6 технических моментов, которые помогут вам понять принципы высокой производительности Kafka
Привет всем, я брат Джун.
Kafka — очередь сообщений с отличной производительностью, а объем обрабатываемых сообщений в секунду может достигать десятков миллионов. Сегодня давайте поговорим о технических принципах, лежащих в основе высокой производительности Kafka.
1 Отправка оптом
Kafka отправляет и получает сообщения пакетами. Давайте посмотрим на код производителя Kafka для отправки сообщений:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// Опускаем предыдущий код
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
//Добавляем сообщение к предыдущему пакету сообщений кэшиз
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
//Накапливаем до установленного размера изкэша и отправляем его
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch /**пропуск catch код*/
}
Как видно из кода, после того, как производитель вызывает метод doSend, он не отправляет сообщение напрямую, а кэширует сообщение. Оно не будет отправлено до тех пор, пока объем кэшированного сообщения не достигнет настроенного размера пакета.
Примечание. Как видно из приведенного выше кода accumulator.append, пакет сообщений принадлежит одному и тому же разделу одной и той же темы.
После того, как Брокер получит сообщение, он не будет анализировать пакетное сообщение в одно сообщение и затем размещать его на рынке. Вместо этого он разместит его как пакетное сообщение. В то же время он также напрямую синхронизирует пакетное сообщение. на другие реплики.
Когда потребители извлекают сообщения, они извлекают их не по отдельности, а группами. После получения пакета сообщений они анализируют их на отдельные сообщения для использования.
Использование пакетов для отправки и получения сообщений сокращает количество взаимодействий между клиентом и Брокером и улучшает возможности обработки Брокера.
2 Сжатие сообщений
Если тело сообщения относительно велико, а пропускная способность Kafka достигает десятков миллионов, пропускная способность сети, поддерживаемая сетевой картой, будет узким местом. Решение Kafka — сжатие сообщений. При отправке сообщения, если вы добавите параметр compress.type, вы сможете включить сжатие сообщения:
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//Открытое сжатие сообщений
props.put("compression.type", "gzip");
Producer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("my_topic", "key1", "value1");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
logger.error("sending message error: ", e);
} else {
logger.info("sending message successful, Offset: ", metadata.offset());
}
}
});
producer.close();
}
Если для параметра compress.type установлено значение none, сжатие не включено. Когда сообщение сжимается? Как упоминалось ранее, производитель кэширует пакет сообщений перед их отправкой и сжимает их перед отправкой. Код выглядит следующим образом:
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// ...
try {
// ...
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
//...
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
return appendResult;
}
//Этот пакет сообщений кэша заполнен, сжимаем его здесь
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}
Приведенный выше метод RecordsBuilder наконец вызывает конструктор MemoryRecordsBuilder, представленный ниже.
public MemoryRecordsBuilder(ByteBufferOutputStream bufferStream,
byte magic,
CompressionType compressionType,
TimestampType timestampType,
long baseOffset,
long logAppendTime,
long producerId,
short producerEpoch,
int baseSequence,
boolean isTransactional,
boolean isControlBatch,
int partitionLeaderEpoch,
int writeLimit) {
//Пропускаем другой код
this.appendStream = new DataOutputStream(compressionType.wrapForOutput(this.bufferStream, magic));
}
Вышеупомянутый метод WrapForOutput сжимает или не сжимает в соответствии с настроенным алгоритмом сжатия. В настоящее время Kafka поддерживает следующие алгоритмы сжатия: gzip, snappy и lz4. Начиная с версии 2.1.0, Kafka поддерживает алгоритм Zstandard.
На стороне брокера заголовок будет распакован и будет выполнена некоторая проверка, но тело сообщения распаковываться не будет. Тело сообщения распаковывается на стороне потребителя. После того как потребитель извлекает пакет сообщений, он сначала распаковывает его, а затем обрабатывает сообщение.
Поскольку сжатие и распаковка требуют большого количества ресурсов ЦП, при включении сжатия сообщений также необходимо учитывать ресурсы ЦП производителя и потребителя.
При пакетном сборе и сжатии сообщений процесс отправки сообщений производителем Kafka выглядит следующим образом:
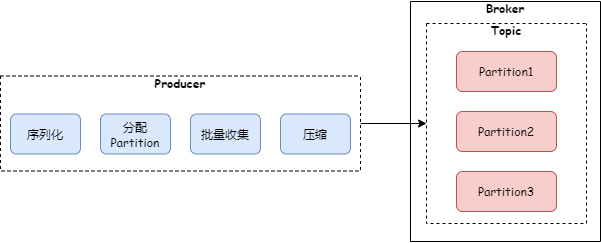
3 Диска последовательное чтение и запись
Последовательное чтение и запись экономит время адресации. Пока требуется одна адресация, можно выполнять непрерывное чтение и запись.
На твердотельных накопителях производительность последовательного чтения и записи в несколько раз превышает производительность произвольного чтения и записи. На механическом жестком диске магнитную головку необходимо перемещать во время адресации, и это механическое перемещение занимает много времени. Поэтому производительность последовательного чтения и записи механического жесткого диска в десятки раз превышает скорость случайного чтения и записи.
Когда Kafka's Broker записывает данные сообщения, он сначала создает файл для каждого раздела, а затем последовательно добавляет данные в дисковое пространство, соответствующее файлу. Если файл заполнен, для продолжения добавления создается новый файл. Это значительно сокращает время адресации и повышает производительность чтения и записи.
4 PageCache
В системе Linux все операции ввода-вывода с файлами должны проходить через PageCache. PageCache — это кэш дисковых файлов, установленный в памяти. Когда приложение читает или записывает файл, оно не читает и не записывает файл непосредственно на диск, а управляет PageCache.
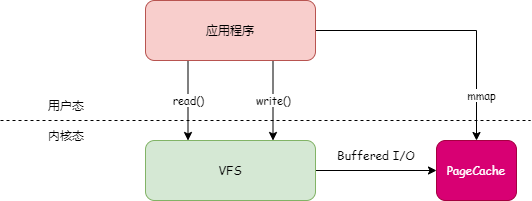
Когда приложение записывает файл, оно сначала записывает данные в PageCache, а затем операционная система регулярно записывает данные PageCache на диск. Как показано ниже:

Когда приложение считывает данные файла, оно сначала определяет, находятся ли данные в PageCache. Если это так, оно читает их напрямую. Если нет, оно читает диск и кэширует данные в PageCache.
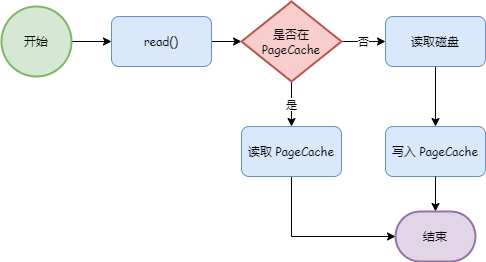
Kafka в полной мере использует преимущества PageCache. Когда скорость, с которой производители создают сообщения, аналогична скорости, с которой потребители потребляют сообщения, Kafka может практически завершить передачу сообщений, не помещая их на диск.
5 нулевых копий
Когда Kafka Broker отправляет сообщение потребителю, даже если PageCache задействован, данные в PageCache необходимо сначала скопировать в пространство памяти приложения, а затем скопировать из пространства памяти приложения в кэш Socket перед отправкой данных. Как показано ниже:
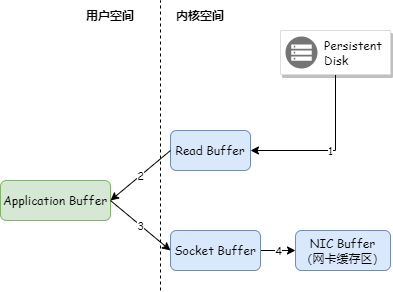
Kafka использует технологию нулевого копирования для копирования данных непосредственно из PageCache в буфер Socket, поэтому данные не нужно копировать в пространство памяти пользовательского режима. В то же время контроллер DMA напрямую завершает копирование данных без использования ЦП. участие. Как показано ниже:
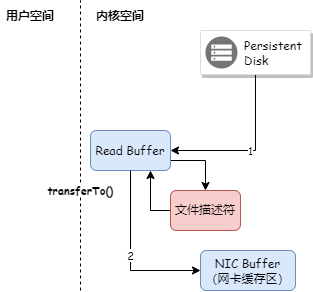
Технология нулевого копирования Java использует метод FileChannel.transferTo(), а базовый метод вызывает sendfile.
6 mmap
Файлы журналов Kafka разделены на файлы данных (.log) и индексные файлы (.index). Чтобы повысить производительность чтения индексного файла, Kafka использует сопоставление памяти mmap для индексного файла для сопоставления индексного файла с пространством памяти. процесса, так что чтение индексного файла устраняет необходимость чтения с диска. Как показано ниже:
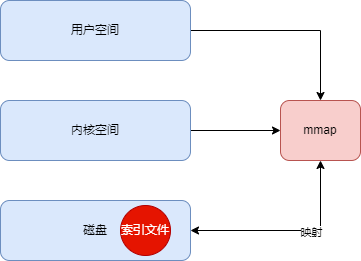
7 Резюме
В этой статье представлены ключевые технологии, используемые Kafka для достижения высокой производительности. Эти технологии могут послужить основой для нашего исследования и работы.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
