatGPT может не дать соответствующих ответов, если недостаточно «питания» корпуса.
3) ChatGPT требует очень большого количества вычислительной мощности (чипов) для поддержки его обучения и развертывания. Несмотря на необходимость большого объема корпусных данных для обучения модели, в настоящее время применение ChatGPT по-прежнему требует поддержки серверов с большой вычислительной мощностью, а стоимость этих серверов недоступна даже обычным пользователям. Модель с миллиардами параметров требует ошеломляющего количества вычислительных ресурсов для запуска и обучения. , если столкнуться с сотнями миллионов пользовательских запросов от реальных поисковых систем, если будет принята популярная в настоящее время бесплатная стратегия, любому предприятию будет трудно нести эти расходы. Поэтому широкой публике все равно придется ждать более легких моделей или более экономичных вычислительных платформ.
4) ChatGPT пока не умеет внедрять новые знания онлайн, а переобучить модель GPT при появлении новых знаний нереально. Будь то время обучения или стоимость обучения, рядовым тренерам это сложно принять. Если мы примем модель онлайн-обучения новым знаниям, это кажется осуществимым, а стоимость корпуса относительно низкой, но это может легко привести к проблеме катастрофического забывания исходных знаний из-за введения новых данных.
5) ChatGPT по-прежнему является моделью черного ящика. В настоящее время логика внутреннего алгоритма ChatGPT не может быть разложена, поэтому нет никакой гарантии, что ChatGPT не будет генерировать утверждения, которые атакуют пользователей или даже причиняют им вред.
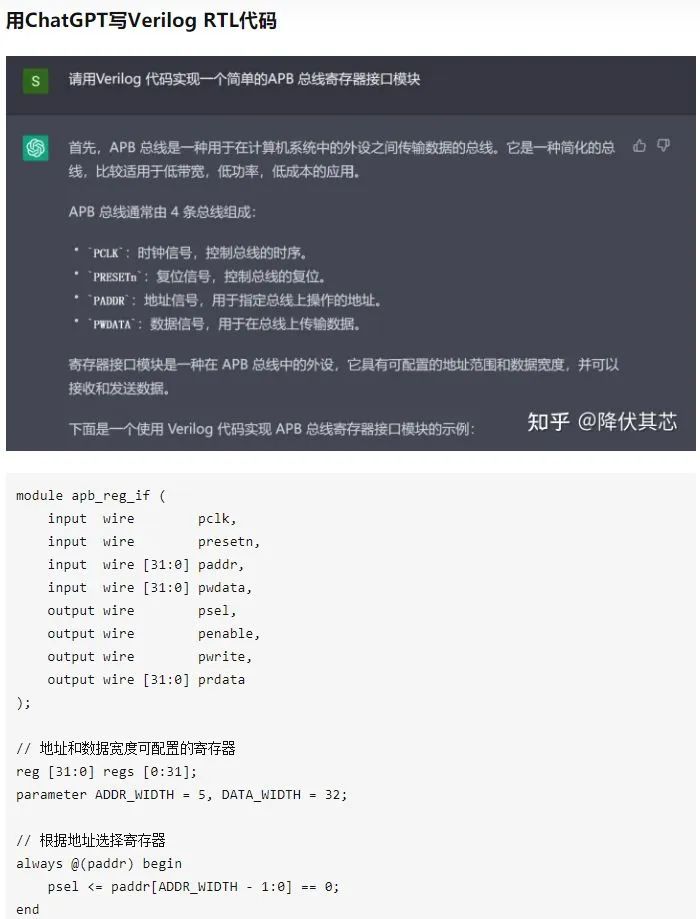
Конечно, недостатки не скрываются. Некоторые инженеры опубликовали беседу с просьбой к ChatGPT написать код verilog (код проектирования чипов). Видно, что уровень ChatGPT превысил уровень некоторых новичков Verilog.
5. Будущие направления улучшения ChatGPT
▌5.1 RLAIF сократит количество обратной связи между людьми
В конце 2020 года Дарио Амодей, бывший вице-президент по исследованиям OpenAI, основал компанию по искусственному интеллекту Anthropic со штатом 10 сотрудников.
Члены команды основателей Anthropic в основном являются ранними и основными сотрудниками OpenAI и участвовали в OpenAI GPT-3, мультимодальных нейронах, обучении с подкреплением человеческих предпочтений и т. д.
В декабре 2022 года Anthropic снова опубликовала статью «Конституционный ИИ: безвредность от обратной связи ИИ», в которой представила модель искусственного интеллекта Клода. (arxiv.org/pdf/2212.0807)
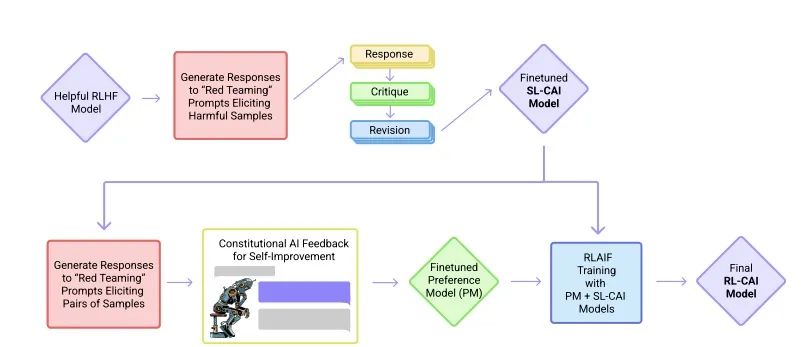
Процесс обучения модели CAI
И Claude, и ChatGPT используют обучение с подкреплением (RL) для обучения моделей предпочтений. CAI (Конституциональный ИИ) также построен на основе RLHF. Разница в том, что процесс ранжирования CAI использует модели (а не людей) для предоставления первоначального результата ранжирования для всех сгенерированных выходных результатов.
CAI заменяет человеческие предпочтения безобидных выражений обратной связью искусственного интеллекта, известной как RLAIF, где искусственный интеллект оценивает содержание ответа на основе набора конституционных принципов.
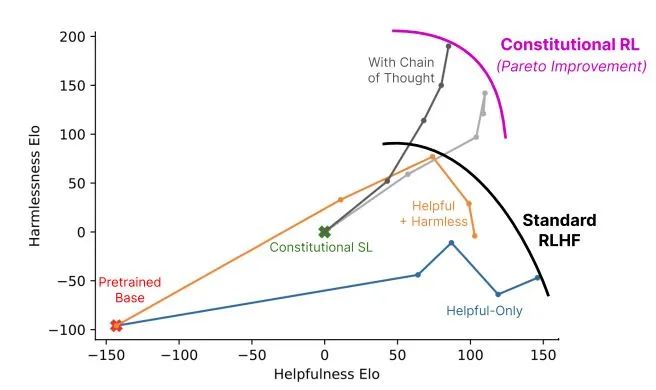
▌5.2 Восполнить недостатки по математике и физике
Хотя ChatGPT обладает мощными диалоговыми возможностями, он склонен к серьезной ерунде в разговорах о математических расчетах.
Ученый-компьютерщик Стивен Вольфрам предложил решение этой проблемы. Стивен Вольфрам создал поисковую систему языка Wolfram и компьютерных знаний Wolfram|Alpha, серверная часть которой реализована через Mathematica.
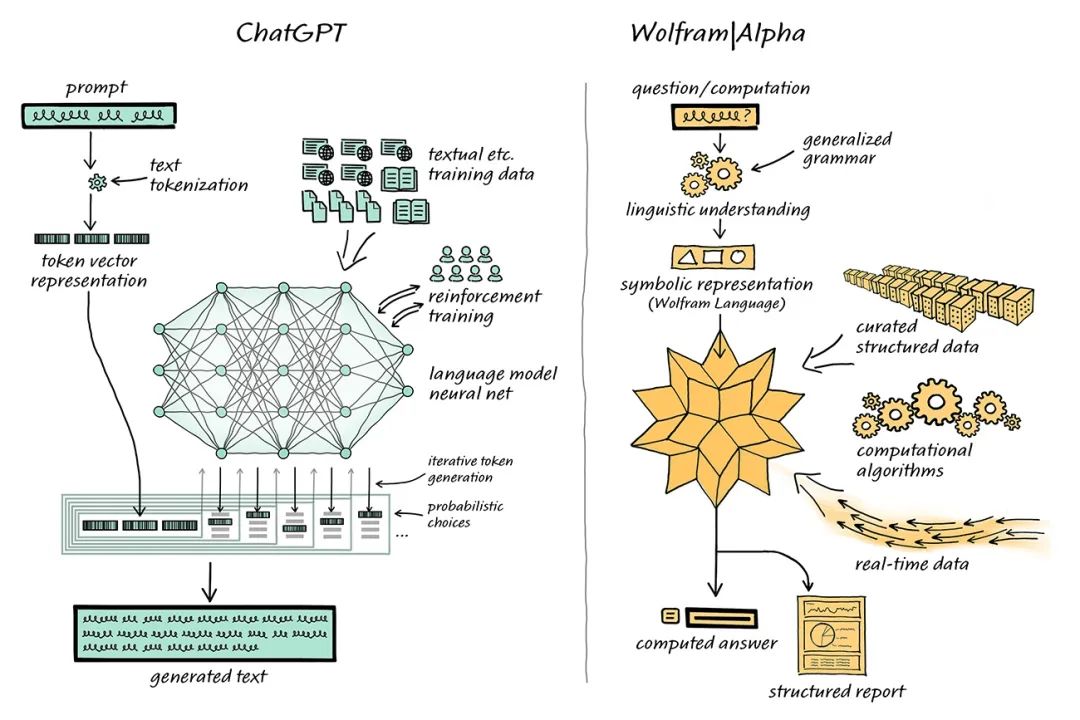
ChatGPT объединяется с Wolfram|Alpha для решения проблем с кардингом
В этой объединенной системе ChatGPT может «общаться» с Wolfram|Alpha точно так же, как люди используют Wolfram|Alpha, а Wolfram|Alpha будет использовать свои возможности перевода символов для «перевода» выражений естественного языка, полученных от ChatGPT, в соответствующие символы компьютерного языка. .
В прошлом академические круги разделились по поводу «статистических методов», используемых ChatGPT, и «символических методов» Wolfram|Alpha.
Но теперь взаимодополняемость ChatGPT и Wolfram|Alpha дала области НЛП возможность вывести ее на новый уровень.
ChatGPT не нужно генерировать такой код, ему нужно только сгенерировать обычный естественный язык, а затем использовать Wolfram|Alpha для перевода его в точный язык Wolfram Language, а затем базовая система Mathematica выполнит вычисления.
▌5.3 Миниатюризация ChatGPT
Хотя ChatGPT является мощным инструментом, размер его модели и стоимость использования также не позволяют многим людям.
Существует три типа сжатия модели, которые могут уменьшить размер и стоимость модели.
Первый метод — квантование, которое снижает точность числового представления отдельных весов. Например, понижение версии Tansformer с FP32 до INT8 мало повлияет на его точность.
Второй метод сжатия модели — это сокращение, которое представляет собой удаление сетевых элементов, включая каналы, из отдельных весов (неструктурированное сокращение) в компоненты с более высокой степенью детализации, такие как весовые матрицы. Этот подход эффективен для видения и языковых моделей меньшего масштаба.
Третий метод сжатия модели — разрежение. Например, SparseGPT (arxiv.org/pdf/2301.0077), предложенный Австрийским институтом науки и технологий (ISTA), может сократить разреженность серии GPT до 50% за один шаг без какого-либо повторного обучения. Для модели GPT-175B такого сокращения можно добиться за несколько часов, используя только один графический процессор.
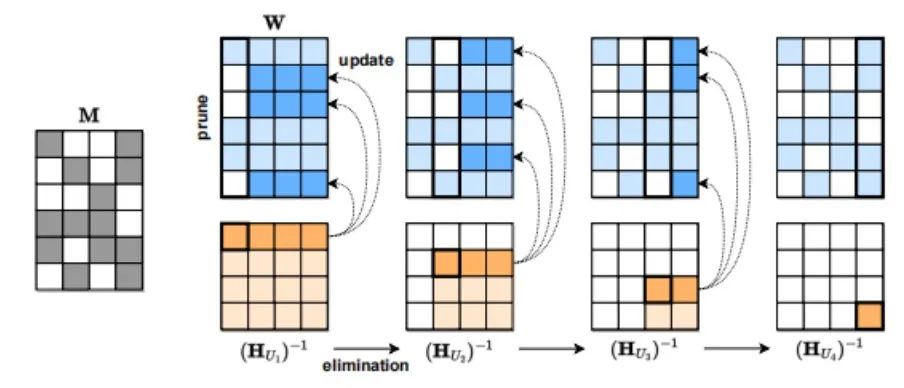
Процесс сжатия SparseGPT
6. Промышленное будущее и инвестиционные возможности ChatGPT
▌6.1 AIGC
Говоря о ChaGPT, нельзя не упомянуть AIGC.
AIGC использует технологию искусственного интеллекта для создания контента. По сравнению с UGC (контентом, созданным пользователями) и PGC (контентом, созданным профессионалами) в предыдущие эпохи Web1.0 и Web2.0, AIGC, который представляет контент, созданный искусственным интеллектом, представляет собой новый раунд изменений в методах производства контента, и AIGC контент находится в Web3. В эпоху 0 также будет экспоненциальный рост.
Появление модели ChatGPT имеет большое значение для применения AIGC в текстовом/голосовом режиме и окажет существенное влияние на восходящие и нисходящие сегменты индустрии искусственного интеллекта.
▌6.2 Сценарии получения выгод
С точки зрения последующих полезных приложений они включают, помимо прочего, программирование без кода, новое поколение, диалоговые поисковые системы, голосовых компаньонов, голосовых помощников по работе, разговорных виртуальных людей, обслуживание клиентов с искусственным интеллектом, машинный перевод, проектирование чипов, и т. д.
С точки зрения возросшего спроса со стороны восходящего потока, включая чипы вычислительной мощности, аннотацию данных, обработку естественного языка (NLP) и т. д.
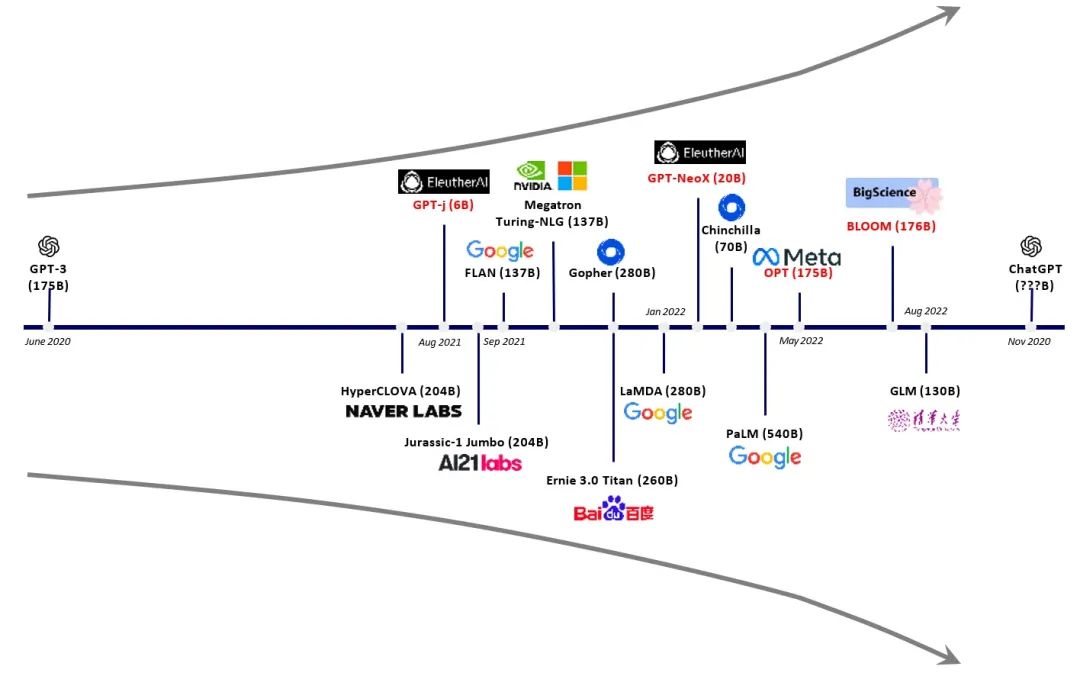
Большие модели стремительно растут (больше параметров/большие требования к вычислительной мощности чипов)
Благодаря постоянному совершенствованию алгоритмических технологий и технологий вычислительной мощности ChatGPT будет и дальше двигаться к более совершенной версии с более сильными функциями, применяться во все большем количестве областей и генерировать все больше и больше качественных разговоров и контента для людей.
Наконец, автор спросил о состоянии интегрированных технологий хранения и вычислений в области ChatGPT (в настоящее время автор занимается продвижением внедрения интегрированных чипов хранения и вычислений). ChatGPT задумался об этом и смело предсказал, что будут интегрированы технологии хранения и вычислений. будет занимать доминирующее положение в чипах ChatGPT. (Покорил мое сердце
)


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
