4 наиболее рекомендуемых бесплатных инструмента ETL в 2023 году
1. Введение в ETL
Процесс ETL является основной частью построения хранилища данных. Он включает в себя извлечение данных из различных источников данных, их очистку, преобразование и интеграцию и, наконец, загрузку в хранилище данных для анализа и принятия решений. В контексте локализации хранилища данных процесс ETL играет важную роль. Сегодня мы поговорим о концепции и методе проектирования процесса ETL.
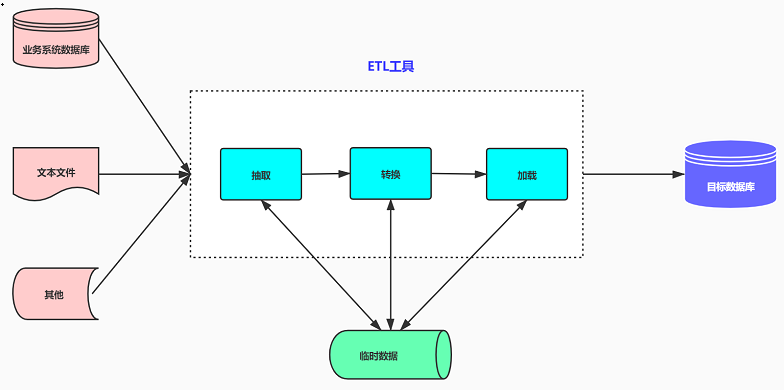
1. Извлечение данных (Извлечение)
Извлечение данных — это первый шаг процесса ETL, который включает извлечение данных из различных источников данных и извлечение данных из исходной системы для подготовки к последующей обработке. Источники данных могут быть различных типов, которые делятся на структурированные данные, полуструктурированные данные и неструктурированные данные, включая реляционные базы данных, файлы (например, CSV, Excel, JSON и т. д.), API, файлы журналов и т. д. Извлечение данных можно разделить на следующие методы в зависимости от структуры источника данных:
- Структурированные данные:из реляционной базы данных、лист、CSVВ структурированных источниках данных, таких как файлы,В виде SQL-запросов или вызовов API,Извлекайте записи данных, используя методы постепенного извлечения или CDC;,Извлекать только измененные или новые данные,для повышения эффективности и производительности в реальном времени.
(2) Неструктурированные или полуструктурированные. данные:из текстового файла、бревно、изображение、Аудио、В неструктурированных источниках данных, таких как видео,с соответствующими методами анализа,Извлекайте ценную информацию, используйте интеллектуальный анализ текста, обработку изображений, распознавание речи и другие технологии;,Преобразуйте неструктурированные данные в структурированную или полуструктурированную форму.
Что касается методов извлечения данных, обычно можно использовать следующие методы:
(1) Извлеките всю сумму (Full Extraction): Извлеките все данные из исходной системы одновременно, что подходит для ситуаций, когда объем данных невелик и изменения невелики, например, при начальной загрузке данных.
(2) Поэтапное извлечение (Поэтапное Extraction): Извлекаются только те данные, которые были изменены в исходной системе. Метки времени или дельта-теги обычно используются для идентификации новых или измененных данных, которые обычно используются для обновления данных.
(3) Постепенное извлечение + отслеживание журналов (Изменить Data Capture,CDC): Используйте технологию отслеживания журналов в базе данных, чтобы отслеживать изменения в базе данных в режиме реального времени и извлекать измененные данные, чтобы обеспечить их актуальность в реальном времени.
2. Преобразование данных (Преобразование)
Преобразование данных — это основная часть процесса ETL, которая включает в себя очистку, интеграцию и преобразование извлеченных данных для их адаптации к потребностям целевого хранилища и анализа. Методы преобразования данных разных структур также различны:
(1)Структурированные данные:Метод преобразования в основном включает очистку данных.,Удалите повторяющиеся значения и обработайте недостающие данные,и обеспечить согласованность и точность данных,Выполнение таких операций, как объединение, слияние и фильтрация реляционных данных.,Интегрировать данные из разных источников и т.д.; (2)Нет Структурированные данные:Метод преобразования в основном включает обработку текстовых данных на естественном языке.,Например, сегментация слов, распознавание сущностей, анализ настроений и т. д.,извлекать ключевую информацию из текстового контента,Преобразование неструктурированных данных в структурированные форматы, удобные для хранения и анализа.,Например, преобразование текста влистформа и т. д.。
Преобразование данных включает в себя следующие основные этапы:
(1) Очистка данных: Очистка данных направлена на устранение аномалий, пропусков или ошибок в данных и обеспечение точности и последовательности данных. Это может включать удаление повторяющихся значений, заполнение пропущенных значений, исправление проблем с форматированием и т. д.
(2) Интеграция данных: Если данные поступают из нескольких исходных систем, может потребоваться консолидация данных для объединения данных из разных источников и устранения дубликатов для получения более полного представления.
(3) Преобразование данных и расчет: На этом этапе данные могут быть подвергнуты математическим расчетам, логическим операциям, обработке данных и другим операциям для создания новых производных данных или показателей. Например, рассчитать продажи, рассчитать темпы роста и т. д.
(4) Форматирование данных: Преобразование данных в формат целевого хранилища может включать реорганизацию структуры данных, настройку типов данных и т. д.
(5) Нормализация данных: Унифицируйте представление значений данных, чтобы обеспечить согласованность и сопоставимость данных. Например, преобразуйте названия регионов в стандартные коды регионов.
3. Загрузка данных (Load)
Загрузка данных — это последний этап процесса ETL, который загружает извлеченные и преобразованные данные в целевое хранилище, обычно в хранилище данных или озеро данных. Загрузку данных можно разделить на следующие методы:
(1) Полная нагрузка (Полная Load): Загрузите все обработанные данные в целевое хранилище одновременно, что подходит для первоначальной загрузки или небольшого объема данных.
(2) Инкрементальная загрузка (Инкрементальная Load): Загружаются только те данные, которые изменились после извлечения и преобразования, чтобы обеспечить передачу данных в режиме реального времени и эффективность.
(3) Транзакционная нагрузка: Используйте механизм транзакций базы данных, чтобы обеспечить целостность загрузки данных, то есть либо вся загрузка пройдет успешно, либо произойдет откат к состоянию перед загрузкой.
(4) Пакетная и потоковая загрузка: Пакетная загрузка подходит для крупномасштабной обработки данных, а потоковая загрузка подходит для сценариев, требующих анализа данных в реальном времени.
Независимо от того, обрабатываете ли вы структурированные или неструктурированные данные, основная цель процесса ETL — преобразовать необработанные данные в ценные данные, которые можно использовать для анализа, составления отчетов и принятия решений. Разные типы данных требуют разных операций извлечения, преобразования и загрузки в зависимости от их характеристик, чтобы обеспечить качество и доступность данных.
2. Рекомендация бесплатных инструментов ETL
В соответствии с различными источниками данных инструменты ETL хранилища данных можно разделить на инструменты ETL структурированных данных и инструменты ETL неструктурированных/полуструктурированных данных. Ниже приведены несколько бесплатных инструментов ETL, которые стоит рекомендовать после пробного использования.
1. Kettle
Kettle — это широко используемый зарубежный инструмент ETL с открытым исходным кодом. В настоящее время это самый мощный инструмент ETL с открытым исходным кодом на рынке. Kettle можно использовать для извлечения, преобразования и загрузки данных для быстрого хранения и анализа данных. Коротко поговорим о преимуществах и недостатках Чайника:
преимущество:
(1) Предоставляет интуитивно понятный графический интерфейс пользователя. Пользователи могут создавать процесс интеграции данных, перетаскивая и соединяя этапы преобразования. Этот метод визуальной разработки упрощает начало работы для нетехнического персонала и повышает эффективность разработки.
(2) Kettle предоставляет множество шагов и функций преобразования, позволяющих пользователям очищать, фильтровать, преобразовывать и объединять данные. Он поддерживает различные технологии обработки данных, включая операции со строками, обработку данных, агрегированные вычисления и условные оценки и т. д. для удовлетворения. сложные потребности в преобразовании данных.
недостаток:
- Новичкам Kettle может потребоваться некоторое время, чтобы понять его концепции и методы работы. Особенно при работе со сложной логикой преобразования данных требуются определенные знания в области обработки данных и программирования.
- Поддержка документации ограничена. По сравнению с некоторыми другими отечественными инструментами ETL, Kettle имеет большое количество отечественных пользователей, но его китайская документация и техническая поддержка относительно ограничены. Это может привести к большему самообучению и исследованиям при возникновении проблемы.
(3) Он не поддерживает функцию сбора данных CDC в реальном времени и может полагаться только на увеличение частоты планирования задач, например, на 1 минуту, для достижения передачи данных в реальном времени. Если объем данных относительно велик, это приведет к тому. большое давление на производственную систему.
Используйте схему интерфейса:
(Поскольку Kettle является программным обеспечением с открытым исходным кодом, его можно загрузить непосредственно с официального сайта)
2. AirByte:
airbyte — это новейшее программное обеспечение для интеграции данных с открытым исходным кодом, которое синхронизирует данные из приложений, API и баз данных с хранилищами данных, озерами данных и другими местами назначения. Оно поддерживает 200 соединителей типа источника и 100 соединителей типа назначения.
(Интерфейс компоновщика AirByte)
(Интерфейс мониторинга синхронизации данных)
- ETLCloud
Возможна синхронизация данных в реальном времени.、Оффлайн обработка данных、Платформа интеграции внутренних данных с комплексным мониторингом процессов,По сравнению с другими зарубежными ETL-инструментами его проще использовать.,ETLCloud разделен на версию сообщества и коммерческую платную версию.,Версия сообщества бесплатна для использования. Кратко поговорим о его преимуществах:
преимущество: (1) Мощная функция поддержки данных: она может подключаться к базам данных, общим протоколам верхнего уровня, очередям сообщений, файлам, платформенным системам, приложениям и другим типам источников данных, чтобы предоставить предприятиям полный набор решений для интеграции и анализа данных.
(2) Поддерживает возможности сбора данных CDC в реальном времени, высокую эффективность синхронизации и подробные отчеты о мониторинге во время процесса синхронизации данных.
(3) Он обеспечивает интуитивно понятный веб-интерфейс визуальной настройки и унифицированную платформу для эксплуатации и обслуживания. Это локализованный продукт для интеграции данных собственной разработки.
(4) Бесплатная версия от сообщества имеет большую группу пользователей, обширную техническую документацию и богатый рынок компонентов для быстрого подключения к приложениям SASS.
недостаток:
- Бесплатная версия сообщества не поддерживает некоторые функции и для их использования требуется корпоративная версия.
Используйте схему интерфейса:
Проектирование процесса:
(Интерфейс проектирования процесса)
(Интерфейс мониторинга задач)
4.DataX
DataX — это инструмент автономной синхронизации разнородных источников данных с открытым исходным кодом Alibaba. Как инструмент ETL, который обслуживает большие данные (на самом деле его можно рассматривать как инструмент ELT), помимо предоставления функций перемещения снимков данных, он также предоставляет богатые функции преобразования данных и может обеспечивать стабильные и эффективные функции синхронизации данных. Давайте кратко объясним Talk. о его преимуществах и недостатках.
преимущество:
(1) Поддерживает несколько источников данных и целевых объектов данных, к ним легко получить доступ.
(2) Поддерживает высокоскоростную передачу данных и подходит для крупномасштабных сценариев обработки данных.
(3) Высокая степень настройки, поддержка разработки, определяемой пользователем.
недостаток:
- DataX Но DataX выполняет задачи в виде сценария, прежде чем его можно будет вызвать, требуется полное понимание исходного кода, а стоимость обучения высока.
- Ему не хватает удобного интерфейса, требуется написание скриптов для настройки, недостаточно возможностей визуального мониторинга и отслеживания данных. Затраты на эксплуатацию и техническое обслуживание относительно высоки.
Используйте схему интерфейса:
3. Резюме
В этой статье рассказывается, что такое ETL, анализируется роль и важность ETL в обработке больших данных, а также рассказывается о сценариях применения и применимости ETL. Следует отметить, что преимущества и недостатки вышеупомянутых инструментов ETL предназначены только для справки, а конкретные оценки необходимо всесторонне рассматривать на основе реальных потребностей и использования. При выборе инструментов ETL рекомендуется провести всестороннюю оценку и сравнение с учетом потребностей вашего собственного бизнеса, чтобы выбрать наиболее подходящий инструмент.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
