3700 слов! Очистка данных сканера больше не важна. Архитектура сканера, подобная моей, ходит по тонкому льду.
Предисловие
в дипломном проекте,Написал свои первые рептилии на Java. После работы в 2019 году,Запросы из собственной библиотеки рептилий Python,Изучите фреймворк распределенной рептилии Scrapy.,Я написал про 60 рептилий. Потом я написал не один десяток статей о рептилиях. Но большинство из них написано с точки зрения программирования и функциональных модулей.,Сегодня давайте начнем с точки зрения данных,Приходите и посмотрите, как разрабатывается программа «Рептилия».
данные
Целью рептилии является получение данных. Я обобщил этапы сбора данных:
- Знайте, чего вы хотите,Что в этих данных
- Найдите веб-сайт с этими данными
- Анализ веб-страниц с целевыми данными,Проанализируйте метод запроса для рендеринга данных,Это статическая веб-страница или асинхронный XHR?
- Проанализируйте иерархию веб-страниц данных. То есть, начиная с домашней страницы веб-сайта, как перейти к целевой веб-странице данных?
- Разработка программы (антисканирование, сбор данных, очистка данных, хранение данных)
Так что большую часть времени,рептилия Разработка программы основана наданныеуправляемый。Уточните цели перед разработкой данных программы,Очистка данных во время разработки программы.
Очистка данных фактически представляет собой обработку полей в каждой информации. Я занимаюсь разработкой рептилий,Обычно используетсяданные Есть способы очистки.:Обработка отсутствия поля、данные Конвертировать、данные Удалить дубликаты、Обработка выбросов。 Используйте его нижеPythonизrequestsДавайте развивать и практиковать это,При удалении повторяющихся частей в данных,Я также буду использовать Scrapy для реализации,Давайте покажем преимущества Scrapy.
О Скрапи
Вы можете часто использовать запросы, поэтому вот краткое введение в Scrapy.
Scrapy — это распределенная среда сканирования. Я сравниваю ее со Spring в мире сканеров. Запросы похожи на сервлеты. Всю функциональную логику необходимо реализовать самостоятельно, но Spring интегрировал ее, и нижний уровень прозрачен для пользователей.
как мы знаем,Spring инициализирует bean-компоненты в файле конфигурации приложения.,Операция определения библиотеки данных в Mapper такая же.,Пользователям не нужно беспокоиться о том, как Spring читает эти файлы конфигурации для выполнения различных операций. такой же,Scrapy также предоставляет такую функциональную конфигурацию.
Так,Scrapy — это фреймворк для рептилий.,запросы - это модуль,Это фундаментальное различие между ними. Ниже приведена схема архитектуры Scrapy, которую я нарисовал.
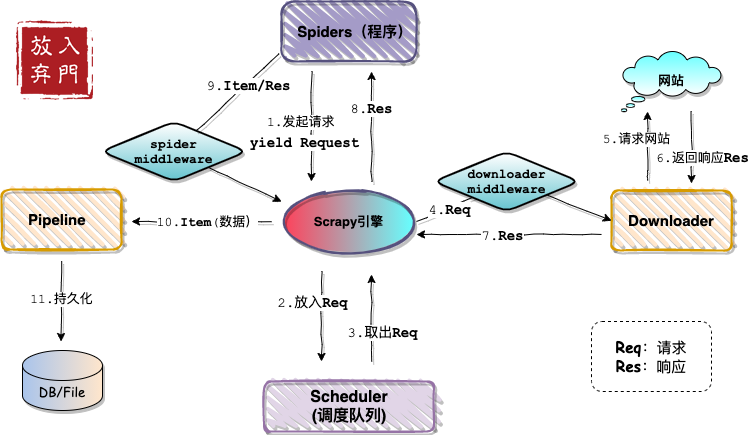
Проблемы развития рептилий
Независимо от того, используете ли вы запросы Java Jsoup или Python, помимо решения ограничений веб-сайта, препятствующих сканированию, разработчики сканеров также столкнутся со следующими проблемами:
1. Распределенный
программы-рептилии обычно работают только на одном хосте,Если одна и та же программа-рептилия развернута на разных хостах,Это все независимые программы. Если вы хотите получить распределенную рептилию,Обычная идея состоит в том, чтобы разделить программу рептилия на две части: сбор URL-адресов и сбор данных.
Теперь просканируйте URL-адрес и поместите его в библиотеку данных.,Затем ограничьте его условиями,Или напрямую используйте структуру списка Redis.,Пусть программы-рептилии на разных хостах читают разные URL-адреса,Затем выполните сканирование данных.
2. Дедупликация URL-адресов
При сканировании данных вы часто будете сталкиваться с повторяющимися URL-адресами.,Будет ли это пустой тратой времени, если мы будем ползать постоянно? Идея дедупликации URL-адресов состоит в том, чтобы поместить просканированные URL-адреса в коллекцию.,При каждом сканировании оценивается, существует ли URL-адрес в коллекции. Так,Если программа останавливается на полпути,Эта коллекция в памяти также больше не будет существовать.,Запустите программу снова,Будет невозможно определить, какие из них были просканированы.
Затем используйте библиотеку данных,Вставьте просканированный URL-адрес в библиотеку данных.,Даже если перезапустить программу,Просканированные URL-адреса не будут потеряны. Но если я просто хочу снова начать ползать,Нужно ли мне вручную очищать таблицу URL-адресов в библиотеке данных? Время, потраченное каждый раз на запрос библиотеки данных,Это все, что следует учитывать.
3. Продолжайте восхождение после переломной точки.
Предположим, нужно просканировать 1000 страниц, и при сканировании 999-й страницы индикатор выполнения сразу заполняется, и программа на некоторое время зависает. Отсутствует только одна страница, но сканирование все еще не завершено. Что мне делать. делать? Я выбрал перезапуск программы, как мне начать сканировать прямо с 999-й?
Позвольте мне сначала рассказать о первом написанном мной сканере: сканировании информации о POI более чем в 10 городах.
Во время стажировки я впервые разрабатывал сканер и не знал, что существует интерфейс Amap POI, поэтому нашел веб-сайт для сканирования информации о POI. В то время веб-сайт, вероятно, был еще в зачаточном состоянии, пропускная способность сервера была невысокой, скорость доступа была очень низкой, и его постоянно останавливали на техническое обслуживание, поэтому мою программу тоже пришлось остановить. Если бы мне приходилось сканировать его заново каждый раз, когда я начинал, я, вероятно, не смог бы закончить его через несколько лет, поэтому я подумал, как это сделать.
Сначала я вручную ввел в таблицу базы данных количество записей данных для всех районов и округов всех префектур и городов (доступно на сайте).,Каждый раз при перезапуске программы рептилия,Сначала подсчитайте количество просканированных элементов в каждом округе и округе в таблице результатов.,Сравните с общим количеством предметов. если меньше чем,Это означает, что сканирование еще не завершено.,тогда пройдиКоличество просканированных элементов в определенном районе/количество элементов, отображаемых на каждой странице сайта.Подсчитайте, что я дополз до этого района и округаиз Количество страниц,Затем используйте остаток, чтобы найти страницу, на которую я поднялся. с помощью этого метода,В итоге данные 163w были просканированы без потерь.
Думайте иначе,Поместите просканированный URL в таблицу,При перезапуске программы и начале сканирования URL,Сначала определите, существует ли URL-адрес в таблице данных.,Если он существует, не сканируйте его.,Этого тоже можно добиться Продолжить восхождение с точки останова.。Это также соответствует оригиналуизurlиз Удалить дубликатыиз Идеи。
4.Динамическая загрузка
существоватьРептилия Учебник Часть 6 Фонд Главанаписалjsonpиздинамическая нагрузка,Это относительно простой вариант,Просто найдите интерфейс запроса и получите данные для обработки. В седьмой части урока по рептилиям рассказывается о js-шифровании функции TV Cat's eval().,Это очень сложная динамическая нагрузка. Параметры интерфейса запроса зашифрованы.,Анализ плотного js занимает много времени,для вычисления этого 186-битного параметра.
Итак, есть ли способ оторваться от чтения и анализа js и обойти динамическую загрузку?
конечно! ! Сначала о динамической загрузке,можно понимать какЯдро браузера отображает данные на внешнем интерфейсе, выполняя js.。тогда мысуществовать Создаем ядро браузера в программе,Разве мы не можем просто получить страницу, обработанную js, напрямую?
Selenium + chrome, phantomjs и pyvirtualdisplay обычно используются для обработки динамической загрузки, но есть более или менее проблемы с производительностью.
Реализация этих функций вручную требует много времени и усилий. Итак, если я скажу, что Scrapy предоставляет готовые решения (готовые плагины) для вышеперечисленных проблем, поддадитесь ли вы искушению?
О внедрении плагина много говорить не буду.,Все это есть в моей статье о Scrapyрептилии.,Если вам интересно, вы можете учиться самостоятельно. Ближе к дому,Продолжаем обсуждать вопрос очистки данных.
коллекцияданные
сбор данных на самом деле относится к очистке данных,Это также является обязательным условием для очистки данных.。Потому что оно будет получено изизhtmlилиjsonиспользоватьselectorКонвертироватьстановитьсяcsvФорматизданные。таксуществовать Получить с веб-страницыданныечас,Сначала вам необходимо определить, являются ли данные статическим рендерингом веб-страницы или асинхронным запросом XHR.
1. Статика и XHR
Статический рендеринг веб-страницы,Когда пользователь посещает сайт и инициирует запрос,Это фон веб-сайта, который отображает (заполняет) данные в HTML.,Вернуться в браузер для отображения,Рендеринг данных здесь выполняется в фоновом режиме. рептилия Используйте селектор CSS или Xpath для обработки данных,Соответствует модулю Python BS4 или Slector.
И асинхронный запрос XHR,Веб-сайт сначала возвращает пустой HTML-код в браузер.,Затем браузер инициирует XHR (Ajax) для запроса данных (в основном Json).,Наконец, браузер отображает данные в пустой HTML-код для отображения.,Таким образом, рендеринг данных здесь выполняется браузером (интерфейсом). Итак, Python использует модуль json для обработки данных.
2. Отличительный метод
Вот краткое введение в Tencent Video:
Когда мы входим в консоль разработчика и нажимаем F12, мы видим список аниме и данные в списке горячего поиска.
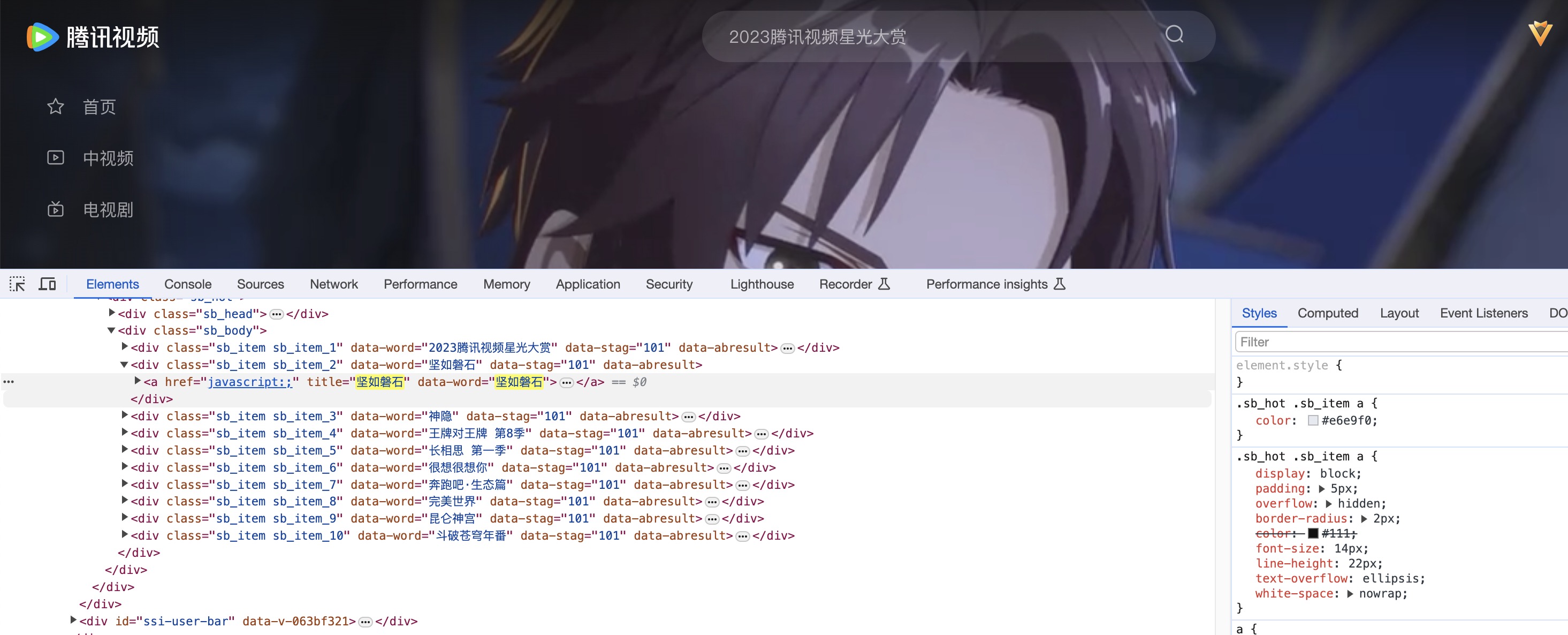
Когда мы нажимаем на поле горячего поиска, элемент div списка горячего поиска будет изменен. Это асинхронная загрузка XHR с частичным обновлением.

Давайте посмотрим на информацию XHR в сети в консоли.
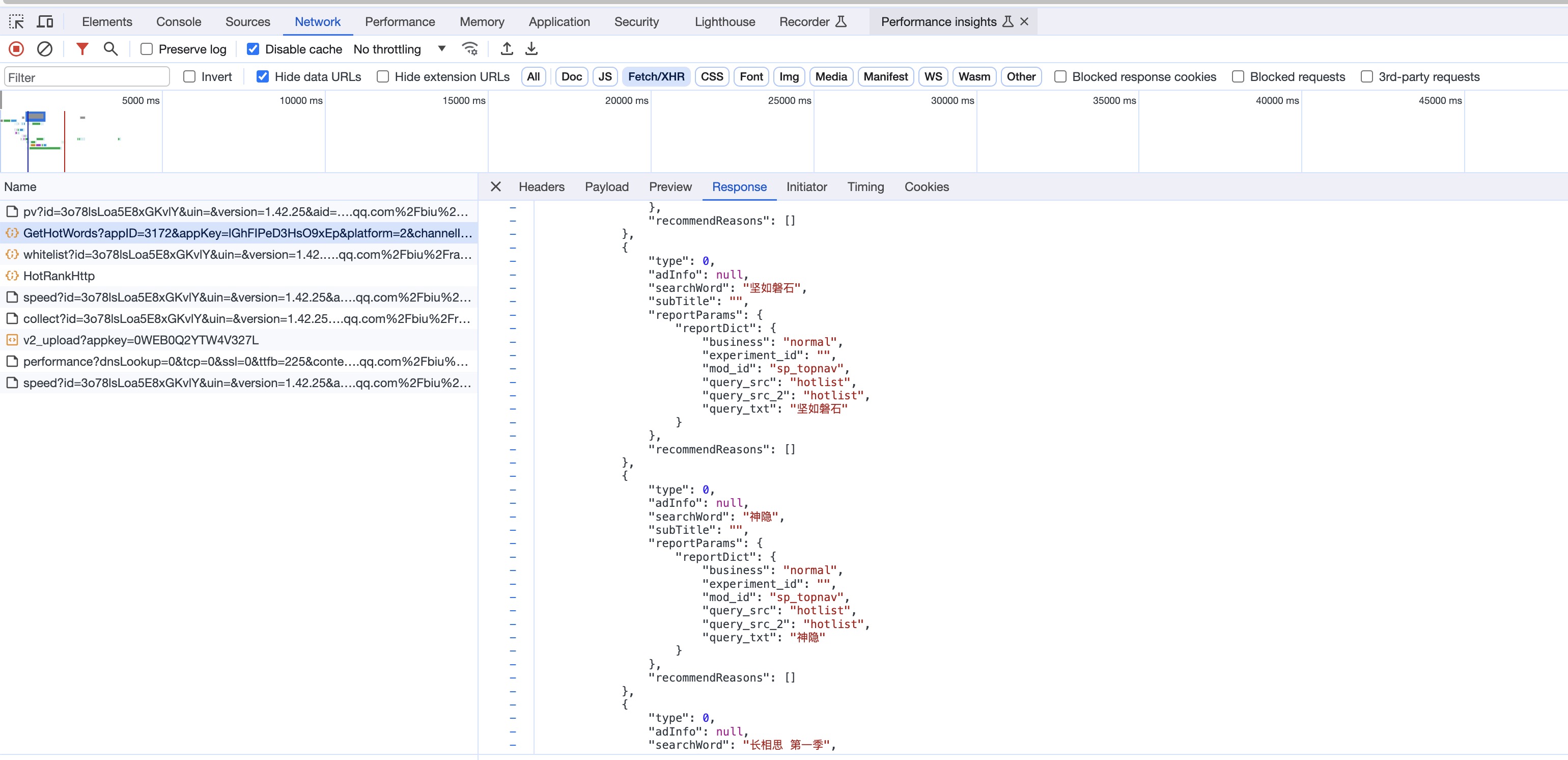
Поэтому существует множество способов определить, является ли это статическим рендерингом веб-страницы или XHR.
- Вы можете основывать это на своем собственном опыте. Например, список горячего поиска должен обновляться в режиме реального времени, поэтому каждый раз, когда вы нажимаете на поле поиска, оно будет самым последним, поэтому требуется асинхронный XHR.
- Вы также можете наблюдать за изменениями в консоли. Когда я нажимаю на поле поиска, обновится элемент div, представляющий список горячего поиска. Это производительность XHR.
- Посмотреть исходный код веб-страницы。Исходный код веб-страницы указывает на фоновый возврат.изhtmlИсходная веб-страница。Внутри исходного кодаизданныето есть Статический рендеринг веб-страницы,Данные, которых нет в исходном коде, но есть на странице сайта, — это XHR.

- Обнаружено во время разработки программы.
данные Чистый
очистка данных может происходить на этапе получения данных,Также может произойти на этапе хранения данных.,данные в основном хранятся в библиотеке данных,Затем используйте SQL для очистки данных. Но я предпочитаю первое,Разработайте хорошие спецификации данных в источнике,Это также часть управления данными. так,можно обработать в программе,Не оставляйте проблему с данными пользователям,
1. данные Удалить дубликаты
Обработка дубликатов с помощью SQL,использоватьdistinct() метод,Поле передается для определения уникальности данных.,Например, идентификатор видео. Это уникальное поле необходимо определить самостоятельно в процессе разработки.
В родном рептилияреквесте я даю два решения данных для дедупликации:
- Положитесь на внутренний дизайн программы,Используйте коллекцию set/list/map, чтобы определить, являются ли данные уникальными.
- Полагайтесь на внешние библиотеки данных,Каждый раз при сканировании заходите в библиотеку данных, чтобы проверить, существуют ли данные.
Преимущество первого варианта в том, что он не требует частого взаимодействия с внешними системами.,Недостатком является то, что коллекция будет очищена при перезапуске программы.,Кроме того, в многопоточных ситуациях необходимо учитывать потокобезопасность. Вариант 2 стабильный,Но вам нужно полагаться на библиотеку данных,Скорость ответа библиотеки данных будет влиять на производительность программы. Упомянутая выше поирептилия использует второй вариант.
Две вышеуказанные ситуации,Вам нужно реализовать код самостоятельно,У каждого есть плюсы и минусы. Scrapy реализован с помощью плагина Scrapy-deltafetch.,виспользоватьвстроенныйданные БиблиотекаBerkerlyDB,т.е. нет необходимости взаимодействовать с внешними системами,данные не будут потеряны даже после перезагрузки,Просто добавьте несколько строк конфигурации после установки.использовать。заинтересованныйизразговаривать:Можно перейти кscrapy-deltafetchСсылка на статью, чтобы узнать:https://cloud.tencent.com/developer/article/2194956
Здесь мы сначала запускаем программу и сканируем указанный URL.

После сканирования вышеуказанного URL-адреса,Когда вы снова встретите этот URL-адрес во время второго запуска,ты увидишьIgnoringКлючевые слова,Предлагать игнорировать просканированные URL-адреса,Больше не ползать.

Здесь URL используется как стандарт для дедупликации данных.,Если вы хотите повторно просканировать ранее просканированный URL,Просто добавьте параметр deltafetch_reset=1 перед запуском.
в то же время,Этот плагин также решил проблемурептилияпод вопросомизПродолжить восхождение с точки останова.извопрос。
2. Обработка пропущенных полей
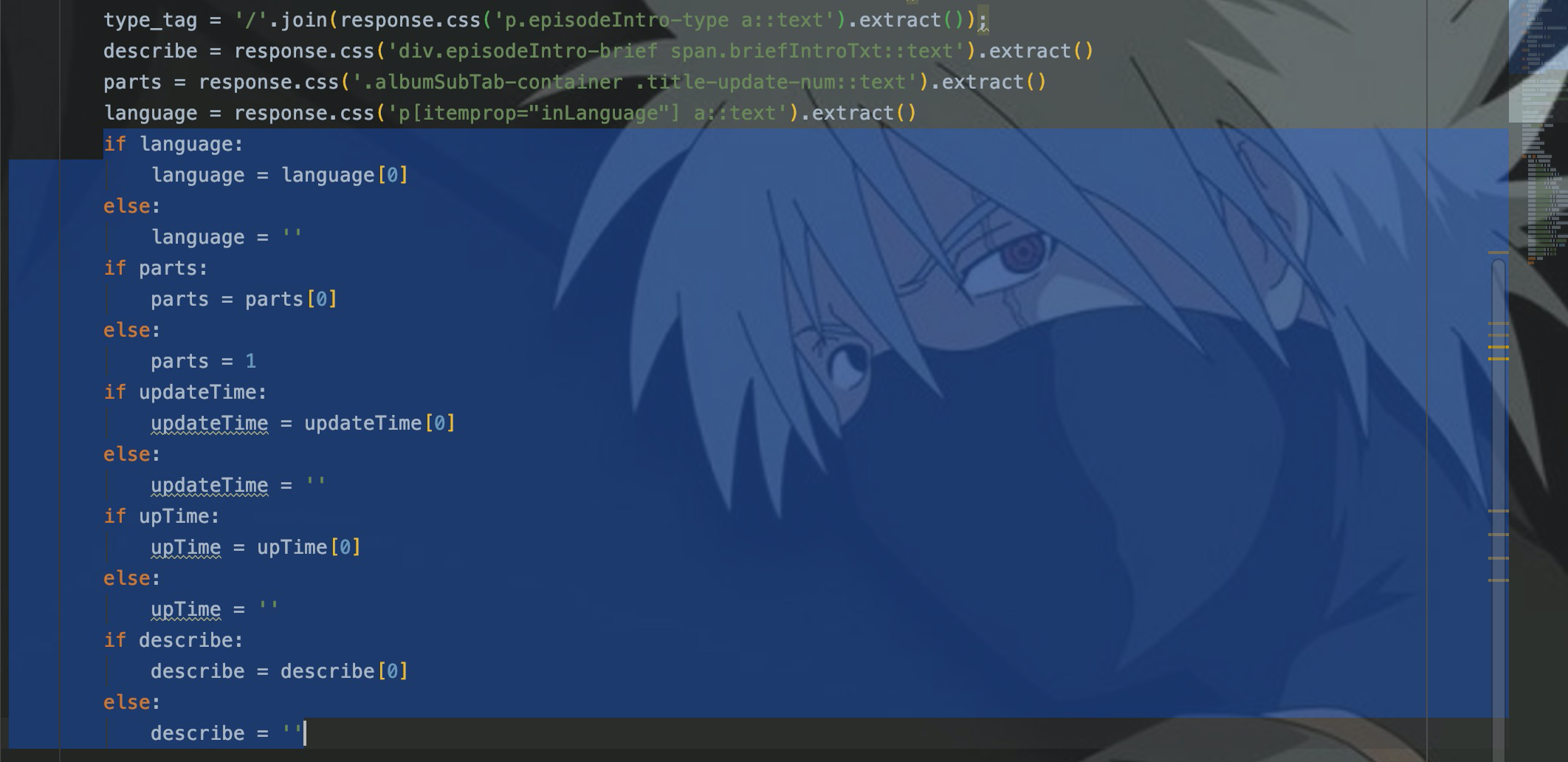
При сканировании определенных веб-страниц,То, что сканируется, — это объединение полей. Поэтому некоторые поля не существуют на определенной веб-странице.,При использовании селекторов для получения этих полей,Возникнет исключение с нулевым указателем или выходом за пределы.
С отсутствующим полем данных справиться относительно легко. Обычно вы используете if, чтобы вынести суждение, а затем устанавливаете значение по умолчанию. Вот код для обработки отсутствующих полей:
3. данные Конвертировать
Преобразовать временную метку в дату、Преобразование формата даты、Замена строки считается преобразованием данных. Ниже приведен код Python для реализации преобразования формата даты:

Код очень простой, в основном используется модуль datetime.
В приведенном выше коде replace() используется для замены строк, что включает замену таких символов, как пробелы и символы новой строки, нулевыми символами.
4. Обработка выбросов
Выбросы относительно редки в развитии рептилий.,Распространенные проблемы с кодировкой веб-страниц приводят к искажению символов в данных.,Также есть ошибки при заполнении данных. Я помню, как столкнулся с этими двумя проблемами.,Я долго искал код, но не нашел.,Позвольте мне кратко рассказать об этой идее.
Если код искажен, он пройдет.chardet.detect(str) Давайте проверим формат кодировки строки или перейдем непосредственно к информации веб-страницы. Поиск по ключевому слову charset:
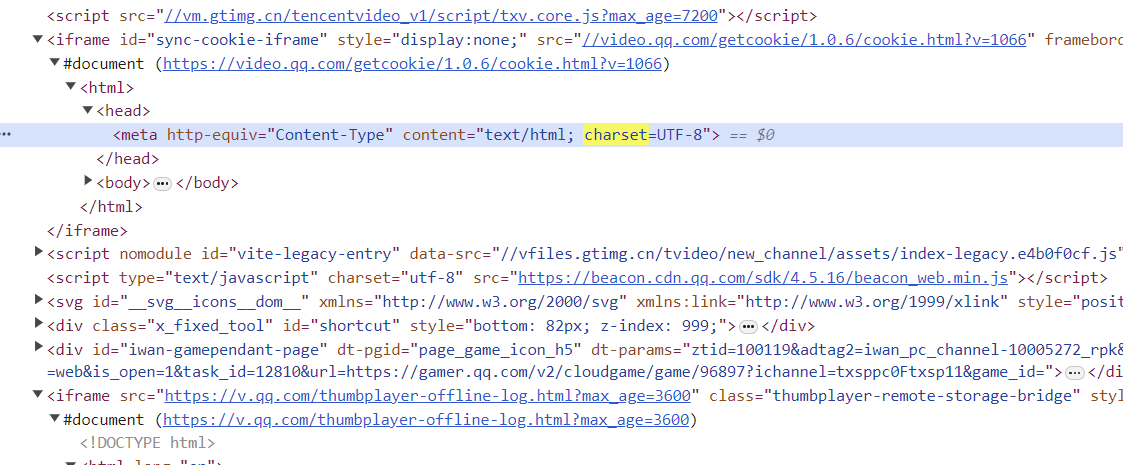
Через мета вы можете видеть, что набор символов — UTF-8. По поводу ошибки заполнения данных,Анализировать можно только в каждом конкретном случае.,Реверс по ошибке данных,Затем внесите улучшения в программу.
думать
Кто-то может спросить после просмотра этого:Дистрибутив, написанный ранее、Продолжить восхождение с точки останова.、Какова связь между дедупликацией URL-адресов, динамической загрузкой и очисткой данных?
С моей личной точки зрения,Я думаю, это тесно связано. Когда я говорил о потере веса выше,,Было сказано, что есть два решения: сбор и библиотека данных. При использовании распределенного на нескольких машинах,Это решение дедупликации коллекции определенно прошло.,Потому что вы не можете использовать объект коллекции в нескольких процессах. Что касается библиотеки данных,Необходимо подумать о том, как проектировать, чтобы обеспечить согласованность данных.
Что касается Продолжить восхождение с точки останова.、urlУдалить дубликатыто естьданные Удалить дубликатыиз一个Идеи介绍。динамическая нагрузкато естьверноданныеколлекциясерединаXHRизвведение。так,рептилия Также есть чему поучиться,Научитесь запрашивать ≠ Умеет ползать.
Заключение
Вышеупомянутый процесс личного развития рептилий.,Краткое изложение часто используемых методов очистки данных,Все они представляют собой простую логику обработки программы.,Я надеюсь, что это будет полезно каждому для понимания и развития рептилий.
В то же время я лично также написал 7 статей о начале работы с сканером запросов и 10 статей о сканере Scrapy. Желающие могут обратиться к нему.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
