30 000 слов подробного анализа последней обзорной работы Университета Цинхуа: обзор эффективного вывода больших моделей.

Глубокое обучение обработке естественного языка Оригинал Автор: fanmetasy
Крупные модели привлекли всеобщее внимание благодаря своим отличным характеристикам в различных задачах. Однако огромные требования к вычислительным ресурсам и памяти для вывода больших моделей создают проблемы для их развертывания в сценариях с ограниченными ресурсами. Отрасль усердно работает над разработкой методов, предназначенных для повышения эффективности вывода больших моделей. В этой статье представлен всесторонний обзор и краткое изложение существующей литературы по эффективному выводу больших моделей. Сначала анализируются основные причины низкой эффективности рассуждений больших моделей, а именно большой размер параметров модели, квадратичная сложность операции вычисления внимания и метод авторегрессионного декодирования. Затем вводится комплексная таксономия, которая делит существующие усилия по оптимизации на оптимизацию на уровне данных, уровне модели и оптимизации на уровне системы. Кроме того, в этой статье также проводятся сравнительные эксперименты по репрезентативным методам в ключевых областях, анализируется и дается определенная информация. Наконец, подводятся итоги соответствующей работы и обсуждаются будущие направления исследований.
бумага:A Survey on Efficient Inference for Large Language Models адрес:https://arxiv.org/abs/2404.14294
1 Introduction
В последние годы большие модели привлекли широкое внимание научных кругов и промышленности.
Область LLM пережила значительный рост и заметные достижения. Появилось множество LLM с открытым исходным кодом, в том числе серии gpt (GPT-1, GPT-2 и GPT-3), OPT, серии lama (LLaMA, LLaMA 2, BaiChuan 2, Vicuna, LongChat), BLOOM, FALCON, GLM и Мтаистраль [12], они используются для академических исследований и коммерческого внедрения. Успех больших моделей обусловлен их мощной способностью решать различные задачи, такие как понимание нейронного языка (NLU), генерация нейронного языка (NLG), вывод и генерация кода [15], что позволяет реализовать такие влиятельные проекты, как ChatGPT, Copilot, и приложение Бинг. Все больше и больше людей считают, что [16] рост и достижения ученых LMM знаменуют собой большой шаг человечества вперед к общему искусственному интеллекту (AGI).
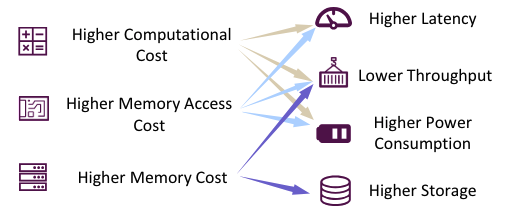
Рисунок 1. Проблемы развертывания большой модели
Однако внедрение LLM не всегда проходит гладко. Как показано на рисунке 1, в процессе вывода использование LLM обычно требует более высоких вычислительных затрат, стоимости доступа к памяти и объема памяти. (Анализ первопричин см. в разделе 2.3.) Эффективность вывода также будет снижена в сценариях с ограниченными ресурсами (например, задержка, пропускная способность, энергопотребление и хранилище). Это создает проблемы для применения LLM как в терминальных, так и в облачных сценариях. Например, огромные требования к объему памяти делают непрактичным развертывание модели с параметрами 70B на персональном ноутбуке для помощи в разработке. Более того, если LLM используется для каждого запроса поисковой системы, низкая пропускная способность приведет к огромным затратам, что приведет к значительному снижению прибыли поисковых систем.
К счастью, было предложено большое количество методов для достижения эффективного вывода LLM. Чтобы получить всестороннее понимание существующих исследований и стимулировать дальнейшие исследования, в этой статье используется иерархическая классификация и систематическое резюме текущей эффективной работы по выводам LLM. В частности, существующая работа разделена и организована на оптимизацию на уровне данных, модели и системы. Кроме того, в статье представлен экспериментальный анализ репрезентативных методов в ключевых областях для консолидации знаний, даны практические рекомендации и рекомендации для будущих исследований.
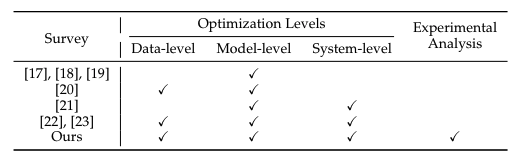
Таблица 1: Итоговое сравнение
В настоящее время обзоры [17], [18], [19], [20], [21], [22] посвящены области LLM. Эти обзоры в основном сосредоточены на различных аспектах эффективности LLM, но предоставляют возможности для дальнейших улучшений. Чжу и др. [17], Парк и др. [18] и Ван и др. [19] сосредоточили обзор на технологии сжатия моделей, которая представляет собой оптимизацию на уровне модели. Динг и др. [20] сосредоточились на архитектуре данных и моделей. Мяо и др. [21] изучили эффективное обоснование LLM с точки зрения исследования систем машинного обучения (MLSys). Напротив, в этой статье представлен более полный объем исследований, которые касаются оптимизации на трех уровнях: уровне данных, уровне модели и уровне системы, а также охватывают недавние исследовательские усилия. Ван и др. [22] и Сюй и др. [23] также провели комплексный обзор эффективных исследований LLM. На основе экспериментального анализа, проведенного в нескольких ключевых областях, таких как количественная оценка моделей и сервер моделей, в этой статье представлены практические идеи и предложения путем интеграции сравнительных экспериментов. Как показано в Таблице 1, представлены сравнения различных обзоров.
Структура этой статьи разделена следующим образом: Глава 2 знакомит с основными понятиями и знаниями LLM, а также проводит подробный анализ узких мест эффективности в процессе рассуждения LLM. В главе 3 представлена таксономия, предложенная в этой статье. В главах 4–6 представлены и обсуждаются соответствующие работы на трех разных уровнях оптимизации. В главе 7 представлено более широкое обсуждение нескольких ключевых сценариев применения. В главе 8 суммированы основные положения данного обзора.
2 Preliminaries
2.1 LLM архитектуры трансформатора
Языковое моделирование, как основная функция языковой модели, включает моделирование вероятности последовательностей слов и прогнозирование распределения вероятностей последующих слов. В последние годы исследователи обнаружили, что увеличение размера языковых моделей не только улучшает возможности языкового моделирования, но и создает возможность решать более сложные задачи в дополнение к традиционным задачам НЛП [24]. языковые модели (LLM).
Крупные модели массового спроса разрабатываются на основе архитектуры Transformer [25]. Типичная модель архитектуры трансформатора состоит из нескольких блоков трансформаторов, расположенных друг над другом. Обычно блок трансформатора состоит из модуля многоголового самообслуживания (MHSA), нейронной сети прямого распространения (FFN) и уровня LayerNorm (LN). Каждый блок трансформатора получает выходные характеристики предыдущего блока трансформатора в качестве входных данных, последовательно отправляет характеристики в каждый субмодуль и, наконец, выводит их. В частности, перед первым блоком преобразователя необходимо использовать токенизатор для преобразования традиционного входного предложения в последовательность токенов, а затем использовать слой внедрения для преобразования последовательности токенов во входные функции. К входной функции добавляется дополнительное позиционное внедрение для кодирования порядка входных токенов.
Ядром архитектуры Transformer является механизм самообслуживания, который используется в модуле многоголового самообслуживания (MHSA). Вход пары модулей MHSA
После линейного преобразования получаются векторы Q, K и V, как показано в формуле (1):
в
это входная функция,
для первого
Матрица трансформации головы внимания. Затем к каждому применяется операция самообслуживания (
) кортеж и получить
Характеристики головы внимания
, как показано в формуле (2):
в
Размерность запроса (ключа). Вычисления с самообслуживанием включают умножение матриц, вычислительная сложность которых квадратична длине входных данных. Наконец, модуль MHSA объединяет характеристики всех головок внимания и выполняет над ними преобразование матрицы отображения, как показано в формуле (3):
в
является матрицей отображения. Механизм самообслуживания позволяет модели определять важность различных входных частей без учета расстояния и, таким образом, может получать зависимости на больших расстояниях и сложные взаимосвязи входных предложений.
Еще один важный модуль трансформаторного блока: FFN устанавливается после модуля многоголовочного самообслуживания (MHSA) и содержит две нелинейные функции активации. Он получает выходные характеристики модуля MHSA.
Как показано в формуле (4), расчет производится:
в,
и
- весовая матрица двух линейных слоев,
это функция активации.
2.2 Процесс вывода большой модели
Наиболее популярные большие модели, например модели с архитектурой только декодера, обычно используют авторегрессионные методы для генерации выходных операторов. Авторегрессионный метод выводит токены один за другим. На каждом этапе генерации большая модель принимает в качестве входных данных все предыдущие последовательности токенов, включая входной токен и только что сгенерированный токен, и генерирует следующий токен. По мере увеличения длины последовательности существенно возрастают и временные затраты на генерацию текста. Для решения этой проблемы предлагается ключевая технология — кэш-ключ-значение (KV) для ускорения генерации текста.
Технология кэширования KV,Включено в блок Бычьего внимания к себе (MHSA).,Сохраните и повторно используйте вектор ключа (K) и вектор значений (V), соответствующий предыдущему токену. Эта технология широко использовалась в рассуждениях по большим моделям.,Потому что он реализует огромную оптимизацию задержки генерации текста. На основе этой технологии,Процесс рассуждения Большой Модели можно разделить на два этапа:
- ①prefillingэтап:большой Модель Посчитать и объединитьхранилищеисходный вводtokenизKVкэш,и сгенерируйте первый выходной токен,Как показано на рисунке 2(а)
- ②decodingэтап:большой МодельиспользоватьKV Кэш выводит токены один за другим и обновляет кэш KV парами K, V (ключ-значение) вновь сгенерированных токенов.
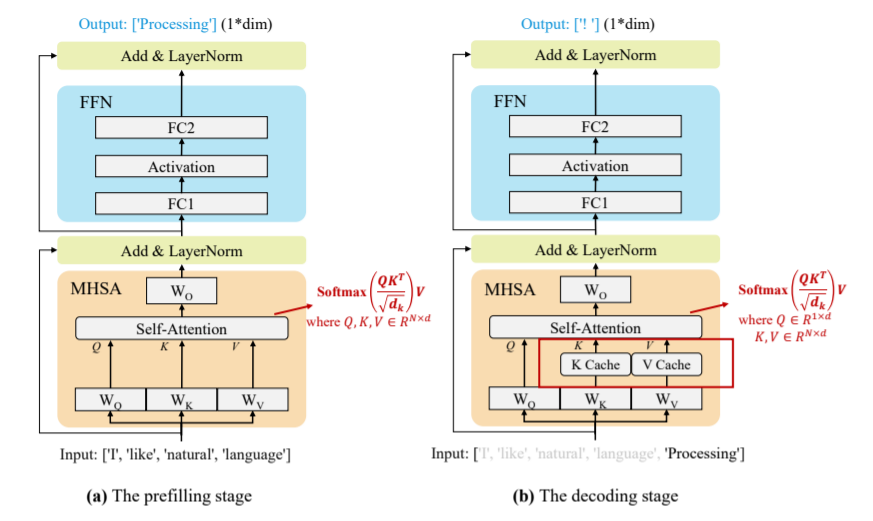
Рисунок 2. Принципиальная схема применения технологии KV-кэша при рассуждениях на больших моделях.
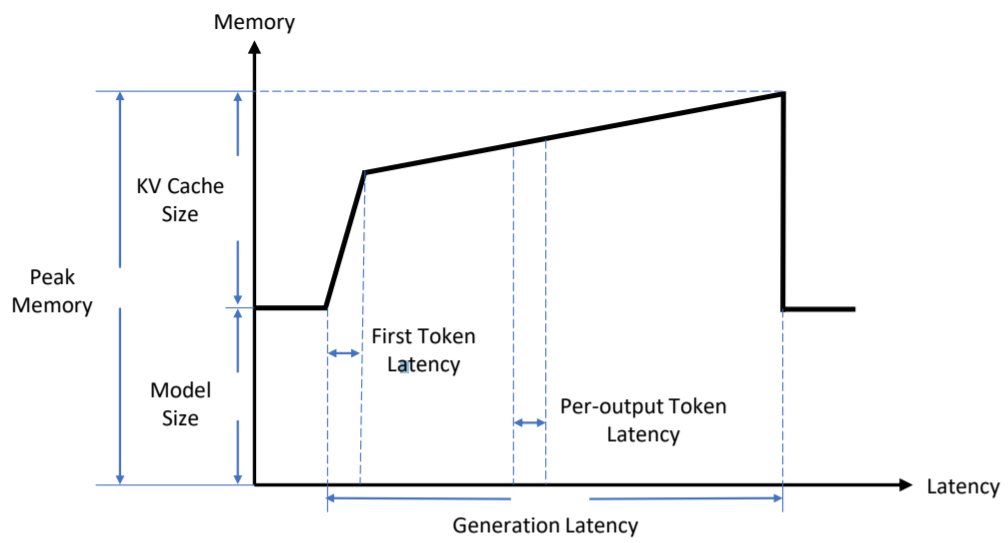
Как показано на рисунке 3, показаны ключевые показатели повышения эффективности рассуждений. По горизонтальной оси Latency (задержка, на этапе предварительного заполнения (предзаполнения) первого token Задержка записывается как время генерации первого токена на этапе декодирования для каждого вывода; token Задержка записывается как среднее время создания токена. Кроме того, поколение задержка представляет собой время вывода всей последовательности токенов. Для вертикальной оси Память (память), модель размер используется для представления размера памяти и напряжения, необходимого для хранения весов модели. cache size представляет размер памяти для хранения кэша KV. Кроме того, пик Память представляет собой максимальную память, необходимую для проекта генерации. Это примерно модель размер и КВ cache и размер. Память для Модели веса и КВ кэша. Если не считать задержки, пропускная способность тоже большая. обслуживания Широко используемый индикатор в рассуждениях. жетон пропускная способность представляет собой количество токенов, генерируемых в секунду, запрос Пропускная способность представляет собой количество выполненных запросов в секунду.
2.3 Анализ эффективности рассуждений
В сценариях с ограниченными ресурсами,Развертывание больших данных и поддержание их эффективности и производительности являются огромными проблемами для промышленности и научных исследований. Например,Развертывание LLaMA-2-70B с 70 миллиардами параметров,Для загрузки весов в формате данных FP16 требуется 140 ГБ видеопамяти (VRAM).,Для рассуждения необходимо не менее 6 карточек. RTX 3090Ti Графический процессор (одна карта памяти 24 ГБ) или 2 NVIDIA A100 Графический процессор (одна карта памяти 80 ГБ). Что касается задержки вывода, 2 NVIDIA A100 Генерация токена на графическом процессоре занимает 100 миллисекунд. Таким образом, генерация последовательности с сотнями токенов занимает более 10 секунд. Помимо занятости Памяти и задержки вывода, необходимо учитывать пропускную способность и энергопотребление. Процесс рассуждения большой В моделях на приведенные выше показатели сильно повлияют три важных фактора. вычислительная стоимость стоимость), стоимость доступа к памяти (память access cost)и Памятьиспользовать(memory использование). Основная причина неэффективности вывода больших моделей требует сосредоточения внимания на трех ключевых факторах:
①Model Size:主流большой Модельв целом包含数十亿甚至万亿из参数。Например,LLaMA-70BМодель включает 70 миллиардов параметров.,GPT-3 имеет 175 миллиардов параметров. в процессе рассуждения,Размер модели оказывает существенное влияние на вычислительные затраты, стоимость доступа к Память и использование Память.
②Внимание! Операция: Как описано в 2.1 и 2.2.,На этапе предварительного заполнения,Вычислительная сложность операции самообслуживания равна квадрату входной длины.,Поэтому входная длина увеличивается,Затраты на вычисления, стоимость доступа к Память и использование Память значительно возрастут.
③Decoding Подход: авторегрессионное декодирование генерируется токен за токеном. в каждом декодировании step,Все веса моделей взяты из внешнего HBM чипа графического процессора.,Стоимость доступа к Память огромна. также,Кэш KV растет с длиной ввода,Может привести к разбросу Память и нерегулярному доступу к Память.
3 TAXONOMY
В приведенном выше разделе описаны ключевые факторы, влияющие на эффективность вывода Большой модели.,Например, стоимость расчета, стоимость доступа к Память и использование Память.,и дополнительно проанализировали основные причины:Model Size、Attention OperationиDecoding Подход. Было проведено множество исследований по оптимизации эффективности рассуждений с разных точек зрения. Отзыв от iПодвести Подводя итог этим исследованиям, в статье они разделены на три уровня оптимизации, а именно: оптимизация на уровне данных, Оптимизация. уровня моделии Оптимизация на уровне системы (показано на рисунке 4):

Рисунок 4. Классификация оптимизации производительности вывода большой модели
- Оптимизация уровня данных:Прямо сейчаспроходитьоптимизациявходитьprompt(Например,сжатие входных данных) или лучше организовать выходной контент (например,,выходная организация). Этот тип оптимизации обычно не меняет исходную Модель.,Поэтому для Модели(в,Возможно, потребуется обучить небольшое количество вспомогательных Моделей, но стоимость обучения большой Модели соизмерима со стоимостью обучения большой С сравнения.,Эту стоимость можно игнорировать).
- Оптимизация уровня модели: то есть во время вывода Модели путем разработки эффективной структуры Модели (например, эффективного структурного проектирования) или сжатия предварительно обученной Модели (например, Сжатие модели) для оптимизации рассуждений, эффективности. Первый тип оптимизации обычно требует дорогостоящего предварительного обучения или небольшой тонкой настройки для сохранения или восстановления стоимости возможностей Модели, в то время как второй тип обычно приводит к снижению производительности Модели.
- Оптимизация на уровне системы:Прямо сейчасоптимизациямашина устройство или сервисная система. машина выводаизоптимизация Нет необходимости продолжать Модельтренироваться,Оптимизация сервисной системы еще более безопасна для производительности Модели. также,В статье также кратко представлен проект аппаратного ускорения эскадрильи в главе 6.3.
4. Оптимизация уровня данных
Оптимизация уровня данных Работу этого года можно разделить на две категории.,Например, оптимизация сжатия ввода или организация вывода. Технология сжатия входных данных напрямую сокращает длину входных данных модели, чтобы уменьшить потери при рассуждениях. Технология организации одновременного вывода обеспечивает пакетный (параллельный) вывод путем организации структуры выходного контента.,Этот метод может улучшить использование оборудования и уменьшить задержку генерации модели.
4.1 Сжатие входных данных
При практическом применении больших моделей слова-подсказки имеют решающее значение. Во многих работах предложены новые методы разработки слов-подсказок. Они на практике показали, что тщательно разработанные подсказки могут повысить производительность больших моделей. Например, контекстное обучение (In-Context Обучение) рекомендует включать в подсказку несколько соответствующих примеров. Этот метод может стимулировать обучение больших моделей по аналогии. Цепочка мыслей, COT)технология则是существовать上下文из示例中加入一系列中间израссуждение步骤,Используется, чтобы помочь большой модели выполнить сложные рассуждения. Однако,Эти связанные методы работы с ключевыми словами неизбежно приводят к созданию более длинных ключевых слов.,это вызов,Потому что вычислительные затраты во время предварительного заполнения увеличатся вдвое (как показано в разделе 2.3).
Чтобы решить эту проблему, была предложена технология сжатия входных подсказок, позволяющая сократить длину слов подсказки без существенного влияния на качество ответа большой модели. С точки зрения этой технологии, соответствующие исследования можно разделить на четыре аспекта, как показано на рисунке 5: Быстрое вырезание слов (подсказка обрезка), подсказка краткого описания слов (подсказка резюме), мягкое сжатие на основе подсказок (мягкое prompt-based compression)и Генерация улучшения поиска (поиск augmented generation, RAG)。
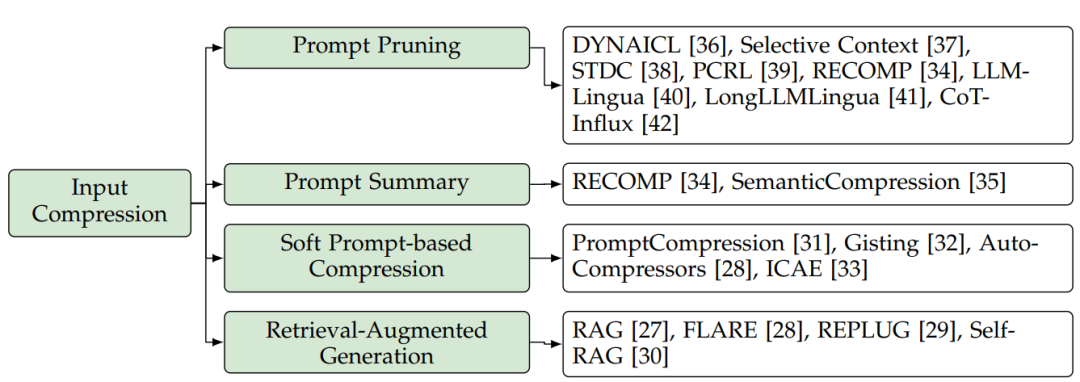
Рисунок 5. Классификация методов сжатия входных данных для больших моделей.
4.1.1 Своевременная обрезка
Основная идея обрезки слов в подсказке заключается в удалении неважных токенов, утверждений или документов онлайн из подсказки ввода на основе заранее определенных или изученных ключевых показателей. DYNAICL предлагает динамически определять оптимальное количество примеров контекста для данного ввода с помощью обученного контроллера на основе большой модели. Селективный Контекст В этом документе предлагается объединить токены в несколько единиц, а затем использовать индикатор, основанный на собственной информации (например, отрицательный log Подскажите отсечение на уровне единицы для вероятности). STDCбумага выполняет оперативное сокращение слов на основе дерева синтаксического анализа, которое итеративно удаляет узлы фраз, которые вызывают минимальное снижение производительности после сокращения. PCRLбумага представляет схему сокращения на уровне токена, основанную на обучении с подкреплением. Основная идея PCRL заключается в обучении политики путем объединения точности и сжатия С выравнивания в функцию вознаграждения. Точность измеряется путем расчета сходства между обрезанной выходной подсказкой и исходным словом подсказки. Метод RECOMP реализует стратегию сокращения на уровне предложений для сжатия языка с расширенными поисковыми возможностями. Language Models, РАЛМ) советы. Метод заключается в использовании предварительно обученного кодировщика для кодирования входного вопроса и документа в скрытую форму. встраивание. Затем он решает, какие документы удалить, основываясь на том, насколько похоже встраивание документа на проблемное встраивание. LLMLingua представляет схему обрезки от грубого к мелкому для быстрого сжатия. Первоначально он выполняет сокращение на демонстрационном уровне, а затем сокращение на уровне токена на основе недоумения. Для повышения производительности LLMLingua предлагает контроллер бюджета, который динамически распределяет бюджет обрезки между различными частями слова-подсказки. Кроме того, он использует итеративный алгоритм сжатия на уровне токена для устранения неточностей, вызванных предположением условной независимости. LLMLingua также использует стратегию выравнивания распределения, чтобы согласовать выходное распределение целевой большой модели с меньшей большой моделью, используемой для расчета недоумения. LongLLMLingua[41] вносит некоторые усовершенствования на основе LLMLingua: (1) Он использует условие недоумения для входного вопроса в качестве индикатора быстрого вырезания слов. (2) Он назначает разные коэффициенты обрезки различным представлениям и меняет их порядок в окончательных ключевых словах в соответствии с их индексными значениями. (3) Восстановите исходный контент на основе ответа. CoT-Influx представляет метод использования обучения с подкреплением для выполнения грубой и мелкозернистой адаптации слов-подсказок цепочки мыслей (CoT). В частности, сначала будут удалены неважные примеры, а затем продолжится удаление неважных токенов из оставшихся примеров.
4.1.2 Краткое описание
Основная идея сводки слов-подсказки состоит в том, чтобы сжать исходные слова-подсказки в более короткое резюме, сохраняя при этом аналогичную семантическую информацию. Эти методы также можно использовать в качестве методов онлайн-сжатия подсказок. В отличие от ранее упомянутого метода обрезки слов подсказки, который оставляет необрезанные пометки, этот однострочный подход преобразует всю подсказку в краткое изложение. RECOMP [34] представляет абстрактный компрессор (Abstract Compressor), который принимает входной вопрос и полученные документы в качестве входных данных и генерирует краткое резюме. В частности, он извлекает легкие компрессоры из массивной модели Подвести. итог Работа. SemanticCompression предлагает метод семантического сжатия. Сначала он разбивает текст на предложения. Затем он группирует предложения по теме. итоговые предложения в каждой группе.
4.1.3 Сжатие на основе мягких подсказок
Основная идея этой технологии сжатия заключается в разработке мягкого слова-подсказки, которое намного короче исходного слова-подсказки, в качестве входных данных большой модели. Мягкие слова-подсказки определяются как серия обучаемых последовательных токенов. Некоторые технологии используют автономное сжатие для слов подсказки с фиксированными префиксами (например, слова системной подсказки, слова подсказки для конкретной задачи). Например, PromptCompression обучает мягкие подсказки имитировать заранее определенные слова системных подсказок. Метод заключается в добавлении нескольких программных токенов перед входным токеном и позволяет корректировать эти программные токены во время обратного распространения ошибки. После точной настройки набора контрольных данных последовательность программных маркеров действует как программируемое контрольное слово. Gisting представляет метод, который использует настройку префиксных слов для сжатия слов подсказки, специфичных для задачи, в краткий набор токенов gist. Учитывая, что подсказки для конкретной задачи будут различаться от задачи к задаче, настройка префиксного слова будет использоваться индивидуально для каждой задачи. Для повышения эффективности Gisting дополнительно представляет метод метаобучения для прогнозирования новых невидимых токенов gist на основе токенов gist в предыдущих задачах.
Другие методы выполняют онлайн-сжатие каждого нового входного слова подсказки. Например, AutoCompressors обучает предварительно обученную языковую модель сжатию слов-подсказок в сводные векторы посредством обучения без учителя. ICAE обучает автокодировщик сжимать необработанный контекст в короткие слоты памяти. В частности, ICAE использует большую модель, адаптированную к LoRA, в качестве кодера, а целевую большую модель — в качестве декодера. Добавьте набор жетонов памяти и закодируйте их в слот памяти перед вводом токена.
4.1.4 Поисковая расширенная генерация (RAG)
Расширенный поиск Generation, RAG) направлен на повышение качества ответов на большие Модели за счет интеграции внешних источников знаний. RAG также можно рассматривать как метод повышения эффективности вывода при обработке больших объемов данных. RAG не объединяет всю информацию в одну слишком длинную подсказку,Вместо этого полученная соответствующая информация добавляется в исходное приглашение.,Это гарантирует, что Модель получит необходимую информацию, при этом значительно уменьшив длину слов подсказки. FLARE использует предсказания предстоящих предложений, чтобы заранее решить, когда и какую информацию получить. REPLUG рассматривает большую Модель как черный ящик.,И расширьте его с помощью настраиваемого поиска Модель. Он добавляет полученные документы на вход замороженного черного ящика. Большая модель.,И далее используйте большую Модель для контроля поиска Модели. Self-RAG повышает качество и достоверность результатов поиска за счет самоанализа. Он вводит токен обратной связи,Сделайте большую Модель управляемой на этапе рассуждения.
4.2 Организация вывода
Процесс вывода традиционных больших моделей генерируется полностью последовательно, что приводит к большим затратам времени. Методы организации вывода направлены на (частичное) распараллеливание производства путем организации структуры выходного контента.
Скелет мысли (SoT) является пионером в этом направлении. Основная идея SoT — использовать новые возможности больших моделей для планирования структуры выходного контента. В частности, SoT состоит из двух основных этапов. На первом этапе (т. е. этапе формирования) SoT направляет большую модель для создания краткой структуры ответа с использованием заранее определенных «слов-подсказок для рамки». Например, если задать такой вопрос, как «Какие типичные виды китайских блюд?», результатом этого этапа будет список блюд (например, лапша, горячее, рис) без подробных описаний. Затем, на втором этапе (то есть этапе расширения точек), SoT направляет большую модель на использование «подсказки расширения точек» для одновременного расширения каждой точки в скелете, а затем соединяет эти расширения для формирования окончательного ответа. При применении к моделям с открытым исходным кодом его можно масштабировать с помощью точек выполнения пакетного вывода, что может улучшить использование оборудования и сократить общую задержку сборки при использовании тех же вычислительных ресурсов для сокращения дополнительных вычислений. Процесс рассуждения SoT показан на рисунке 6:
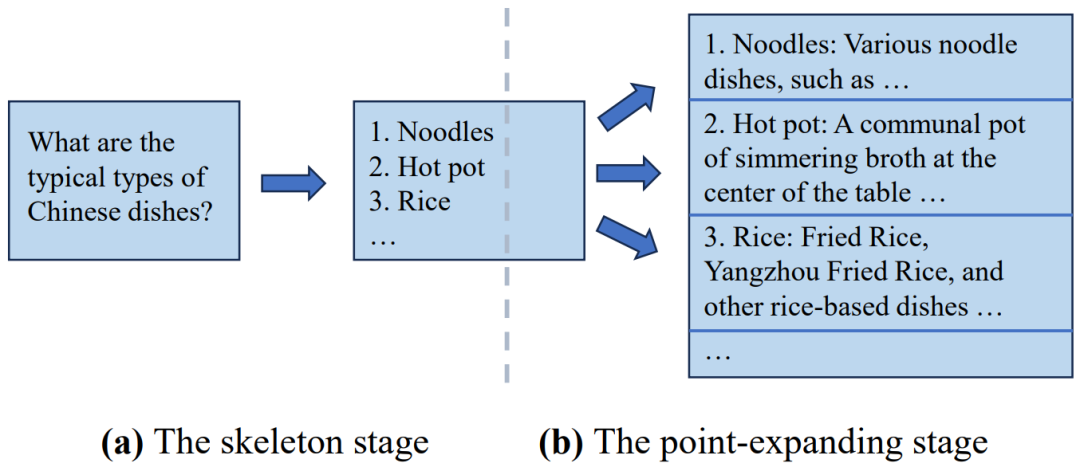
Накладные расходы, вызванные дополнительными словами подсказки (такими как слова подсказки скелета и слова подсказки расширения точки).,SoT обсудил возможность совместного использования KV-кэшей общих префиксов ключевых слов между несколькими узлами на этапе расширения узла. также,SoT использует Модель маршрутизации, чтобы решить, подходит ли SoT для решения конкретной проблемы.,Цель состоит в том, чтобы ограничить его использование соответствующими ситуациями. результат,SoT добился ускорения вывода в 2,39 раза на недавно выпущенной модели 12 больших моделей.,И улучшите качество ответов, увеличив разнообразие и актуальность ответов.
SGD еще больше расширяет идею SoT,Он организует подпроблемные точки в ориентированный ациклический граф (DAG).,И отвечайте на логически независимые подвопросы параллельно в течение раунда. Похоже на: Со Т,SGD также использует новые возможности Big Model.,Создайте структуру вывода, предоставив несколько примеров слов-подсказок, которые вы сами придумали. SGD ослабляет строгое предположение о независимости между различными точками.,улучшить качество ответов,Особенно по вопросам математики и кодирования. Сравнимо с SoT-сравнением,SGD отдает приоритет качеству ответа, а не скорости. также,SGD представляет метод адаптивного выбора модели,назначить оптимальный размер Модели для каждой подзадачи на основе ее предполагаемой сложности,тем самым еще больше повышая эффективность.
APAR использует идею, аналогичную SoT, используя большие модели для вывода специальных управляющих токенов (таких как , [fork]) для автоматического и динамического запуска параллельного декодирования. Чтобы эффективно использовать распараллеливаемую структуру, присущую выходному содержимому, и точно генерировать токены управления, APAR настраивает большие модели, которые выполняются на тщательно разработанных данных, сформированных в определенной древовидной структуре. В результате APAR достигает среднего ускорения от 1,4 до 2,0 раз по всем тестам с незначительным влиянием на качество ответа. Более того, APAR сравнивает свой метод декодирования с умозрительным. Сочетание технологии декодирования (например, Medusa) и структуры рассуждения (например, vLLM),Для дальнейшего улучшения задержки вывода и системы Пропускная способность。
SGLang в Python Примитивы функций представляют предметно-ориентированный язык (DSL), который гибко упрощает крупномасштабное программирование. Основная идея SGLang — автоматически анализировать зависимости между различными вызовами генерации и на этой основе выполнять пакетный вывод и совместное использование KV-кеша. Используя этот язык, пользователи могут легко реализовать различные стратегии подсказок и воспользоваться преимуществами автоматической оптимизации эффективности SGLang (например, SoT, ToT). Кроме того, SGLang также представляет и сочетает в себе несколько методов компиляции на системном уровне.,Например, перемещение кода и предварительная выборка комментариев.
4.3 Выводы, рекомендации и будущие направления
Растет потребность в больших моделях для обработки более длинных входных данных и генерации более длинных выходных данных.,Это подчеркивает важность технологии оптимизации на уровне данных. среди этих технологий,Основная цель метода сжатия входных данных — повысить эффективность этапа предварительного заполнения за счет снижения вычислительных затрат, вызванных операциями внимания. также,Для большой модели на основе API,Эти методы могут снизить затраты на API, связанные с входными токенами. На этапе С выравнивать,Метод организации вывода направлен на улучшение этапа декодирования за счет снижения существенных затрат на доступ к Память, связанных с методами авторегрессионного декодирования.
Поскольку большие модели становятся более мощными, их можно будет использовать для сжатия входных подсказок или структурирования выходного содержимого. Недавние достижения в методах организации вывода также продемонстрировали эффективность использования больших моделей для организации выходного контента в независимые точки или графики зависимостей, тем самым облегчая пакетный вывод для уменьшения задержки генерации. Эти методы используют присущую параллелизуемую структуру выходного контента, позволяя большим моделям выполнять параллельное декодирование, тем самым улучшая использование оборудования и, таким образом, уменьшая задержку сквозной генерации.
В последнее время различные конвейеры подсказок (например, ToT , GoT)и Появляется агентская структура. Хотя эти нововведения расширяют возможности больших моделей, они также увеличивают длину ввода, что приводит к увеличению вычислительных затрат. Для решения этой проблемы многообещающим решением является применение методов сжатия входных данных для уменьшения их длины. В то же время эти конвейерные структуры естественным образом привносят больше параллелизма в структуру вывода, увеличивая параллельное декодирование и распределяя KV по разным потокам декодирования. cacheиз可能性。SGLang支持灵活избольшой Модельпрограммирование,И предоставляет возможности для оптимизации внешнего и внутреннего взаимодействия.,Это закладывает основу для дальнейшего расширения и совершенствования в этой области. Суммируя,Оптимизация уровня данных,Включает методы сжатия ввода и организации вывода.,в обозримом будущем,Чтобы повысить эффективность рассуждений больших моделей,станет все более необходимым.
В дополнение к эффективности рассуждений существующих структур,Некоторые исследования также направлены на непосредственное проектирование более эффективных структур агентов. Например,FrugalGPT предлагает каскад моделей, состоящий из больших моделей разных размеров.,Если Модель достигает достаточного уровня уверенности в ответе,Тогда процесс рассуждения прекратится раньше времени。该методпроходитьиспользовать分层из Модель Архитектураина основе Модель置信度估计из智能рассуждение终止来提高效率。и Модель级别издинамическое рассуждение Технология (раздел 5.2.5) По сравнению с С выравниванием, FrugalGPT реализован на уровне конвейера динамическое рассуждение。
5 Оптимизация уровня модели
Оптимизация больших моделей эффективных рассуждений уровня Модели в основном фокусируются на оптимизации структуры модели или представления данных. Оптимизация структуры модели включает в себя непосредственно разработку эффективной структуры модели и изменение исходной модели для корректировки структуры времени рассуждения. С точки зрения оптимизации представления данных обычно используется Модель Количественная. оценка Технологии.
В этом разделе мы классифицируем методы оптимизации на уровне модели в соответствии с необходимыми дополнительными затратами на обучение. Первая категория включает в себя разработку более эффективных структур моделей (также называемую эффективным структурным проектированием). Модели, разработанные с использованием этого подхода, часто необходимо обучать с нуля. Вторая категория фокусируется на сжатии предварительно обученных моделей (так называемое сжатие модели). Модели сжатия в этой категории обычно требуют лишь минимальной тонкой настройки для восстановления своей производительности.
5.1 Эффективное структурное проектирование
в настоящий момент,Большая модель SOTA обычно использует архитектуру Transformer.,Как описано в разделе 2.1. Однако,Ключевые компоненты большой модели на базе трансформатора,Включает сеть прямой связи (FFN) и операции внимания.,в процессе рассуждения Есть проблема с эффективностью。文章认为原因нравиться下:
- FFN вносит большую часть параметров модели в большую модель на основе трансформатора.,Это приводит к значительным затратам на доступ к Память и использованию Память.,Особенно на этапе декодирования. Например,Модуль FFN занимает 63,01% в LLaMA-7BМодель,Составляет 71,69% в LLaMA-70BМодель.
- Сложность операции внимания квадратична от входной длины.,Это приводит к значительным вычислительным затратам.,Особенно при работе с более длинными контекстами ввода.
Чтобы решить эти проблемы эффективности вычислений, некоторые исследования были сосредоточены на разработке более эффективных структур Модели. В статье соответствующие исследования разделены на три группы (как показано на рисунке 7): Эффективная конструкция FFN, эффективный дизайн внимания и Альтернатива трансформатору。
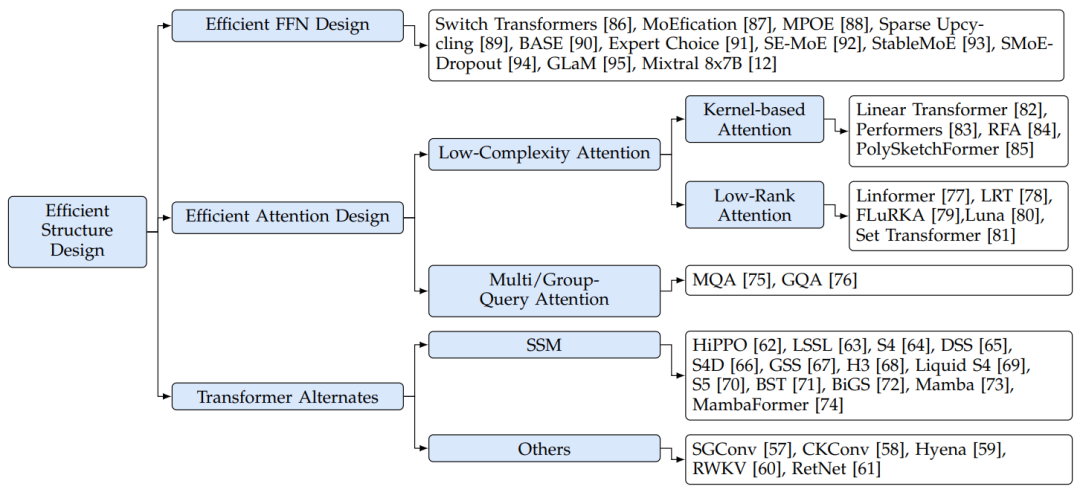
Рисунок 7. Классификация эффективного структурного проектирования больших моделей.
5.1.1 Эффективная конструкция FFN
В этом отношении многие исследования были сосредоточены на интеграции методов смешанных экспертов (MoE) в большие модели для повышения производительности больших моделей при сохранении вычислительных затрат. Основная идея MoE заключается в динамическом распределении различных бюджетов при работе с разными входными токенами. В трансформаторах на базе МЭ несколько параллельных сетей прямого аудита (FFN), то есть экспертов, используются вместе с обучаемыми модулями маршрутизации. Во время вывода модель выборочно активирует конкретных экспертов для каждого токена, контролируемого модулем маршрутизации.
Некоторые исследования сосредоточены на работе экспертов FFN, в основном оптимизируя процесс получения экспертных весов или делая экспертов более легкими для повышения эффективности. Например, компания MoEfication разработала метод преобразования больших моделей, не относящихся к MoE, в версии MoE с использованием предварительно обученных весов. Такой подход устраняет необходимость дорогостоящего предварительного обучения моделей МО. Чтобы реализовать эту технологию, MoEfication сначала разделила FFN-нейроны предварительно обученной большой модели на несколько групп. Внутри каждой группы нейроны обычно активируются функциями активации одновременно. Затем он реорганизует каждую группу нейронов в качестве эксперта. Редкий Upcycling представляет метод инициализации весов LLM на основе MoE непосредственно из контрольной точки плотной модели. При таком подходе эксперты LLM на базе Министерства образования являются точными копиями FFN в плотной модели. Используя эту простую инициализацию, Sparse Апсайклинг может эффективно обучать модели МО достижению высокой производительности. MPOE предложил использовать оператор матричного произведения (Matrix Product Operators, MPO)分解来减少на основеMoEизбольшой Модельиз参数。Этот метод будетFFNиз每个масса矩阵分解为一个包含公共信息из全局共享открыть量и一组捕获特定特征из局部辅助открыть量。
Другое исследование посвящено совершенствованию конструкции модулей (или стратегий) маршрутизации в моделях МО. В предыдущей модели MoE модуль маршрутизации был склонен к проблемам с дисбалансом нагрузки, что означало, что некоторым экспертам назначалось большое количество токенов, в то время как другие эксперты обрабатывали лишь небольшое количество токенов. Этот дисбаланс не только растрачивает недостаточно используемые экспертные возможности и ухудшает производительность модели, но также ухудшает качество логических выводов. Текущие реализации Министерства образования часто используют пакетное матричное умножение для одновременного вычисления всех экспертов FFN. Для этого необходимо, чтобы входная матрица каждого эксперта имела одинаковую форму. Однако из-за проблемы дисбаланса нагрузки входной набор токенов необходимо заполнить для тех недостаточно используемых экспертов, чтобы удовлетворить ограничениям формы, что приводит к непроизводительным затратам вычислений. Таким образом, основная цель разработки модуля маршрутизации — добиться лучшего баланса в распределении токенов среди экспертов МЧС. Выключатель Трансформаторы вносят дополнительные потери, а именно потери балансировки нагрузки, в конечную функцию потерь, чтобы наказать несбалансированное распределение модуля маршрутизации. Эта потеря выражается как масштабированное скалярное произведение дробного вектора распределения токенов и вектора равномерного распределения. Следовательно, потери минимизируются только тогда, когда распределение токенов сбалансировано между всеми экспертами. Такой подход побуждает модуль маршрутизации равномерно распределять токены между экспертами, облегчая балансировку нагрузки и, в конечном итоге, улучшая производительность и эффективность модели. BASE изучает встраивание каждого эксперта сквозным способом, а затем назначает экспертам токены на основе сходства встраивания. Чтобы обеспечить балансировку нагрузки, BASE формулирует задачу линейного распределения и использует алгоритм аукциона для эффективного решения этой проблемы. Эксперт Choice представляет простую, но эффективную стратегию, обеспечивающую идеальную балансировку нагрузки моделей на основе MoE. В отличие от предыдущих методов назначения экспертов на токены, Expert Выбор позволяет каждому эксперту самостоятельно выбирать топ-k токенов на основе встроенного сходства. Такой подход гарантирует, что каждый эксперт обрабатывает фиксированное количество токенов, хотя каждый токен может быть назначен разному количеству экспертов.
Помимо вышеупомянутых исследований, посвященных самой архитектуре модели, ведется также соответствующая работа по совершенствованию методов обучения моделей на основе Министерства образования. SE-MoE вводит новую вспомогательную потерю, называемую маршрутизатором. z-loss, цель которого — повысить стабильность обучения модели без ущерба для производительности. SE-MoE обнаружило, что в модуле маршрутизации экспоненциальная функция, введенная операцией softmax, усугубляет ошибку округления и приводит к нестабильному обучению. Чтобы решить эту проблему, маршрутизатор Z-потери наказывают большие вероятности ввода в экспоненциальную функцию, тем самым сводя к минимуму ошибку округления во время обучения. StableMoE отметил, что большая Модель, основанная на MoE, имеет проблему колебаний маршрутизации, то есть распределение экспертов непоследовательно на этапах обучения и вывода. Один и тот же входной токен при обучении назначается разным экспертам, но при выводе активируется только один эксперт. Чтобы решить эту проблему, StableMoE предлагает более последовательный подход к обучению. Сначала он изучает политику маршрутизации, а затем сохраняет фиксированную политику маршрутизации на этапе обучения и вывода модели. SMoE-Dropout разрабатывает метод обучения для большой Модели на основе MoE, который предлагает постепенно увеличивать количество активированных экспертов в процессе обучения. Этот подход улучшает масштабируемость вывода Модели на основе MoE и последующей тонкой настройки. GLaM предварительно обучил и выпустил серию Моделей с разными размерами параметров, которые продемонстрировали свою производительность, сравнимую с плотной большой Моделью, на задачах с несколькими выстрелами. В этой серии Моделей самая большая Модель имеет параметры до 1,2 триллиона. Микстрал 8x7B — недавно выпущенная привлекательная модель с открытым исходным кодом. Во время вывода он использует только 13 миллиардов активных параметров и обеспечивает лучшую производительность, чем модель LLaMA-2-70B в различных тестах. Микстрал Каждый уровень 8x7B состоит из 8 экспертов сети прямой связи (FFN), и каждый токен назначается двум экспертам в процессе вывода.
5.1.2 Эффективный дизайн внимания
Операция внимания является ключевой частью архитектуры Transformer. Однако,Его вычислительная сложность квадратично связана с входной длиной.,Это приводит к значительным вычислительным затратам, затратам на доступ и использование,Особенно при работе с длинными контекстами. Чтобы решить эту проблему,Исследователи изучают более эффективные способы приблизить функциональность первоначальной операции внимания. Эти исследования можно условно разделить на две основные ветви: внимание с несколькими запросами и внимание низкой сложности.
①Multi-Query Attention。Multi-Query Внимание (MQA) оптимизирует внимание, разделяя кэш KV между разными головками внимания. действовать. Эта стратегия эффективно снижает стоимость доступа и использования Память во время вывода, а также помогает повысить производительность модели Transformer. Как упоминалось в разделе 2.2, большая модель трансформаторного типа обычно использует работу с несколькими головками (MHA). Эта операция требует сохранения и извлечения пар KV для каждой головки внимания на этапе декодирования, что приводит к значительному увеличению стоимости доступа и использования. MQA решает эту проблему, используя одну и ту же пару KV на разных головках, сохраняя при этом разные значения добротности. Благодаря обширному тестированию было доказано, что MQA значительно снижает требования к Памяти с небольшим влиянием на производительность Модели, что делает его ключевой технологией для повышения эффективности вывода. Групповой запрос attention(GQA)дальнейшее расширениеMQAиз概念,Его можно рассматривать как гибрид MHAиMQA. Конкретно,GQA делит головы внимания на разные группы,Затем сохраните набор значений КВ для каждой группы. Этот метод не только сохраняет преимущества MQA в сокращении накладных расходов на Память.,Это также усиливает баланс между скоростью вывода и качеством вывода.
②Low-Complexity Attention。Low-Complexity Attentionметод旨существовать设计新из机制来降低每个注意力头из计算复杂度。Чтобы упростить обсуждение,Здесь предполагается, что размеры матриц Q (запрос), K (ключ) и V (значение) одинаковы.,Прямо сейчас
. Поскольку следующая работа не предполагает изменение количества голов внимания, таких как MQA, обсуждение здесь сосредоточено на механизме внимания внутри каждой головы. Как упоминалось в разделе 2.2, вычислительная сложность традиционного механизма внимания составляет
, что эквивалентно квадратичному росту по мере увеличения входной длины. Чтобы решить проблему низкой эффективности, используется ядро AttentionиLow-Rank Был предложен метод Attention, который сводит сложность к
。
- Kernel-based Attention。на основе核из注意力设计了一个核
, путем преобразования линейного скалярного произведения между картами объектов, например,
, чтобы приблизить
нелинейная операция softmax. Он рассчитывается путем расстановки приоритетов
, а затем объединить его с
умноженный на
Связанные традиционные квадратичные вычисления. В частности, входная матрица QиK сначала передается через функцию ядра
отображается в пространстве ядра,Но сохраните первоначальные размеры. Затем используйте корреляционные свойства матричного умножения,Разрешите умножить KиV, прежде чем взаимодействовать с Q. Поэтому механизм внимания переформулируется как:
в,
. Этот метод эффективно снижает вычислительную сложность до
, что делает его линейно связанным с входной длиной. Linear Transformer — первая работа, предлагающая внимание на основе ядра. он использует
Как функция ядра, в
Представляет экспоненциальную линейную функцию активации единицы. PerformersиRFA предлагает использовать карты случайных признаков, чтобы лучше аппроксимировать функцию softmax. PolySketchFormer использует полиномиальную функцию и технологию создания эскизов для аппроксимации функции softmax.
- Low-Rank Attention。 Low-Rank Технология Attention преобразует размерность токена матрицы KиV (например,
) сжимается до меньшей фиксированной длины (т.е. если
). Этот метод основан на
Признание того, что матрицы внимания часто обладают свойствами низкого ранга.,Сделать возможным сжатие его в измерении токена. Основное внимание в этом направлении исследований уделяется разработке эффективных методов сжатия.,в
Это может быть матрица контекста или матрица KиV:
Один из методов — использовать линейную проекцию для сжатия размера токена. Это делается путем объединения матрицы KиV с матрицей отображения
Делается путем умножения. Таким образом, вычислительная сложность расчета внимания сводится к
,Линейно входной длине. Линформер впервые заметил и проанализировал низкоранговую природу внимания.,Предлагается структура внимания низкого ранга. LRT предлагает применить низкоранговую трансформацию к модулю внимания и FFN одновременно,для дальнейшего повышения эффективности вычислений. FLURKA включает преобразование низкого ранга и кернеризацию в матрицу внимания.,Эффективность еще больше повышается. Конкретно,Сначала уменьшается размерность токена матрицы KиV.,Затем примените функцию ядра к матрице Qи низкого ранга K. Помимо линейного отображения, также были предложены другие методы сжатия размеров токенов. Лунаи Сет Transformer уделяет дополнительное внимание вычислению небольших запросов для эффективного сжатия матрицы KV. Luna использует дополнительную фиксированную длину, поскольку
матрица запроса. Небольшой запрос использует исходную контекстную матрицу для выполнения вычислений внимания, называемых пакетным вниманием, для сжатия контекстной матрицы до размера
. Впоследствии регулярные вычисления внимания, называемые распаковкой Внимание, применяет вычисления внимания к исходной матрице Q и сжатой матрице K и V. Дополнительные матрицы запроса могут быть обучаемыми параметрами или получены из предыдущего уровня. Набор Transformer представляет фиксированную длину
Вектор,Были разработаны аналогичные методы. FunnelTransformer отличается от предыдущего сжатия KиV Работа,Он использует операции объединения для постепенного сжатия длины последовательности матрицы Q.
5.1.3 Замена трансформатора
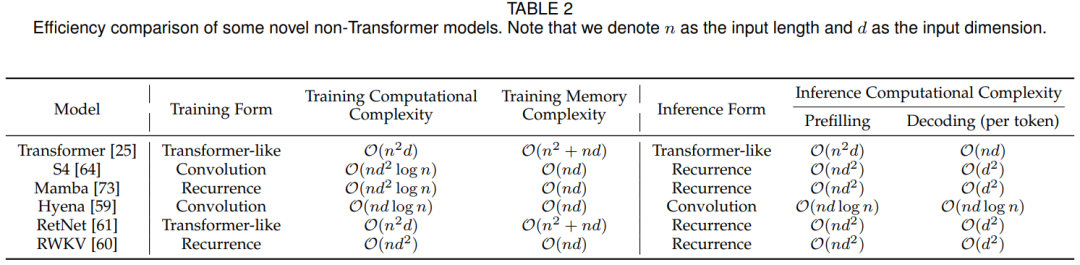
Помимо сосредоточения внимания на оптимизации операций внимания,Недавние исследования также позволили разработать новаторские эффективные и действенные архитектуры моделирования последовательностей. В таблице 2 С сравнение сравниваются некоторые типичные нетрансформаторные архитектуры. Модель производительности во время обучения и вывода.,Модели этих архитектур демонстрируют меньшую, чем квадратичную вычислительную сложность с точки зрения длины последовательности.,Позволяет большой модели значительно увеличить длину контекста.
Сравнение производительности типичных моделей архитектуры без трансформатора
Среди этих исследований можно выделить два выдающихся направления исследований, привлекших большое внимание. на. В одном из исследований основное внимание уделяется модели пространства состояний (State Space Model, SSM), эта модель рассматривает моделирование последовательностей как рекурсивное преобразование, основанное на теории HiPPO. Кроме того, другие исследования в основном сосредоточены на использовании длинных сверток или разработке формул, похожих на внимание, для моделирования последовательностей.
State Space Model:государственное пространство Модель(SSM)в некоторыхNLPиCV任务中из建模能力极具竞争力。ина основе注意力изTransformerВзаимно Сравнивать,SSM демонстрирует линейную сложность вычислений и хранения в зависимости от длины входной последовательности.,Это улучшает его способность обрабатывать длинные контекстные последовательности. В этом обзоре,SSM относится к серии архитектур моделей, которые удовлетворяют следующим двум свойствам:
(1) Они моделируют последовательность на основе следующей формулы, предложенной HiPPOиLSSL:
в,
представляет собой матрицу передачи.
является промежуточным состоянием,
это входная последовательность.
(2) Они разработали матрицу переноса A на основе теории HiPPO. В частности, HiPPO предлагает сжимать входную последовательность в последовательность коэффициентов, отображая ее в набор полиномиальных оснований (т.е.
)。
На основе вышеизложенной структуры,Некоторые исследования в основном сосредоточены на улучшении параметризации или инициализации матрицы передачи A. Это включает в себя переопределение того, как матрица формулируется или инициализируется в SSM.,Чтобы повысить эффективность решения задач моделирования последовательностей и производительности, LSSL впервые предложила оптимальную матрицу переноса, разработанную с помощью HiPPO.
Инициализируйте А. Кроме того, LSSL также обучает SSM сверточным способом, расширяя формулу (7). В частности, определив ядро свертки как
, формулу (7) можно переписать в виде
,Его также можно эффективно рассчитать с помощью быстрого преобразования Фурье (БПФ). Однако,Вычисление этого ядра свертки стоит дорого.,Потому что для этого требуется несколько раз A. с этой целью,S4, DSSиS4D предлагает диагонализировать матрицу A,Это ускоряет расчеты. Это можно рассматривать как метод параметризации матрицы преобразования A. Предыдущие SSM обрабатывали каждое входное измерение независимо.,Это приводит к большому количеству обучаемых параметров. с целью повышения эффективности,S5 предлагает использовать набор параметров для одновременной обработки всех входных измерений. На основе этой структуры,S5 представляет метод параметризации и инициализации A на основе стандартной матрицы HiPPO. Liquid S4иMamba параметризует матрицу перехода в зависимости от входных данных.,Это еще больше расширяет возможности моделирования SSM. также,S5 и Mamba используют технологию параллельного сканирования.,Операция свертки не требуется Прямой сейчас可进行有效из Модельтренироваться。这种технологиясуществовать现代GPU硬件上извыполнитьи Преимущества в развертывании。
Другим типом направления исследований является разработка лучшей архитектуры модели на основе SSM. GSS и BiGS сочетают в себе блок Gated Attention Unit (GAU) и SSM. Они заменяют операции внимания в ГАУ операциями ССМ. BST объединяет модель SSM с предлагаемым блоком, используя сильную предвзятость локального измерения. Трансформатор комбинированный. H3 отмечает, что SSM плохо запоминает старые токены в последовательностях С сравнивать. С этой целью рекомендуется добавить операцию сдвига SSM перед стандартной операцией SSM, чтобы напрямую перевести входной токен в состояние. MambaFormer объединяет стандартный Transformer и модель SSM, заменяя слой FFN в Transformer слоем SSM. Jamba представляет еще один способ объединения Transformer и SSM Model путем добавления четырех слоев Transformer в SSM Model. DenseMamba исследует проблему скрытой деградации состояния в традиционном SSM и вводит плотные соединения в архитектуру SSM для сохранения детализированной информации на более глубоких уровнях Модели. Блэк Мамбаи МО- мамба предложила использовать смесь экспертов, Технология MoE) улучшает модель SSM, сохраняя при этом производительность модели при оптимизации обучения и эффективности вывода.
Другие замены:КромеSSMснаружи,Существует несколько других эффективных альтернатив, которые также привлекают большое внимание.,Включая длинную свертку и рекурсивные операции, подобные вниманию. В некоторых исследованиях длинные свертки использовались при моделировании длинных последовательностей. Эти работы в основном касаются параметризации параметров свертки. Например,Hyena применяет параметрический подход, зависящий от данных,Для длинных сверток используются мелкие нейронные сети прямого распространения (FFN). Другие операции по проектированию,Но его можно включить в исследования кругового подхода.,Это обеспечивает эффективное обучение и эффективное рассуждение. Например,РВКВ построен на базе АФТ.,AFT предлагает заменить операцию внимания в Модели Трансформатора на следующую формулу:
в,
иTransformerТакой же , соответственно запрос, ключ, значение,
это обучаемое попарное смещение позиции
является нелинейной функцией. В частности, он дополнительно перепараметризирует отклонение положения,
,Таким образом, уравнение (8) можно переписать в рекурсивную форму. так,RWKV может сочетать эффективные функции параллельного обучения Transformer и эффективные возможности рассуждения RNN.
Анализ эффекта:Статья в таблице2средний анализи Сравниватьсравнивать了几种创新изи具有代表性из非Transformer架构из Модельиз计算и Памятьсложность。существоватьтренироваться时间方面,много Модель(нравитьсяS4, Hyena, RetNet) Они поддерживают параллелизм обучения, используя такие формы обучения, как свертки или внимание. Стоит отметить, что Mamba использует технологию параллельного сканирования для обработки входной последовательности, тем самым также используя обучающий параллелизм.
с другой стороны,в процессе рассуждения,В большинстве исследований выбирают циклическую архитектуру для поддержания линейной сложности вычислений на этапе предварительного заполнения и сохранения независимости длины контекста на этапе декодирования. и,На этапе декодирования,Эти новые архитектуры устраняют необходимость в кэшировании и загрузке функций исторических токенов (аналогично кэшу KV в модели языка на основе Transformer).,Это существенно экономит затраты на доступ к Память.
5.2 Сжатие модели
Сжатие Модели включают в себя ряд представлений данных, предназначенных для предварительного обучения путем изменения Модели (например, Количественная оценку) или изменить архитектуру модели (например, разрежение, оптимизация структуры). рассуждение) для повышения эффективности рассуждений, как показано на рисунке 8.
Рисунок 8. Классификация методов сжатия моделей для больших моделей.
5.2.1 Количественная оценка
Количественная Оценка — это широко используемый метод снижения вычислительных затрат больших Модель и Память путем преобразования весов и активаций Модели из представления с высокой разрядностью в представление с низкой разрядностью. В частности, многие методы включают преобразование тензоров FP16 Количественная Оценка представляет собой низкоразрядный целочисленный тензор, который можно выразить следующей формулой:
в
Представляет 16-битное значение с плавающей запятой (FP16),
Представляет целочисленное значение низкой точности.
представляет количество цифр,
и
Представляет коэффициент масштабирования и нулевую точку.
Далее статья начинается с анализа эффективности, чтобы проиллюстрировать, как методы квантования могут уменьшить задержку сквозного вывода для больших моделей. Позже будут подробно представлены два различных количественных рабочих процесса: Quantization (PTQ)иQuantization-Aware Training (QAT)。
анализ эффективности:нравиться2.2описано в разделе,Процесс рассуждения большой Модели состоит из двух этапов: этапа предварительного заполнения и этапа декодирования. На этапе предварительного заполнения,Большая модель обычно обрабатывает длинные последовательности токенов.,Основная операция — общее матричное умножение (GEMM). Задержка фазы предварительного заполнения в основном ограничивается вычислительными операциями, выполняемыми высокоточным ядром CUDA. Чтобы решить эту проблему,现有из研究методверномассаиактивация Количественная возможность использования низкоточных тензорных ядер для ускорения вычислений. Как показано на рисунке 9. Как показано на (b), квантование активации выполняется онлайн перед каждой операцией GEMM, что позволяет использовать для вычислений ядра тензора низкой точности (такие как INT8). Этот метод квантования называется квантованием активации веса.
。
Напротив, на этапе декодирования большие модели обрабатывают только один токен за шаг генерации, используя общее умножение матрицы-вектора (GEMV) в качестве основной операции. На задержку на этапе декодирования в основном влияет загрузка тензоров большого веса. Чтобы решить эту проблему, существующие методы сосредоточены только на квантованных весах для ускорения доступа к памяти. Этот метод называется
, сначала квантовать веса в автономном режиме, а затем деквантовать веса низкой точности в формат FP16 для расчета, как показано на рисунке 9 (a).
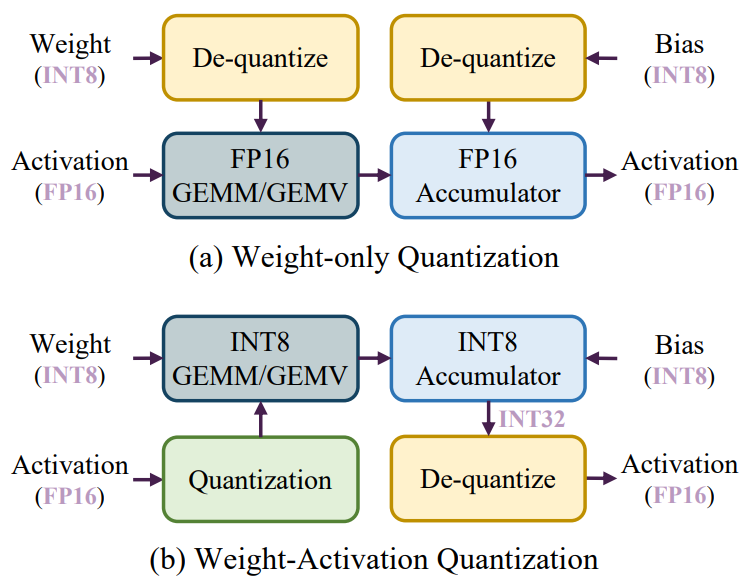
Рисунок 9: (a) Процесс рассуждения о количественном определении чистого веса. (б) Процесс количественного рассуждения активации веса.
Post-Training Quantization: PTQ предполагает проведение Количественной предварительной подготовки Модель повышение квалификации без необходимости переобучения, которое может оказаться дорогостоящим процессом. Хотя метод PTQ был хорошо изучен в меньшей Модели, добавление существующей Количественной Существуют трудности с непосредственным применением технологии оценки к большим моделям. Это происходит главным образом потому, что веса и активации больших Моделей обычно демонстрируют больше выбросов и имеют более широкий диапазон распределения, чем меньшие, что делает их Количественную оценка является более сложной задачей. Короче говоря, сложный характер большой Модели, характеризующийся ее размером и сложностью, требует специализированных методов для эффективного управления Количественной моделью. процесс оценки. Наличие выбросов и более широкий диапазон распределения в крупных Модель требует разработки индивидуальной Количественной модели. технология повышения качества, позволяющая обрабатывать эти уникальные характеристики, не влияя на производительность или эффективность модели.
Большое количество исследований было посвящено разработке эффективных алгоритмов квантования для сжатия больших моделей. В этой статье представлен синтез репрезентативных алгоритмов, классифицированных по четырем измерениям в таблице 3. Для типов квантованных тензоров некоторые исследования сосредоточены только на весовых показателях. квантование, в то время как многие другие исследования сосредоточены на весе и активации Количественная оценка. Стоит отметить, что в большой Модели кэш KV представляет собой уникальный компонент, влияющий на доступ к Памяти Память. Поэтому в некоторых исследованиях предлагается выполнять Количественную работу на КВ-кэше. оценка。существовать Количественная Что касается формата оценки, то для облегчения аппаратной реализации большинство алгоритмов используют унифицированный формат. О Количественной Для определения параметров (таких как коэффициенты масштабирования, нулевые точки) большинство исследований полагаются на статистику, полученную на основе весов или значений активации. Однако есть также некоторые исследования, которые рекомендуют находить оптимальные параметры на основе потерь при реконструкции. Кроме того, некоторые исследования также показывают, что в Количественной оценкадо или Количественная оценка Не обновляется в процессе Количественная Вес оценки (называемый
) для улучшения производительности.
только для веса Среди методов квантования GPTQ представляет собой раннюю и лучшую работу по квантованию больших моделей, основанную на традиционном алгоритме OBQ. OBQ достигает оптимального порядка квантования каждой строки весовых матриц, используя ошибку восстановления относительно матрицы Гессе неквантованных весов. После каждого шага квантования OBQ итеративно корректирует неквантованные веса, чтобы уменьшить ошибки реконструкции. Однако частые обновления матрицы Гессе во время процесса квантования увеличивают сложность вычислений. GPTQ упрощает этот процесс, принимая единый порядок слева направо для квантования каждой строки, что позволяет избежать необходимости обширных обновлений матрицы Гессе. Эта стратегия значительно снижает вычислительные требования, поскольку при квантовании строки вычисляется только матрица Гессе, а затем используются результаты вычислений для последующих строк, тем самым ускоряя весь процесс квантования. ЛУТ- GEMM предлагает новый метод с использованием справочных таблиц (Look-Up Table, LUT)из去Количественная метод оценки, предназначенный для уменьшения количества Количественной оценканакладные расходы, чтобы ускориться Количественная Процесс рассуждения о оценке модели. Кроме того, он использует метод, называемый бинарным кодированием Количественная. оценка(BCQ)из非均匀Количественная метод оценки, который содержит обучаемую Количественную интервал открытия. AWQ отмечает, что весовые каналы различаются по своей важности для производительности, при этом особое внимание уделяется тем каналам, которые совпадают с входными каналами, которые активируют выбросы. Чтобы улучшить сохранение ключевых весовых каналов, AWQ использует сложный метод параметризации. Этот метод выбирает коэффициенты повторной параметризации посредством поиска по сетке, что эффективно уменьшает ошибку реконструкции. OWQ заметил Количественная Оценка сложности с весами, связанными с активацией выбросов. Чтобы решить эту проблему, OWQ использует Количественную точность смешанной точности. стратегия оценки. Этот метод выявляет слабые столбцы в матрице весов и присваивает этим конкретным весам более высокую точность, сохраняя при этом более низкий уровень точности. рейтинг Оставшиеся веса. SpQR представляет метод в Количественной Процесс оценки идентифицирует и присваивает выбросам более высокие веса точности, в то время как остальные веса являются количественными. Кредит состоит из 3 цифр. SqueezeLLM предлагает хранить выбросы в разреженной матрице полной точности и применять неравномерную Количественную к оставшимся весам. оценка。в соответствии с Количественная оценка Определение чувствительности неоднородной Количественной Значение оценки может увеличить ценность Количественной Производительность модели оценки.QuIP представляет LDLQ, оптимальный адаптивный метод для квадратичных суррогатных целей. Исследования показывают, что обеспечение несогласованности между весами и матрицами Гессе может повысить эффективность LDLQ. QuIP использует LDLQ для достижения некогерентности посредством умножения случайных ортогональных матриц. FineQuant использует эвристический подход. Для определения каждого столбца Количественная детализация оценок в сочетании с эмпирическими данными, полученными в результате экспериментов по разработке Количественной схема оценки. Работа от QuantEase построена на основе GPTQ. Выполнение Количественной на каждом слое оценки, он предложил метод, основанный на спуске по координатам, для более точной компенсации недостающей Количественной Вес признания. Кроме того, QuantEase может использовать Количественную информацию из GPTQ. Веса оценок служат инициализацией и дальнейшим уточнением процесса компенсации. LLM-MQ защищает выбросы веса в формате FP16 и сохраняет их в формате сжатых разреженных строк (CSR) для повышения эффективности вычислений. Кроме того, LLM-MQ моделирует распределение разрядности каждого слоя как задачу целочисленного программирования и использует эффективный решатель для ее решения за секунды. LLM-MQ также разработала эффективное ядро CUDA для интеграции де-Количественной оператора оценки, тем самым снижая стоимость доступа к Память при расчетах.
Для активации веса квантования, ZeroQuant использует мелкозернистую Количественную определение веса и активации, использование ядерного синтеза для минимизации Количественной Память стоимость доступа в процессе оценки и выполнять дистилляцию знаний слой за слоем для восстановления производительности. FlexGen кэширует веса и напрямую Количественную. преобразовать в INT4, чтобы уменьшить занятость Память во время вывода больших объемов данных. ЛЛМ.int8() Было обнаружено, что выбросы в активации сконцентрированы в небольшом подмножестве каналов. Исходя из этого, LLM.int8() Разделите активацию и веса на две разные части на основе распределения выбросов внутри входного канала, чтобы минимизировать Количественную ценность активации. ошибка тарификации. Каналы, содержащие данные исключений значений активации и весов, хранятся в формате FP16, остальные каналы хранятся в формате INT8. SmoothQuant использует технику перепараметризации для решения Количественной задачи. Вызов значения активации. Этот метод вводит примерный коэффициент Сравнивать, который расширяет диапазон данных весового канала и уменьшает диапазон данных соответствующего канала активации. ZeroQuant представляет Количественную систему группового уровня Оценка Стратегия и активированный уровень токена Количественная метод оценки. На основе этого метода ZeroQuantV2 предлагает технологию LoRC (компенсация низкого ранга), использующую матрицу низкого ранга для облегчения проблемы Количественной компенсации. оценка Неточность. RPTQ обнаружил, что распределение различных активированных каналов на самом деле меняется, что дает Количественную качество приносит проблемы. Чтобы облегчить эту проблему, RPTQ реорганизует каналы с одинаковым распределением активации в кластеры и применяет Количественную независимо в каждом кластере. оценка. OliVe отмечает, что нормальные значения вблизи выбросов менее критичны. Таким образом, он объединяет каждый выброс с нормальным значением, жертвуя нормальным значением, чтобы получить более широкий диапазон представлений выбросов. OS+ отмечает, что распределение выбросов концентрированное и асимметричное, что является проблемой для больших моделей. Оценка представляет собой проблему. Чтобы решить эту проблему, OS+ представляет технологию перемещения и масштабирования на уровне канала. Определение параметров перемещения и масштабирования в процессе поиска позволяет эффективно обрабатывать концентрированные и асимметричные распределения выбросов. ZeroQuant-FP изучает веса и активации Количественная возможность уточнения формата FP4 и FP8. Исследования показывают, что сравнение С с целочисленными типами активирует Количественную Оценка для типов с плавающей запятой (FP4 и FP8) даст лучшие результаты. Всеведущий с предыдущими зависимостями Количественная Методы эмпирического расчета параметров оценки различны. Вместо этого он оптимизирует веса, обрезанные границы и эквивалентные коэффициенты масштабирования преобразования, чтобы минимизировать Количественную ценность. ошибка тарификации. QLLM устраняет пары выбросов путем реализации реорганизации каналов Количественная Влияние рейтинга. Кроме того, QLLM также разработал обучаемые параметры низкого ранга, чтобы уменьшить постквантованную Количественную ошибка тарификации. Atom использует смешанную точность и динамическую Количественную точность. Активированная стратегия. Примечательно, что этот подход расширяется и включает в себя Количественный кэш KV. Улучшение для INT4 для повышения пропускной способности. LLM-FP4 стремится преобразовать всю Модель Количественную Creature — это формат FP4, в котором реализована технология смещения индекса перед сменой. Этот метод сочетает в себе коэффициент примера Сравнивать значения активации с весом для решения проблемы количественности, вызванной выбросами. проблема с оценкой. BiLLM представляет собой один из самых низких показателей PTQ на сегодняшний день. BiLLM идентифицирует колоколообразное распределение весов и аномальное распределение «длинного хвоста» матрицы весов Гессе. На этом основании предлагается классифицировать весовую структуру на основе матрицы Гессе на значимые значения и незначимые значения и бинаризировать их соответственно. Таким образом, BiLLM может конвертировать большие модели в широкий спектр Количественных моделей. значение до 1,08, не уменьшая значительно недоумения. KVQuant предлагает Количественную кэш-память KV путем определения оптимальных типов данных в автономном режиме на калибровочном наборе. оценкаиз非均匀Количественная схема оценки. КИВИ предлагает 2бит, не требующий настройки Алгоритм квантования кэша KV, который использует одноканальное квантование для ключей. кеш, используя количественную оценку значения с помощью одного токена кэш. Ли и др. выполнили комплексную оценку влияния квантования на различные типы тензоров (включая KV). Кэш), различные задания, 11 разных больших МодельиSOTA Количественная Влияние метода оценки.
Quantization-Aware Training:QATсуществовать Модельтренироваться过程中考虑了Количественная Влияние рейтинга. Копировать путем интеграции Количественная уровень эффектов, QAT помогает весам адаптироваться Количественная ошибки, вызванные точностью, тем самым повышая производительность задачи. Однако обучение большой модели обычно требует большого количества обучающих данных и вычислительных ресурсов, что является потенциальным узким местом для реализации QAT. Поэтому текущие исследования «Работа» фокусируются на стратегиях снижения требований к обучающим данным или облегчения вычислительной нагрузки, связанной с реализацией QAT. Чтобы снизить требования к данным, LLM-QAT представляет подход без данных, который использует большой размер исходного FP16 для генерации обучающих данных. В частности, LLM-QAT использует каждый токен словаря в качестве стартового токена для генерации предложений. На основе сгенерированных данных обучения LLM- QAT применяет рабочий процесс на основе дистилляции для обучения квантованного LLM, чтобы он соответствовал выходному распределению исходной большой модели FP16. Норма Твик лишь ограничивает выбор стартовых тегов для тех языков, на которые приходится наибольшая доля в языковой категории. Эта стратегия может эффективно улучшить производительность генерации квантованных моделей для различных задач.
Чтобы уменьшить объем вычислений, во многих методах применяется точная настройка с эффективным использованием параметров. тюнинг, PEFT) стратегия ускорения QAT. QLoRA квантует веса больших моделей в 4 бита, а затем использует LoRA для каждой 4-битной матрицы весов в BF16 для точной настройки квантованной модели. QLoRA позволяет эффективно настраивать большие модели с 65B параметрами на графическом процессоре всего с 30 ГБ памяти. QALoRA предлагает добавить в QLoRA групповое квантование. Авторы отмечают, что количество параметров квантования в QLoRA значительно меньше количества параметров LoRA, что приводит к дисбалансу между квантованием и низкоранговой адаптацией. Они предположили, что операции на уровне группы могут решить эту проблему за счет увеличения количества параметров, предназначенных для количественной оценки. Кроме того, QA-LoRA может включать термины LoRA в соответствующую матрицу весов квантования. LoftQ отмечает, что инициализация матриц LoRA нулями в QLoRA неэффективна для последующих задач. В качестве альтернативы LoftQ предлагает использовать разложение по сингулярным значениям (разложение по сингулярным значениям) разрыва между исходными весами FP16 и квантованными весами. Value Разложение, SVD) для инициализации матрицы LoRA. LoftQ итеративно применяет Количественную разложение по сингулярным значениям для получения более точного приближения к исходным весам. Норма Твик предлагал обучить слой LayerNorm после квантования и использовать дистилляцию знаний для сопоставления выходного распределения квантованной модели с выходным распределением модели FP16, достигая эффекта, аналогичного LLM-QAT, избегая при этом более высоких затрат на обучение.
Эксперимент и анализ Сравнивать:本综述изавторвернодругой场景下изweight-only Эффект ускорения, создаваемый технологией квантования. Автор использовал LLaMA-2-7B и LLaMA-2-13B и взвешивал их с помощью AWQ Количественная разрядность до 4 бит. Автор использует NVIDIA A100 проводит эксперименты и развертывает Количественную с использованием двух фреймворков вывода TensorRT-LLMиLMDeploy. оценка后избольшой Модель。Затем,Авторы оценивают ускорение, достигнутое этими системами вывода на различных входных последовательностях.,Эти последовательности различаются по размеру пакета и длине контекста. Эффект ускорения задержки предварительного заполнения и задержки декодирования, сквозная задержка,Как показано в Таблице 4.
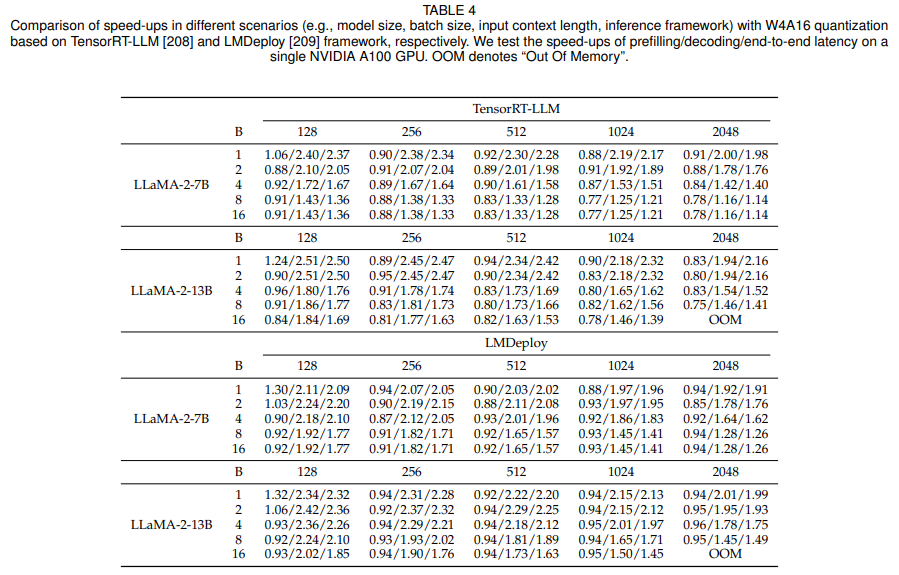
Таблица 4: Сравнение эффектов ускорения больших моделей
Результаты экспериментов показывают: (1) Только вес Квантование можно ускорить на этапе декодирования, тем самым достигая сквозного ускорения. Это улучшение в основном происходит за счет перехода от памяти с высокой пропускной способностью ( High Bandwidth Память (HBM) ускоряет загрузку квантованных моделей с весовыми тензорами низкой точности, этот подход значительно снижает накладные расходы на доступ к памяти. (2) На этапе предварительного наполнения измеряется только вес. Квантование может увеличить задержку. Это связано с тем, что узким местом на этапе предварительного заполнения являются вычислительные затраты, а не накладные расходы на доступ к памяти. Следовательно, только квантование весов без активации оказывает минимальное влияние на задержку. Кроме того, как показано на рисунке 9, только вес Квантование требует удаления весов низкой точности. приравнивается к FP16, что приводит к дополнительным вычислительным затратам и, таким образом, замедляет предварительное заполнение. (3) По мере увеличения размера партии и входной длины учитывается только вес. Ускорение квантования постепенно уменьшается. Это происходит главным образом потому, что для больших размеров пакетов и длины входных данных вычислительные затраты составляют задержку для более крупных случаев. Хотя только вес Квантование в основном снижает затраты на доступ к Память, но по мере увеличения размера пакета и длины входных данных вычислительные требования становятся более заметными, а его влияние на задержку становится менее значительным. (4) Поскольку стоимость доступа к Память связана с размером параметра Модели, учитывается только вес. Квантование обеспечивает большие преимущества для Модели с большими размерами параметров. По мере роста сложности и размера объекта неизбежно будет увеличиваться объем информации, необходимой для хранения и доступа к весам. Количественная оценка Модельмасса,weight-only Квантование может эффективно снизить занятость Памяти и накладные расходы на доступ к Память.
5.2.2 Разреженность
Разреженность — это метод сжатия,В структуры данных можно добавлять экземпляры Сравнивать элементов с нулевым значением (например, параметры модели или активации). Этот метод снижает сложность вычислений за счет эффективного игнорирования нулевых элементов во время вычислений. Применительно к большой модели,Разреженность обычно применяется к параметрам веса и активации внимания. Это привело к разработке стратегий снижения веса и механизмов разреженного внимания.
Весовая обрезка (Вес Pruning):权值修剪система地从Модель中去除不太关键из权值иструктура,Предназначен для снижения вычислительных затрат на этапе предварительного заполнения и этапе декодирования.,без существенного влияния на продуктивность. Этот метод разреживания делится на два основных типа: неструктурированная обрезка и структурированная обрезка. Их классификация основана на детализации процесса обрезки.,Как показано на рисунке 10.
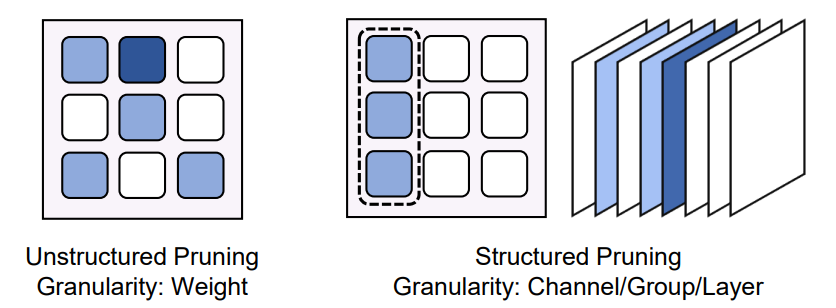
Рисунок 10: Неструктурированная обрезка и структурированная обрезка
Неструктурированная обрезка позволяет сократить отдельные значения веса с высокой степенью детализации. Используйте структурированную обрезку,Обычно он обеспечивает более высокую разреженность с минимальным влиянием на прогнозы Модели. Однако,Редкие узоры, полученные за счет неструктурированной обрезки, не имеют регулярности на высоком уровне.,Вызывает нерегулярный доступ к Память и шаблоны вычислений. Эта неравномерность может серьезно затруднить потенциал аппаратного ускорения.,Потому что современная вычислительная архитектура рассчитана на плотные, регулярные данные. поэтому,Несмотря на достижение более высоких уровней разреженности,Но реальные преимущества неструктурированного сокращения с точки зрения аппаратной эффективности и ускорения вычислений могут быть ограничены.
В центре внимания обрезки веса является критерий обрезки.,Включает важность веса и пример сравнения дифферента. Учитывая огромные размеры параметров большой модели,Повышение эффективности обрезки также имеет решающее значение. Одним из критериев сокращения является минимизация потерь при реконструкции Модели. SparseGPT — типичный метод в этой области. Это соответствует идее OBS,Рассмотрим влияние удаления каждого веса на потери при реконструкции сети. OBS итеративно определяет маску обрезки для сокращения весов.,и реконструировать необрезанные веса, чтобы компенсировать потери от обрезки. SparseGPT преодолевает узкое место эффективности OBS за счет оптимальной технологии частичного обновления.,设计了一种на основеOBS重构ошибкаиз自适应掩码选择технология。Prune and Tune улучшает SparseGPT за счет точной настройки большой модели с использованием минимальных шагов обучения во время сокращения. ISC разработал новый стандарт обрезки, сочетающий стандарты значимости OBS и OBD. Алгоритм дополнительно назначает экземпляры неравномерного сокращения Сравнивать каждому слою на основе информации Гессиана. BESA изучает дифференцируемую бинарную маску посредством градиентного спуска с потерями при реконструкции. Обрезка каждого слоя определяется поочередной минимизацией ошибки реконструкции. Еще один популярный критерий обрезки — размер. Ванда предложила использовать поэлементное произведение веса на норму входной активации в качестве критерия сокращения. RIA совместно учитывает вес и активацию, используя меру относительной важности и активации, которая оценивает важность каждого элемента веса на основе веса всех его связей. Кроме того, RIA преобразует неструктурированную разреженную парадигму в структурированную разреженную парадигму N:M, которую можно найти на NVIDIA. Получите настоящее ускорение на графическом процессоре. OWL фокусируется на определении коэффициента обрезки каждого слоя. Он назначает коэффициент сокращения каждому слою на основе коэффициента выбросов активации.
По сравнению с неструктурированным сокращением, структурированное сокращение работает с более грубой степенью детализации, удаляя более крупные структурные единицы в модели, такие как целые каналы или слои. Эти методы напрямую способствуют ускорению вывода на традиционных аппаратных платформах, поскольку они соответствуют плотным, регулярным парадигмам данных, для обработки которых оптимизированы эти системы. Однако более грубая степень детализации структурированного сокращения часто оказывает более выраженное влияние на производительность модели. Такие стандарты обрезки также предусматривают структурированную схему обрезки. LLM-Prune предлагает независимый от задачи структурированный алгоритм сокращения. В частности, он сначала идентифицирует структуры связи в больших моделях на основе зависимостей связей между нейронами. Затем он решает, какие структурные группы удалить, на основе хорошо продуманных показателей сокращения на уровне группы. После сокращения предлагается восстановить производительность модели с помощью университетской технологии обучения параметров, такой как LoRA. Sheared LLaMA предлагает сократить исходную большую модель до конкретной целевой архитектуры существующей предварительно обученной большой модели. Кроме того, он разрабатывает технологию динамической пакетной загрузки данных для улучшения производительности после обучения.
ZipLM итеративно идентифицирует и удаляет структурные компоненты.,Сделайте худший компромисс между потерями и временем работы. LoRAPrune предлагает структурированную структуру обрезки для предварительно обученных больших моделей с модулями LoRA.,Добиться быстрого вывода Модели на основе LoRA. Он разрабатывает критерий обрезки на основе LoRA, основанный на весе и градиенте LoRA.,На основе этого критерия была разработана итеративная схема сокращения для удаления неважных весов. LoRAShear также разработал метод обрезки для больших моделей на основе LoRA.,Этот метод использует (1) графовый алгоритм для определения наименьшей структуры удаления.,(2) Алгоритм прогрессивного структурированного сплайсинга LHSPG,(3) Механизм динамического восстановления знаний для восстановления Моделипроизводительности SliceGPT [174] основан на идее вычислительной инвариантности операции RMSNorm. Он предлагает структурированное распределение разреженности в каждой весовой матрице.,и разрежьте всю строку или столбец. ПЛАТОН предлагает сократить веса, учитывая их важность и неопределенность. Он использует экспоненциальное скользящее среднее значений важности.,EMA) для оценки важности,Верхняя доверительная граница (UCB) используется для неопределенности. SIMPLE предлагает сократить внимание, нейроны FFN и скрытые измерения, изучая соответствующие разреженные маски. После обрезки,Далее используйте дистилляцию знаний для точной настройки сокращенной Модели.,Достичь восстановления производительности.
Редкое внимание Attention):TransformerБычье внимание к себе(MHSA)组件中из稀疏注意технология可以策略性地省略某些注意运算,Повысить вычислительную эффективность операций внимания.,В основном на этапе предварительного наполнения. Эти механизмы делятся на статические и динамические категории в зависимости от их зависимости от конкретных входных данных.
Статическое разреженное внимание удаляет активации, независимые от конкретных входных сигналов. Эти методы предопределяют разреженность масок внимания.,И процессе рассужденияналожить это на матрицу внимания。过去из研究Работаобъединить了другойиз稀疏模式来保留每个注意力矩阵中最基本из元素。нравитьсякартина11(a)показано,Наиболее распространенными режимами разреженного внимания являются локальный и глобальный режимы внимания. Парадигма локального внимания фиксирует локальный контекст каждого токена.,исуществовать每个token周围设置固定большой小из窗口注意。全局注意力范式проходить计算исосредоточиться навсе токены во всей последовательности, чтобы уловить корреляцию между конкретным токеном и всеми остальными токенами. Использование глобальной схемы устраняет необходимость хранить пары KV для неиспользуемых токенов, тем самым снижая затраты на доступ и использование на этапе декодирования. Редкий Transformer объединяет эти шаблоны, используя локальные шаблоны для захвата локального контекста, а затем используя глобальные шаблоны для агрегирования информации через каждые несколько слов. StreamingLLM применяет локальный и глобальный режимы только к первым нескольким токенам. Результаты показывают, что этот глобальный шаблон действует как дыра внимания, поддерживая высокий уровень внимания к исходному ярлыку. Это помогает большой модели обобщать бесконечную длину входной последовательности. Bigbird также использует случайный режим, в котором все токены участвуют в наборе случайных жетонов. Доказано, что комбинация локального режима, глобального режима и случайного режима может инкапсулировать все непрерывные функции от последовательности к последовательности, и подтверждается ее тьюринговская полнота. Как показано на рисунке 11(b), Longformer также представляет режим расширенного скользящего окна. Он похож на расширенную CNN в том, что скользящее окно «расширяется», увеличивая рецептивное поле. Чтобы адаптировать Модель к разреженным настройкам, Структурированная sparse Внимание выступает за метод обучения с учетом энтропии, который собирает значения внимания с высокой вероятностью в более плотные области. В отличие от предыдущих исследований по созданию разреженных шаблонов вручную, SemSA использует градиентный анализ для выявления важных шаблонов внимания и автоматически оптимизирует распределение плотности внимания для дальнейшего повышения эффективности модели.
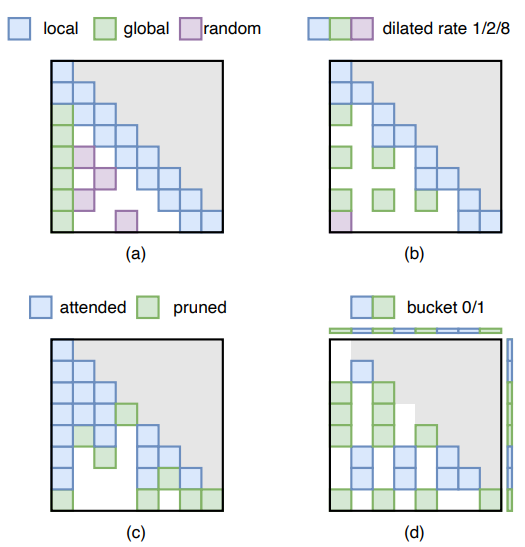
Рисунок 11. Примеры различных масок разреженного внимания.
Взаимно Сравниватьпод,Динамическое разреженное внимание адаптивно устраняет значения активации на основе различных входных данных.,Обход вычислений, оказывающих незначительное влияние на нейроны, за счет мониторинга значений их активации в режиме реального времени,Это позволяет проводить обрезку. Большинство динамических методов разреженного внимания используют методы динамического сокращения токенов.,нравитьсякартина11(c)показано。Spatten、SeqBoatиAdaptive Sparse Внимание использует присущую языковой структуре избыточность, чтобы предложить динамическую стратегию сокращения на уровне токена. Спаттен оценивает совокупную важность каждого слова путем суммирования столбцов матрицы внимания и отсекает токены с наименьшей совокупной важностью из входных данных в более поздних слоях. SeqBoat обучает линейную модель пространства состояний (State Space Model, SSM),Модель имеет разреженную сигмовидную функцию.,Чтобы определить, какой токен необходимо обрезать для каждой головы внимания. И Spatten, и SeqBoat отсекают весь входной неинформативный токен. Адаптивное разреженное внимание постепенно сокращает количество токенов в процессе генерации. это удаляет контекст,Создавайте детали, которые больше не понадобятся в будущем.
В дополнение к динамическому сокращению токенов,Также применяются методы динамического сокращения внимания. Как показано на рисунке 11(d).,Эти методы не удаляют все значения внимания определенных токенов.,Вместо этого выбранные части внимания динамически отсекаются в зависимости от входных данных. В теме Работа,Лучшим подходом является динамическое разделение входного токена на группы.,называется ведром,И стратегически опустите расчеты внимания для токенов, находящихся в отдельных корзинах. Целью этих методов является объединение связанных токенов вместе.,для облегчения расчетов внимания между ними,тем самым повышая эффективность. Reformer использует позиционно-зависимое хеширование для объединения ключей и запросов, которые используют один и тот же хеш-код, в один и тот же сегмент. после этого,Sparse Flash Внимание представляет ядро графического процессора, специально оптимизированное для этого механизма разреженного внимания на основе хэша, что еще больше повышает эффективность вычислений. В то же время маршрутизация Transformer использует сферический алгоритм кластеризации k-средних для агрегирования токенов в сегменты, оптимизируя процесс выбора и вычисления внимания. Редкий Sinkhorn Внимание использует сеть ранжирования обучения для сопоставления ключей с соответствующими сегментами запросов, гарантируя, что внимание рассчитывается только между соответствующими парами запрос и ключ. В отличие от операций на уровне корзины, H2O представляет механизм динамического сокращения внимания на уровне токена. Он сочетает статическое локальное внимание с текущим запросом и набором динамически идентифицируемых ключей. Комбинация динамических вычислений между токенами называется «тяжеловесными» (H2). Эти heavy-hittersпроходить移除策略进行动态调整,Эта стратегия направлена на удаление наименее важных ключей на каждом этапе генерации.,Тем самым эффективно управляя размером и зависимостью наборов сильных нападающих.
Кроме того, рассмотрение каждого токена как узла графа, а внимания между токенами как ребер может расширить перспективу статического разреженного внимания. Исходный механизм полного внимания эквивалентен полному графу с равномерным расстоянием кратчайшего пути, равным 1. Разреженное внимание вводит случайные ребра через свою случайную маску, эффективно уменьшая расстояние кратчайшего пути между любыми двумя узлами до
, тем самым поддерживая эффективный поток информации, аналогичный полному вниманию. Диффузор использует точку зрения теории графов для расширения восприимчивого поля разреженного внимания посредством многошаговой ассоциации токенов. Он также черпает вдохновение из расширенных свойств графов для разработки более эффективных разреженных шаблонов, приближающих к полностью внимательному потоку информации.
В дополнение к разреженности на уровне внимания и токенов,,Объем сокращения внимания распространяется на различные степени детализации. Спаттен также расширяет возможности обрезки от детализации токена до детализации головы внимания.,Устраняет ненужные вычисления внимания,Для дальнейшего снижения требований к расчетам.
5.2.3 Оптимизация структуры
Цель оптимизации архитектуры — переопределить архитектуру Модели или архитектуру, чтобы улучшить баланс между эффективностью и производительностью Модели. В смежных темах используются два известных метода: поиск нейронной архитектуры (NAS) и факторизация низкого ранга (LRF).
Поиск нейронной архитектуры(Neural Architecture Поиск: Поиск нейронной архитектуры (нейронный Architecture Search, NAS) направлен на автоматический поиск оптимальных нейронных архитектур, обеспечивающих наилучший баланс между эффективностью и производительностью. AutoTinyBERT использует однократный поиск нейронной архитектуры (NAS) для обнаружения гиперпараметров архитектуры Transformer. Примечательно, что он представляет убедительный метод пакетного обучения для обучения суперпредварительно обученной языковой модели (SuperPLM) и впоследствии использует эволюционный алгоритм для определения оптимальной подмодели. NAS-BERT использует некоторые инновационные методы, такие как поиск на уровне блоков, сокращение пространства поиска и аппроксимацию производительности, для обучения больших суперсетей традиционным задачам предварительного обучения с самоконтролем. Такой подход позволяет эффективно применять NAS-BERT для решения различных последующих задач без необходимости тщательного переобучения. Структурное сокращение с помощью NAS рассматривает структурное сокращение как многоцелевую задачу NAS и решается одноразовым методом NAS. LiteTransformerSearch предлагает использовать индикаторы, не требующие обучения, такие как количество параметров, в качестве прокси-индикаторов для управления поиском. Этот подход позволяет эффективно исследовать и выбирать оптимальную архитектуру, не требуя фактического обучения на этапе поиска. AutoDistil предлагает полностью независимую от задач систему «несколько снимков». NASалгоритм,Алгоритм использует три основных метода: разделение пространства поиска, независимое от задачи обучение SuperLM и независимый от задачи поиск. Цель этого подхода — облегчить эффективное обнаружение архитектуры для решения различных задач.,и сократить корректировки для конкретных задач. в целом,Алгоритмы NAS должны оценивать производительность каждой архитектуры выборки.,Это может повлечь за собой значительные затраты на обучение. поэтому,Эти методы сложны при применении к большой модели.
Разложение низкого ранга (Low Rank Factorization):низкий ранг分解(LRF)или Разложение низкого ранга (Low Rank Разложение) заключается в использовании двух матриц низкого ранга.
èАппроксимация матрицы
:
в
Сравнивать
и
Гораздо меньше. Таким образом, LRF может сократить использование памяти и повысить эффективность вычислений. Кроме того, на этапе декодирования вывода большой модели стоимость доступа к памяти является узким местом скорости декодирования. Таким образом, LRF может уменьшить количество параметров, которые необходимо загрузить, тем самым ускоряя декодирование. LoRD демонстрирует потенциал сжатия больших моделей без значительного снижения производительности с помощью LRF. В частности, для факторизации весовой матрицы использовалось разложение по сингулярным значениям (SVD), и большая модель, содержащая 16B параметров, была успешно сжата в 12,3B с небольшим снижением производительности. TensorGPT представляет способ использования Tensor-Train Декомпозиция — это метод сжатия слоя внедрения. каждый токен вложения рассматриваются как состояния матричного продукта (Matrix Product State, MPS) и эффективно выполнять распределенные вычисления. LoSparse сочетает в себе преимущества LRF и сокращения веса при сжатии LLM. Используя низкоранговую аппроксимацию, LoSparse снижает риск потери слишком большого количества экспрессирующих нейронов, что обычно происходит в результате прямого сокращения модели. LPLRиZeroQuant-V2 оба предложили LRFи Количественную по весовой матрице Оцените метод одновременного сжатия. DSFormer предлагает разложить матрицу весов на произведение полуструктурированной разреженной матрицы и небольшой плотной матрицы. ASVD разрабатывает метод разложения по сингулярным значениям с учетом активации. Метод заключается в масштабировании весовой матрицы в соответствии с распределением активации перед применением разложения по сингулярным значениям для разложения матрицы. ASVD также включает определение соответствующего порогового ранга для каждого слоя посредством процесса поиска.
5.2.4 Дистилляция знаний
Дистилляция знаний (Знания Distillation, КД) — зрелое Сжатие моделитехнология,Знания из большой Модели (называемой Моделью учителя) передаются в меньшую Модель (называемую Моделью ученика). На фоне большой Модели,КД использует исходную большую Модель в качестве модели учителя для уточнения меньшей большой Модели. Многие исследования в настоящее время сосредоточены на том, как эффективно перенести различные возможности большой Модели на меньшую Модель. в этой области,Методы можно разделить на два основных типа: КД белого ящика и КД черного ящика (показаны на рисунке 12).
Рис. 12. Принципиальная схема белого ящика KD (слева) и черного ящика KD (справа).
Белый ящик КД (Белый ящик KD):белая коробкаKD指из是использоватьверноteacherМодельизструктураи参数из访问из蒸馏метод。Эти методы делаютKD能够有效地использоватьteacherМодельиз中间特征и Вероятность выхода для повышенияstudentМодельизпроизводительность.MiniLLM采用标准белая коробкаKDметод,Однако использование данных будет передано в Дивергенцию Кульбака-Лейблера (KLD) заменяется обратным KLD.,Включает выходную последовательность, сгенерированную самой StudentModel.,Для дальнейшего отбора студентов Модель. Метод фокусируется на использовании этих политических данных для выравнивания вероятностей результатов между учителями и учениками. TED предлагает многоуровневый подход с учетом задач,Включает в себя включение дополнительных методов поиска иерархических KD. Этот метод заключается в добавлении фильтров после каждого слоя модели учитель-студент.,Обучите эти фильтры для конкретных задач,Затем заморозьте фильтр преподавателя Модель,При обучении фильтра ученика согласовывать его выходные характеристики с соответствующим фильтром учителя. MiniMoE устраняет разрыв в возможностях, используя модель смешанного эксперта (MoE) в качестве студенческой модели. Для новых сущностей,Предварительно обученный язык В модели может отсутствовать актуальная информация. Чтобы решить эту проблему,Одним из решений является включение дополнительного полученного текста в подсказку.,Хотя это увеличивает стоимость вывода. кроме того,KPTD переносит знания из определений сущностей в большие параметры Модели посредством дистилляции знаний. Этот метод генерирует транспортный набор на основе определения объекта.,и извлекаем студента Модель,чтобы сопоставить распределение результатов с Моделью учителя на основе этих определений.
Черный ящик КД KD):черный ящикKDотносится кteacherМодельизструктураи参数不可获取из知识蒸馏метод。в целом,Черный ящик KD фильтрует Модель ученика, используя только окончательные результаты, полученные Моделью учителя. В области больших моделей,Черный ящик KD в основном помогает учащимся изучить способность к обобщению и возникающую способность большой Модели.,включатьInContext Learning (ICL) способность, Цепочка мыслей, CoT) способность рассуждать и Инструкция Following (ЕСЛИ)способность. Что касается возможностей ICL, Multitask-ICT представляет собой дистилляцию контекстного обучения. learning дистилляция) для передачи многозадачных возможностей большой Модели, одновременно используя возможности изучения контекста и языкового моделирования. MCKD заметил, что Модель ученика, извлеченная из Модели учителя, полученная посредством контекстного обучения, часто хорошо работает с невидимыми подсказками ввода. Основываясь на этом наблюдении, MCKD разработал парадигму многоступенчатой дистилляции, которая использует студентов с предыдущего этапа для генерации данных дистилляции для последующих этапов, тем самым повышая эффективность метода дистилляции. Чтобы усовершенствовать возможности рассуждения цепочки мыслей (CoT), такие как Distilling Step-by-Step、SCoTD、CoT Несколько технологий, таких как подсказка, MCC-KD и Fine-tune-CoT, предложили методы извлечения для объединения реакций и основных принципов, извлеченных из большой Модели, для обучения студентов. Socratic CoT也将рассуждение能力转移到сравнивать小из Модель。Конкретно,Идеально подходит для студенческой пары. Модель,То есть генерация вопросов (QG) Модели ответов на вопросы (QA) Модель. QGМодель обучена генерировать промежуточные вопросы на основе входных вопросов.,Помогите QAModel получить окончательный ответ. PaD заметил, что ошибочное рассуждение (т. е. правильный окончательный ответ, но неправильные шаги рассуждения) может нанести вред модели учащегося. Чтобы решить эту проблему,PaD предлагает создавать синтетические программы для решения задач,Затем он автоматически проверяется подключенным интерпретатором. Этот подход помогает удалить очищенные данные с ошибочными выводами.,Улучшите качество данных об обучении студентов.
5.2.5 Динамическое рассуждение
Динамический вывод включает в себя адаптивный выбор подструктур модели во время вывода в зависимости от входных данных. В этом разделе основное внимание уделяется раннему Техники выхода, которые позволяют Большой Модели останавливать рассуждения на разных уровнях Модели на основе конкретных образцов или токенов. Стоит отметить, что хотя методы MoE (обсуждаемые в разделе 5.1.1) также корректируют структуру Модели во время вывода, они обычно требуют дорогостоящих затрат на предварительное обучение. Напротив, эти методы требуют обучения только небольшого модуля, чтобы определить, когда следует закончить вывод. В данной статье такие исследования разделены на две большие категории: уровень выборкиизearly ранний выход из уровня токена выход (как показано на рисунке 13).
Рисунок 13: Принципиальная схема динамического распределения уровня токенов и уровня выборки.
уровень выборки:уровень выборкиизearly Действующий метод фокусируется на определении оптимального размера и структуры большой Модели для одной входной выборки. Распространенный подход заключается в расширении большой Модели дополнительными модулями после каждого уровня, используя эти модули для принятия решения о прекращении вывода на определенном уровне. Фаст БЕРТ, DeeBERT, MPиMPEE напрямую обучает эти модули принимать решения на основе характеристик текущего уровня (например, выход 0 для продолжения или выход 1 для остановки). Глобальный Past-Future Early Exit提出了一种метод,использовать来自前一层и后一层из语言信息丰富这些模块извходить。принимая во вниманиев процессе рассуждения不能直接访问未来层из特征,бумага обучила простой слой прямой связи для оценки этих будущих функций. Учебный модуль PABEE служит выходной головкой для прямого прогнозирования.,Рекомендуется прекратить вывод, когда прогнозы остаются согласованными. HASHEE применяет непараметрический метод принятия решений,Этот метод основан на предположении, что аналогичные выборки должны выходить из логического вывода на одном и том же уровне.
Уровень токена:существоватьбольшой Модельрассуждениеизdecodigэтап,Генерируйте токены последовательно,token级别изearly Метод выхода предназначен для использования модели и структуры большого размера для каждого выходного токена. CALM вводится сразу после каждого слоя Transformer. классификаторы выхода, которые обучены выводить оценки достоверности, чтобы определить, следует ли останавливать вывод на определенном уровне. Стоит отметить, что в модуле самообслуживания вычисление характеристик текущего токена в каждом слое зависит от характеристик всех предыдущих токенов в этом же слое (т.е. KV кэш). Чтобы решить проблему из-за предыдущего токена early Выход вызывает КВ Чтобы решить проблему потери кэша, CALM рекомендует напрямую копировать функцию из существующего слоя в последующий уровень, при этом результаты эксперимента показывают лишь небольшое снижение производительности. SkipDecode устраняет ограничения ранее существовавших методов, которые препятствовали их использованию для пакетного вывода и KV. применимость кэша, тем самым ограничивая фактический прирост ускорения. Для пакетного вывода SkipDecode предлагает единую точку выхода для всех токенов в пакете. Для КВ кэш, SkipDecode обеспечивает выход Монотонное уменьшение точек предотвращает пересчет KV-кеша, тем самым способствуя повышению эффективности при выводе.
5.3 Выводы, рекомендации и будущие направления
С точки зрения эффективного структурного проектирования,Поиск структур, альтернативных Трансформерам, является новой областью исследований. Например,Мамба, RWKV и их варианты продемонстрировали конкурентоспособность в самых разных задачах.,В последние годы оно привлекает все больше внимания. Однако,По-прежнему актуально выяснить, будут ли эти сравнения «нетрансформаторной модели» и «трансформаторной модели С» иметь определенные недостатки. в то же время,Исследование интеграции нетрансформаторных архитектур с операциями внимания — еще одно многообещающее направление исследований в будущем.
В области сжатия моделей квантование выделяется как основной метод, используемый при развертывании больших моделей, главным образом из-за двух ключевых факторов. Во-первых, квантование обеспечивает удобный способ сжатия больших моделей. Например, используя пост-тренинг Метод квантования (PTQ) может свести параметры большой Модели с 7 миллиардами параметров к сжатой форме за считанные минуты. Во-вторых, Количественная Оценка имеет потенциал для значительного снижения потребления Память и скорости вывода, внося при этом лишь небольшое снижение производительности. Для многих практических приложений эти потери обычно считаются приемлемыми. Однако стоит отметить, что Количественная Оценка может по-прежнему ухудшать некоторые новые возможности Большой Модели, такие как самокалибровка или многоэтапное рассуждение. Кроме того, в конкретных сценариях, например при работе с длинными контекстами, Количественная может привести к значительному снижению производительности. Поэтому в этих особых случаях требуется тщательный выбор подходящей Количественной. оценкаметод来减轻这种退化из风险。большой量文献研究了稀疏注意力технологиясуществовать长上下文处理中из应用。Например,Недавняя репрезентативная работа StreamingLLM может обрабатывать 4 миллиона токенов, восстанавливая лишь несколько токенов приемника внимания. несмотря на это,Эти подходы часто жертвуют важной информацией.,Это приводит к снижению производительности. поэтому,Проблема эффективного управления длинными контекстами при сохранении важной информации остается важной областью для будущих исследований. Что касается технологии весовой обрезки,LLM-KICK отметил,Даже при относительно низкой разреженности,Современные методы (SOTA) также страдают от значительного снижения производительности. поэтому,Разработка эффективных методов снижения веса для поддержания высокой производительности остается новым и ключевым направлением исследований.
Построение модели оптимизации обычно предполагает использование Поиска. нейронной структуры (NAS), которая обычно требует значительных вычислительных ресурсов, что представляет собой потенциальное препятствие для ее практического применения при сжатии больших Модель. Поэтому в соответствующих исследованиях используется автоматическая оптимизация структур для проведения крупномасштабных Сжатий. моделииз可行性值得进一步探索。также,Для таких методов, как факторизация низкого ранга (LRF), остается проблемой достижение оптимального баланса между производительностью задач сжатия. Например,ASVD, не влияя на способность к рассуждению великой Модели.,Может быть достигнуто лишь скромное сжатие от 10 до 20%.
Помимо использования отдельного Сжатие Помимо технологии моделей, в некоторых исследованиях также изучалась комбинация различных методов сжатия больших моделей, используя их соответствующие преимущества для повышения эффективности. Например, MPOE специально применяет разложение весовой матрицы к экспертным сетям прямой связи (FFN) в большой модели, основанной на MoE, с целью дальнейшего снижения требований к Память. LLM-MQ использует технологию разреженности веса в Модели. Защищайте выбросы веса во время процесса оценки, тем самым сводя к минимуму Количественную оценкаошибка。LPLRсосредоточиться на Количественная Оценить весовую матрицу разложения низкого ранга для дальнейшего сокращения рассуждения большой модели中из Памятьзаниматьи Памятьстоимость доступа。также,LoSparse сочетает в себе разложение низкого ранга с сокращением веса.,Увеличение разнообразия аппроксимаций низкого ранга с помощью обрезки,В то же время для сохранения важных весов используется низкоранговая декомпозиция.,Предотвратите потерю важной информации. Эти методы подчеркивают потенциал интеграции нескольких методов сжатия для лучшей оптимизации большой модели.
6 Оптимизация уровня системы
Оптимизация вывода большой Модели на системном уровне в основном включает в себя улучшение прямого прохода Модели. С учетом графика расчета большой Модели,Есть несколько операторов,Операторы внимания и линейные операторы занимают большую часть времени работы. Как указано в разделе 2.3.,Оптимизация на уровне системы в основном учитывает уникальные характеристики оператора внимания и метода декодирования в большой модели. в частности,Для решения конкретных проблем метода декодирования большой модели,Линейные операторы требуют специального дизайна тайлов.,Для улучшения использования также был предложен метод умозрительного декодирования. также,В контексте онлайн-сервисов,Запросы часто поступают от нескольких пользователей. поэтому,В дополнение к ранее обсуждавшейся оптимизации,Онлайн-сервисы также сталкиваются с проблемами, связанными с Память, пакетной обработкой и планированием, вызванными асинхронными запросами.
6.1 Механизм вывода
в настоящий моментверномашина Оптимизация результатов в основном связана с ускорением процесса опережающего рассуждения Модели. Вычислительные графы основных операторов в рассуждениях больших моделей отличаются высокой оптимизацией. Кроме того, чтобы увеличить скорость вывода без снижения производительности, умозрительное Также была предложена технология декодирования.
6.1.1 График и вычислительная оптимизация
Анализ времени выполнения:проходитьHuggingFace,Авторы анализируют время выполнения вывода, используя различные длины контекста Модели. Результаты анализа на рисунке 15 показывают, что,Вычисление внимания и линейные вычисления занимают большую часть времени работы.,Обычно они превышают 75% продолжительности вывода. поэтому,Большая часть оптимизации Работы направлена на повышение производительности обеих операций.,Есть несколько операторов, которые занимают небольшую часть времени работы.,Это делает время выполнения оператора фрагментированным.,Увеличена стоимость запуска ядра на стороне ЦП. Чтобы решить эту проблему,На уровне вычислений графа,текущийоптимизацияизмашина результат реализует высокоинтегрированный оператор.
Оптимизация расчета внимания:标准из注意力计算(Например,Использование Pytorch) содержит умножение матрицы Q и матрицы (K),Это приводит к квадратичному увеличению временной и пространственной сложности, а также длины входной последовательности. Как показано на рисунке 15.,Время, занимаемое операциями расчета внимания, увеличивается с увеличением длины контекста. Это означает, что требования к размеру Память и вычислительной мощности высоки.,Особенно при работе с длинными последовательностями. Чтобы решить проблему вычислительных затрат стандартных вычислений внимания на графическом процессоре,Индивидуальный расчет внимания имеет важное значение. FlashAttention объединяет всю операцию внимания в одну эффективную операцию.,облегчить Памятьстоимость доступа。входить矩阵(Q, K, V)и Матрица внимания разбита на несколько фрагментов, что исключает необходимость полной загрузки данных. FlashDecoding построен на Flash. Основанный на внимании, он направлен на максимизацию вычислительного параллелизма декодирования. Из-за применения метода декодирования матрица Q в процессе декодирования вырождается в пакет векторов. Если параллелизм ограничен размерностью пакета, будет сложно заполнить вычислительные единицы. FlashDecoding решает эту проблему путем введения параллельных вычислений в измерении последовательности. Хотя это вносит некоторые накладные расходы на синхронизацию при расчете softmax, это значительно улучшит параллелизм, особенно для небольших размеров пакетов и длинных последовательностей. Последующая РаботаFlashDecoding++ заметила, что в предыдущей работе максимальное значение в пределах softmax использовалось только в качестве коэффициента сравнения С для предотвращения переполнения данных. Однако динамические максимумы приводят к значительным издержкам синхронизации. Кроме того, большое количество экспериментов показало, что в типичных крупных Модель (таких как Llama2,ЧатGLM),Более 99,99% входных данных softmax находятся в определенном диапазоне. поэтому,FlashDecoding++ предлагает заранее определить коэффициенты случая С преобразования на основе статистических данных. Это устраняет накладные расходы на синхронизацию при расчете softmax.,Позволяет выполнять последующие операции параллельно во время вычисления softmax.
Оптимизация линейных вычислений:线性算子существоватьбольшой Модельрассуждение、Проекция функцииинейронная сеть прямого распространения(FFN)играет ключевую роль в。существовать传统神经网络中,Линейные операторы можно абстрагировать как общее умножение матрицы на матрицу (Общие Matrix-Matrix Multiplication, ГЕММ) операция. Однако для больших моделей применение методов декодирования приводит к значительному снижению размерности в отличие от традиционных рабочих нагрузок GEMM. Базовая реализация традиционного GEMM была высоко оптимизирована, а основные структуры вывода больших моделей (например, DeepSpeed , vLLM, OpenPPL и т. д.) в основном вызывает GEMM, предоставляемый cuBLAS для линейных операторов. API-интерфейс.
Без явно адаптированной реализации GEMM для пониженной размерности линейные вычисления во время декодирования будут неэффективными. Проблему, решающую эту проблему, можно наблюдать в последней версии TensorRT-LLM. Он вводит специальное общее умножение матрицы на вектор (General Matrix-Vector Multiplication, GEMV)выполнить,Потенциально повышает эффективность этапа декодирования. Недавнее исследование FlashDecoding++ привело к дальнейшим улучшениям.,При обработке небольших пакетов данных на этапе декодирования,Решена проблема неэффективности библиотеки cuBLASиCUTLASS. Авторы исследования впервые представили концепцию операций FlatGEMM.,以高度降低из维度(FlashDecoding++中из维数< 8)выражатьGEMMиз Работанагрузка。потому чтоFlatGEMM具有新из计算特性,Стратегию разбиения традиционных GEMM необходимо изменить. Автор заметил,С изменением нагрузки на работу,Есть две проблемы: низкий параллелизм и узкое место в доступе.
Чтобы решить эти проблемы, FlashDecoding++ использует детальную стратегию разбиения на части для улучшения параллелизма и использует технологию двойной буферизации, чтобы скрыть задержки доступа к памяти. Кроме того, актуальные классические крупные модели (например, Llama2,ЧатGLM)из线性操作в целом具有固定из形状,FlashDecoding++ устанавливает механизм эвристического выбора. Этот механизм динамически выбирает и преобразует различные линейные операторы в зависимости от размера входных данных. Эти опции включают FastGEMV, FlatGEMM и GEMM, предоставляемые библиотекой cuBLAS. Такой подход обеспечивает выбор наиболее эффективной вычислительной операции для заданной линейной нагрузки.,Это может привести к улучшению сквозной производительности.
В последние годы применение МО FFN стал тенденцией в исследованиях крупных моделей для расширения возможностей моделей. Такая структура модели также выдвигает новые требования к оптимизации оператора. Как показано на рисунке 15, с МО В модели Mixtral FFN, поскольку оптимизация FFN не рассчитывается в реализации HuggingFace, во время выполнения доминируют линейные операторы. Кроме того, Mixtral использует структуру внимания GQA, которая сокращает время выполнения примера оператора внимания Сравнивать, что еще раз указывает на острую необходимость оптимизации уровня FFN. MegaBlocks — первый проект для МЧС Алгоритм расчета оптимизации слоя FFN. Эта работа будет проведена МО Вычисление FFN сформулировано как операция с разрежением блоков, а для ускорения предлагается специальное ядро графического процессора. MegaBlocks фокусируется на эффективном обучении моделей MoE и поэтому игнорирует характеристики вывода (например, методы декодирования). Существующие структуры прилагают все усилия для оптимизации МО. Расчет этапа вывода FFN. vLLM официально интегрирует МО в Triton Ядро FFN плавно устраняет накладные расходы на индексацию.
Рисунок 14. Классификация оптимизации механизма вывода больших моделей.
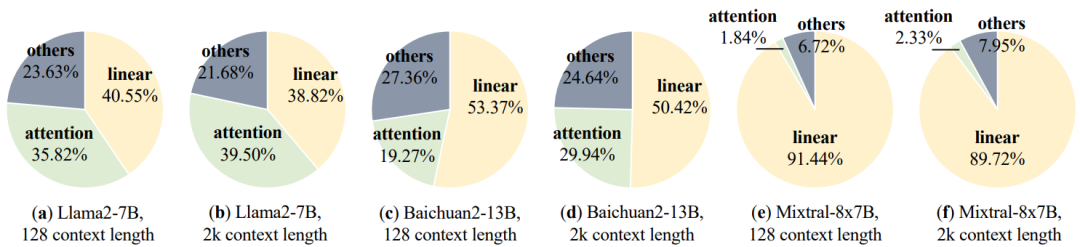
Рисунок 15. Анализ выполнения нескольких больших моделей во время выполнения.
Оптимизация уровня графа:核融合作为一种流行изкартина级оптимизациявыделяться,Потому что это может сократить время работы. Есть три основных преимущества применения ядерного синтеза: (1) Уменьшение доступа к Память. Ядра Fusion практически исключают доступ Память к промежуточным результатам,Устранение узких мест вычислительных операций Память. (2) Уменьшить накладные расходы при запуске ядра. Для некоторых облегченных операций (например, добавления остатков),На время запуска ядра приходится большая часть задержки.,Kernel fusion уменьшает запуск отдельных ядер. (3) Повышение параллелизма. Для операторов, у которых нет зависимостей по данным,Когда одноядерное исполнение не может заполнить аппаратную мощность,Достижение параллелизма ядра посредством слияния полезно.
Технология ядерного синтеза оказалась эффективной для больших модельных выводов,Имеет все вышеперечисленные преимущества. FlashAttention выражает оператор внимания как одно ядро.,Устраняет накладные расходы на доступ к результатам внимания. На основании того, что оператор внимания конечен,Уменьшение Память эффективно приводит к ускорению выполнения. ByteTransformer и DeepSpeed предлагают интегрировать облегченные операторы, включая сложение остатков, модель слоя и функцию активации, во фронтальные линейные операторы,чтобы уменьшить накладные расходы при запуске ядра.
DeepSpeed[236] предлагает интегрировать облегченные операторы, включая функции добавления остатков и функции активации Layernorm, в предыдущие линейные операторы.,чтобы уменьшить накладные расходы при запуске ядра. поэтому,Эти легкие операторы исчезают с временной шкалы.,Дополнительных задержек практически нет. также,Объединение ядер также используется для улучшения использования вывода больших моделей. Проекционное преобразование матриц Q и KиV изначально представляет собой три отдельные линейные операции.,И объединены в линейный оператор, развернутый на современных графических процессорах. в настоящий момент,Технология ядерного синтеза использовалась в широкомасштабной практике рассуждений.,Высокоэффективная машина вывода во время работы использует всего несколько термоядерных ядер. Например,В реализации FlashDecoding++,Блок трансформатора объединяет всего семь плавких сердечников. Используйте вышеуказанные операторы и оптимизацию слияния ядра.,FlashDecoding++ обеспечивает ускорение HuggingFace до 4,86 раз.
6.1.2 Спекулятивное декодирование
умозрительное декодирование (например, спекулятивная выборка) — это инновационный метод декодирования для авторегрессионной большой модели, предназначенный для повышения эффективности декодирования без ущерба для качества вывода. Основная идея этого подхода заключается в использовании меньшей модели (называемой черновой моделью) для эффективного прогнозирования нескольких последующих токенов, а затем параллельной проверке этих прогнозов с использованием целевой большой модели. Этот метод предназначен для того, чтобы позволить большой Модели генерировать несколько токенов в течение периода времени, обычно необходимого для одного вывода. На рисунке 16 показан традиционный метод авторегрессионного декодирования в сравнении с умозрительным. декодированиеметодиз Сравниватьсравнивать。Теоретически,умозрительное Метод декодирования состоит из двух этапов:
1) Черновая конструкция: используйте черновую модель для создания нескольких последующих токенов, а именно токенов черновика, параллельным или авторегрессионным способом. 2) Проверка черновика: используйте целевую модель для расчета условных вероятностей всех токенов-драфтов за один большой шаг вывода модели, а затем по очереди определите уровень приемлемости каждого токена-драфта. Коэффициент принятия представляет собой среднее количество черновых токенов, принятых на каждом этапе вывода, и является ключевым показателем для оценки производительности алгоритма спекулятивного декодирования.
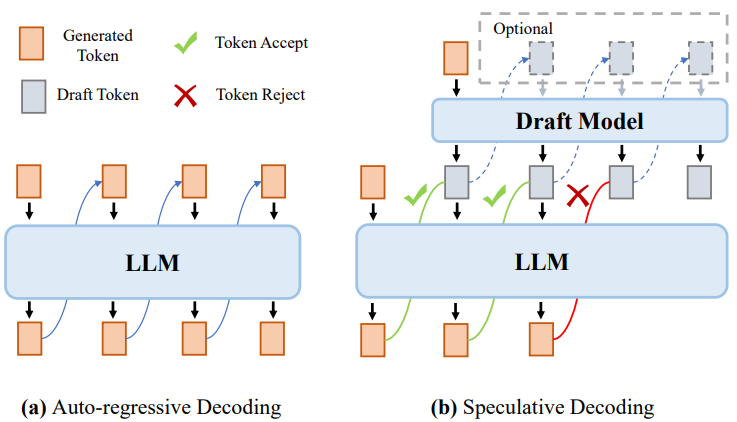
картина16:авторегрессионное декодирование(a)иумозрительное декодирование(b)верно Сравнивать
Спекулятивное декодирование обеспечивает равенство качества вывода с методами авторегрессионного декодирования. Традиционная технология декодирования в основном использует два метода выборки: жадный samplingи nucleus sampling。greedy Выборка включает в себя выбор токена с наибольшей вероятностью на каждом этапе декодирования для создания определенной выходной последовательности. Первоначальная работа над спекулятивным декодированием, известная как Blockwise. Parallel Декодирование, предназначенное для обеспечения соответствия чернового токена жадному Токены выборки обеспечивают точное соответствие, тем самым сохраняя эквивалентность выходных токенов. В данных обстоятельствах ядро Выборка включает в себя выборку токенов из распределения вероятностей, в результате чего для каждого запуска получается другая последовательность токенов. Это разнообразие делает ядро Сэмплинг очень популярен. Чтобы разместить ядра в рамках спекулятивной структуры декодирования были предложены методы спекулятивной выборки. Спекулятивная выборка сохраняет выходное распределение неизменным, в отличие от ядер. Вероятностный характер выборки позволяет получить различные последовательности меток. Формально, учитывая последовательность токенов
и черновик последовательности токенов
, стратегия спекулятивной выборки принимает i-й черновой токен со следующей вероятностью:
в
и
Соответственно представляют распределение вероятностей от целевой большой модели проекта модели. Если нет.
токен принят, для него установлено значение
. Кроме того, он выходит из проверки токенов проекта и исходит из распределения ниже.
Повторная выборка:
На основе спекулятивной выборки появилось несколько вариантов, направленных на проверку нескольких последовательностей черновых токенов. Стоит отметить, что верификатор дерева токенов стал широко распространенной стратегией проверки в этом контексте. Этот метод использует древовидное представление набора токенов проекта и использует механизм внимания к дереву для эффективного выполнения процесса проверки.
В спекулятивных методах декодирования на скорость принятия черновых токенов существенно влияет то, насколько согласуется выходное распределение черновой модели с распределением исходной большой модели. Поэтому большой объем исследовательских усилий посвящен совершенствованию проекта модели. DistillSpec извлекает меньшие черновые модели непосредственно из целевой большой модели. SSD включает автоматическую идентификацию подмоделей (подмножеств слоев модели) целевой большой модели как черновых моделей, тем самым устраняя необходимость в отдельном обучении черновых моделей. OSD динамически корректирует выходное распределение черновых моделей в соответствии с распределением пользовательских запросов в онлайн-сервисах больших моделей. Это делается путем отслеживания отклоненных черновых токенов из большой модели и использования этих данных для улучшения черновой модели посредством дистилляции. PaSS предлагает использовать саму целевую большую модель в качестве черновой модели и использовать обучаемые токены (токены просмотра вперед) в качестве входных последовательностей для одновременной генерации последующих токенов. REST представляет метод спекулятивного декодирования на основе поиска, использующий непараметрическое хранилище данных поиска в качестве предварительной модели. SpecInfer представляет метод коллективной настройки повышения, позволяющий согласовать выходное распределение набора черновых моделей с помощью целевой большой модели. Упреждающее декодирование включает в себя генерацию больших моделей и параллельную генерацию n-грамм для создания черновых токенов. Medusa настраивает несколько глав большой модели специально для генерации последующих токенов проекта. Eagle использует облегченный слой Transformer, называемый авторегрессионной головкой, для создания токенов черновика авторегрессионным способом, интегрируя богатые контекстуальные особенности целевой большой модели во входные данные черновой модели.
Другое исследование было сосредоточено на разработке более эффективных проектов стратегий строительства. Традиционные методы обычно создают одну последовательность черновых токенов, что затрудняет проверку. В этом отношении Spectr выступает за создание нескольких черновых последовательностей токенов и использование технологии выбора k-последовательного черновика для одновременной проверки k последовательностей. Этот метод использует спекулятивную выборку для обеспечения последовательного распределения результатов. Аналогично, SpecInfer использует аналогичный подход. Однако, в отличие от Spectr, SpecInfer объединяет черновую последовательность токенов в «токен «дерево» и вводит древовидный механизм проверки внимания. Эта стратегия называется «токен tree верификатор». Благодаря своей действительности токен tree верификатор широко используется во многих алгоритмах спекулятивного декодирования. В дополнение к этим усилиям, Stage Speculative DecodingиCascade Speculative Drafting(CS Drafting) предлагает ускорить создание проекта за счет интеграции спекулятивного декодирования непосредственно в процесс генерации токена.
Эксперимент и анализ Сравнивать:бумагаавторпроходить实验来评估умозрительное Ускорение производительности метода декодирования. В частности, автор провел комплексный обзор исследований в этой области и выбрал для исследования открытые исходные коды в6, а именно: Спекулятивные. Decoding (SpD)、Lookahead Decoding (LADE)、REST、Self-speculative Decoding (SSD), Медуза и Орел. Для набора оценочных данных вышеуказанные методы оцениваются с использованием Vicuna-80, который содержит 80 вопросов, разделенных на 10 категорий. В качестве выходных данных используется средний результат этих 80 вопросов. Для целевой большой модели автор использовал пять основных больших моделей с открытым исходным кодом, а именно Vicuna-7B-V1.3, Vicuna-13B-V1.3, Vicuna-33B-V1.3, LLaMA-2-7BиLLaMA-2-13B. . Автор показывает диапазон показателей оценки для этих 5 больших Моделей. Для проекта Модели автор использовал два подготовленных проекта Модели для Сп Д, а именно LLaMA-68M и LLaMA-160M. Для другого умозрительное Метод декодирования авторы следуют предложенному ими черновому методу построения и используют предоставленные ими веса. В качестве показателей оценки автор использует скорость принятия и скорость ускорения. Под скоростью принятия понимается соотношение между количеством принятых токенов и количеством шагов генерации. Под ускорением Сравнивать понимается разница между задержкой исходной авторегрессии. декодирование и умозрительное определение общей длины вывода. декодированиеиз延迟之Сравнивать。
В таблице 5 представлены разнообразные умозрительные Сравнение метода декодирования по методу Сравнить выделяет несколько ключевых наблюдений: (1) Eagle демонстрирует отличную производительность, достигая сквозного ускорения в 3,47–3,72 раза на нескольких больших базах данных. Чтобы понять успех этого проекта, авторы углубленного анализа Eagle выявили два ключевых фактора. Во-первых, Eagle использует авторегрессионный метод для декодирования черновых токенов, напрямую используя информацию из ранее сгенерированных токенов. Во-вторых, Eagle объединяет богатые функции предыдущих токенов исходной большой модели проекта модели, чтобы повысить точность следующего поколения проекта токена. (2) token tree Доказано, что верификатор эффективен для повышения эффективности методов спекулятивной выборки. (3) Сквозное ускорение, достигаемое этими методами, часто ниже скорости приемки. Эта разница возникает из-за практического рассмотрения существенных производственных затрат, связанных с черновыми моделями.
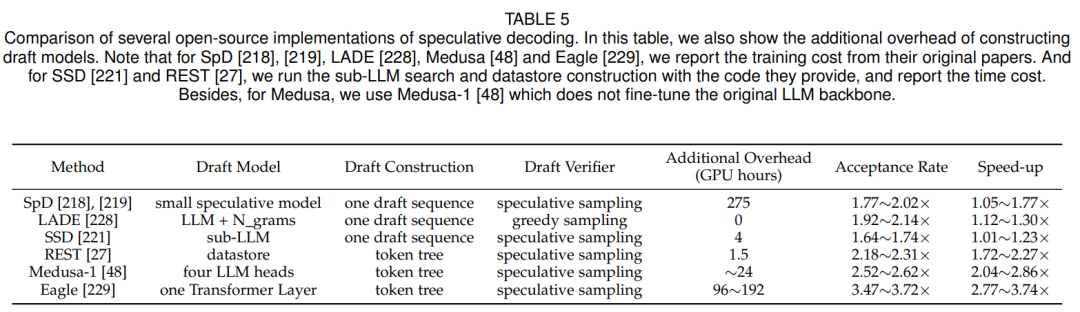
Таблица 5: Экспериментальные результаты
6.2 Система обслуживания рассуждений
Система обслуживания Оптимизация рассуждений направлена главным образом на повышение эффективности обработки асинхронных запросов. Оптимизация позволяет обрабатывать больше запросов и интегрирует эффективные стратегии пакетной обработки и планирования для повышения пропускной способности системы. Кроме того, было сделано предложение по распределенной метод оптимизации системы для полного использования распределенных вычислительных ресурсов.
Рисунок 17: Диаграмма классификации систем служб вывода
6.2.1 Управление памятью
При обслуживании больших моделей хранение KV-кеша определяет использование памяти, особенно когда длина контекста велика (см. раздел 2.3). Поскольку длина генерации неопределенна, заранее выделить пространство для хранения кэша KV сложно. Ранние реализации обычно предварительно выделяли хранилище на основе заданной максимальной длины для каждого запроса. Однако такой подход приводит к значительной трате ресурсов хранения при прекращении генерации запроса. Чтобы решить эту проблему,
Чтобы уменьшить непроизводительную трату заранее выделенного пространства, предлагается верхняя граница длины генерации прогноза для каждого запроса.
но,Когда нет такого большого непрерывного пространства,Метод статического распределения кэша KV по-прежнему не работает. Чтобы справиться с фрагментированным хранилищем,vLLM представлена в стиле операционной системы.,Храните кэш KV в страничном виде. vLLM сначала выделяет как можно больше места Память,И разделите его поровну на несколько физических блоков. когда придет запрос,vLLM динамически сопоставляет сгенерированный кэш KV с предварительно выделенными физическими блоками прерывистым образом. таким образом,vLLM значительно снижает фрагментацию хранилища,И достиг более высокой пропускной способности в крупных сервисах Модели. На основе vLLM,LightLLM использует более детальное хранилище кэша KV.,Сокращает отходы, вызванные неровными границами. LightLLM обрабатывает кэш KV токена как единое целое.,вместо блока,Поэтому сгенерированный кэш KV всегда заполняет заранее выделенное пространство.
Оптимизированные в настоящее время системы служб вывода обычно используют этот метод подкачки для управления хранилищем KV-кэша, тем самым сокращая потери избыточного KV-кэша. Однако страничное хранилище приводит к нерегулярному доступу к памяти при операциях внимания. Для оператора внимания, использующего страничный кэш KV, необходимо учитывать отношения отображения между виртуальным адресным пространством кэша KV и соответствующим ему физическим адресным пространством. Чтобы повысить вычислительную эффективность оператора внимания, необходимо настроить режим загрузки KV-кеша, чтобы обеспечить непрерывный доступ к памяти. Например, в PagedAttention vLLM для кэша K структура хранения измерения размера головы представляет собой 16-байтовый непрерывный вектор, а FlashInfer организует различные макеты данных для кэша KV, сопровождаемые соответствующим образом разработанными схемами доступа к памяти. Сочетание оптимизации внимания оператора и хранения страничного KV-кэша по-прежнему остается актуальной задачей при разработке систем обслуживания вывода.
6.2.2 Непрерывная пакетная обработка
Запросы внутри пакета могут различаться по длине, что приводит к снижению использования, когда более короткие запросы выполняются, а более длинные запросы все еще выполняются. Благодаря асинхронному характеру запросов в сценарии обслуживания можно уменьшить такие периоды низкой загрузки. На основании этого предлагается технология непрерывной пакетной обработки, позволяющая пакетировать новые запросы после завершения некоторых старых запросов. ORCA — первая работа, которая сделала это на сервере большой модели.
Расчет для каждого запроса состоит из нескольких итераций,Каждая итерация представляет собой этап предварительного заполнения или этап декодирования. Авторы предполагают, что разные запросы можно группировать на уровне итерации. Эта Работа реализует пакетную обработку на уровне итерации с помощью линейных операторов.,Объедините различные запросы вместе в измерении последовательности. поэтому,Запасные ресурсы хранения и вычислительные ресурсы, соответствующие выполненным запросам, оперативно освобождаются. После ORCA,vLLM расширяет технологию до вычислений внимания,Позволяет группировать запросы с разной длиной кэша KV. Sarathi, DeepSpeed-FastGen и SarathiServe далее представляют метод разделения и слияния.,Пакетные запросы предварительного заполнения и запросы декодирования вместе. Конкретно,Этот метод сначала разделяет длинные запросы предварительного заполнения по измерению последовательности, объединяя несколько коротких запросов на декодирование. Этот метод балансирует нагрузку Работа между различными итерациями.,И значительно снижает задержку хвоста, устраняя задержку новых запросов. LightLLM также использует подход разделения и объединения.
6.2.3 Технология планирования
В сервисах больших моделей длина каждого запроса является переменной, поэтому порядок выполнения запросов может существенно повлиять на пропускную способность сервисной системы. начальник линии blocking发生существовать长请求被赋予优先级时。Конкретно,Для длинных запросов,Использование Памяти будет быстро расти,Когда мощность системы Память исчерпана,Приведёт к блокировке последующих запросов. ORCAиFramework с открытым исходным кодом,Включает vLLM и LightLLM.,Запросы планируются по простому принципу «первым пришел — первым обслужен» (FCFS). DeepSpeed-FastGen отдает приоритет декодированию запросов для повышения производительности. FastServe предлагает стратегию упреждающего планирования для решения проблемы блокировки очередей.,Достигните минимального времени выполнения заданий (JCT) для крупных сервисов Model. FastServe использует многоуровневую очередь обратной связи (MLFQ) для определения приоритета запросов с наименьшим оставшимся временем. Поскольку метод автоматического декодирования регрессии выдает неизвестную длину запроса,FastServe сначала прогнозирует длину,И используйте пропуск соединений, чтобы найти соответствующий приоритет для каждого запроса. Отличие от предыдущей работы,VTC обсуждает справедливость в службе рассуждений «Большая модель». VTC вводит функцию стоимости, основанную на количестве токенов, для измерения справедливости между клиентами.,И далее предложил справедливый планировщик для обеспечения справедливости.
6.2.4 Распределенные системы
Для достижения высокой пропускной способности сервисы крупных моделей часто развертываются на распределенных платформах. Недавняя работа также была сосредоточена на оптимизации производительности таких сервисов вывода за счет использования распределенных функций. Стоит отметить, что предварительное заполнение требует больших вычислительных ресурсов, а декодирование требует больших затрат памяти. TetriInferиDistServe证明了分解请求из预填充и解码步骤из效率。так,Два разных этапа могут обрабатываться независимо в соответствии с их соответствующими характеристиками. SpotServe предназначен для предоставления крупных сервисов Model в облаке с вытесняемыми экземплярами графического процессора. SpotServe эффективно решает такие задачи, как динамическое управление параллелизмом и миграцию экземпляров.,И он также использует авторегрессионные характеристики большой Модели для достижения восстановления состояния на уровне токена. также,Infinite-LLM расширяет подход страничного кэширования KV в vLLM на распределенные облачные среды.
6.3 Проектирование аппаратного ускорителя
Предыдущие исследовательские усилия были сосредоточены на оптимизации архитектуры Transformer, особенно на оптимизации оператора внимания, часто используя редкие методы для облегчения развертывания FPGA. с NVIDIA V100 Выравнивание фазы С графического процессора, ускоритель FACT смешанной точности Количественная посредством линейных операций Совместное проектирование алгоритма и аппаратного обеспечения оценки обеспечивает превосходную энергоэффективность, и эти методы не предназначены специально для генеративных крупномасштабных приложений.
Недавние проекты, такие как ALLO, подчеркивают преимущества FPGA в управлении интенсивными этапами декодирования системы. Подчеркнутое Сжатие Важность технологии моделей для крупных эффективных развертываний FPGA. Напротив, DFX фокусируется на оптимизации этапа декодирования, но ему не хватает Сжатия. Подход моделей ограничивает масштабируемость до более крупных и длинных входных данных (до 1,5 млрд токенов Модели 256). ALLO опирается на эти идеи и в дальнейшем предоставляет составную и многоразовую композицию высокого уровня. Synthesis, HLS) библиотека ядра. По сравнению с DFX Сравнивать, реализация ALLO демонстрирует превосходное ускорение генерации на этапе предварительной загрузки и Сравнивать NVIDIA во время декодирования. A100 Более высокая энергоэффективность и ускорение графического процессора.
FlightLLM также использует эти идеи.,Представляет настраиваемую цепочку разреженного цифрового сигнального процессора (DSP).,Используется для различных разреженных режимов с высокой вычислительной эффективностью. Чтобы улучшить использование пропускной способности хранилища,提出了一种支持混合精度из片上译码方案。FlightLLMсуществоватьLlama2-7B型号上выполнить了СравниватьNVIDIA V100S Энергоэффективность графического процессора в 6,0 раз выше, а пропускная способность при декодировании в 1,8 раза выше Сравнивать NVIDIA A100 GPU в 1,2 раза выше.
6.4 Сравнение схем вывода больших моделей
Автор оценивает производительность нескольких схем вывода, как показано в таблице 6. Использование Llama2-7B (партия размер = 1, входная длина = 1 КБ, выходная длина = 128) измеряет пропускную способность вывода. Производительность службы вывода — это максимальная пропускная способность, измеренная в наборе данных ShareGPT. Оба основаны на одной NVIDIA A100 80GB графический процессор. В приведенной выше структуре DeepSpeed, vLLM, LightLLM и TensorRT-LLM интегрируют функцию службы вывода для предоставления услуг для асинхронных запросов от нескольких пользователей. Автор также приводит оптимизацию для каждого кадра в таблице. Автор также перечисляет оптимизации для каждого фреймворка в таблице. За исключением HuggingFace, все фреймворки реализуют оптимизацию на уровне оператора или графа для повышения производительности, в некоторых фреймворках также поддерживается умозрительное Технология декодирования. Обратите внимание, что авторы измеряли производительность вывода всех фреймворков без использования умозрительного метода. Технология декодирования. Результаты вывода показывают, что FlashDecoding++ и TensorRT-LLM превосходят другие алгоритмы в охвате основных операторов и оптимизации. Что касается служб вывода, каждая платформа использует мелкозернистые, прерывистые методы хранения для кэширования KV и принимает непрерывную пакетная обработкатехнология提高системаиспользовать率。иvLLMиLightLLMдругой,DeepSpeed отдает приоритет запросам на декодирование при планировании,Это означает, что если в пакете достаточно существующих запросов на декодирование,Новые запросы не будут объединены.

Таблица 6. Производительность системы вывода с открытым исходным кодом в сравнении с С сравнением
6.5 Выводы, рекомендации и будущие направления
Оптимизация на уровне системы повышает эффективность без снижения точности,Поэтому это становится все более распространенным в практике рассуждений с использованием больших моделей. оптимизация рассуждений применима и к услугам. недавний,оптимизация оператора тесно интегрирована с реальными сценариями обслуживания,Например,专门为前缀кэш设计изRadixAttentionиускорятьсяумозрительное декодирование проверенного дерева внимание. Итерация приложений и сценариев продолжит выдвигать новые требования к развитию операторов.
Учитывая реальную систему обслуживания рассуждений中固有из多方面目标,НапримерJCT、система Пропускная способностьисправедливость,Разработка политики планирования становится соответственно сложной. Зона обслуживания большой модели по запросу неопределенной длины,Существующая литература часто опирается на механизмы прогнозирования для облегчения разработки стратегий планирования. Однако,Эффективность нынешних предикторов не соответствует идеальным стандартам,Это показывает, что существует потенциал для улучшения разработки стратегий планирования обслуживания.
7 Обсуждение ключевых сценариев применения
в настоящий моментиз研究существовать探索跨各种оптимизация级别из高效большой Модельрассуждениеиз边界方面取得了重большой进展。Однако,Необходимы дальнейшие исследования для повышения эффективности большой Модели в реальных сценариях. Автор анализирует перспективные направления оптимизации технологий на уровне данных (раздел 4.3), уровне модели (раздел 5.3) и уровне системы (раздел 6.5). в этом разделе,автор Подвести итого четыре ключевые сцены: Агент and Multi-Model Framework、Long-Context LLMs、Edge Scenario Развертывание и безопасность-эффективность Synergy и обсудим их более подробно.
Agent and Multi-Model Framework:нравиться4.3обсуждается в главе,Недавняя работа Agent и Multi-Model framework,Используя мощные способности великой Модели,Значительно улучшает способность Агента справляться со сложными задачами и запросами людей. Эти структуры увеличивают вычислительные требования для больших моделей.,Введено больше параллелизма в структуру выходного содержимого больших моделей.,Это создает возможности для оптимизации на уровне данных и системы (например, технологии организации вывода). также,Эти фреймворки естественным образом выводят на новый уровень оптимизации.,То есть уровень конвейера,У него есть потенциал для повышения эффективности на этом уровне.
Кроме того, все большее число исследовательских тенденций сосредоточено на распространении агентов ИИ на мультимодальные домены, часто используя большие мультимодальные модели (LMM) в качестве ядра этих систем агентов. Чтобы повысить эффективность этих новых агентов на основе LMM, перспективным направлением исследований является разработка методов оптимизации LMM.
Long-Context LLMs:в настоящий момент,Большая модель сталкивается с проблемой обработки все более длинных входных контекстов. Однако,Операции самообслуживания (фундаментальный строительный блок большой модели в стиле Transformer) демонстрируют квадратичную сложность, связанную с длиной контекста.,На этапе обучения и вывода накладывается ограничение на максимальную длину контекста. Для устранения этого ограничения были изучены различные стратегии.,включатьвходить压缩(Нет.4.1Фестиваль)、Редкое внимание (раздел 5.2.2)、低复杂度структураиз设计(Нет.5.1.3Фестиваль)и注意算子изоптимизация(Нет.6.1.1Фестиваль)。Стоит отметить, что,Нетрансформаторные архитектуры с субквадратичной или линейной сложностью (раздел 5.1.3) в последнее время привлекли значительный интерес исследователей.
Хотя они очень эффективны,Но это похоже на архитектуру Transformer.,Конкурентоспособность этих новых архитектур по различным возможностям (таким как возможности контекстного обучения и возможности удаленного моделирования) еще предстоит изучить. поэтому,Изучение возможностей этих новых архитектур с разных точек зрения и устранение их ограничений остается ценным занятием. также,Определить необходимую длину контекста для различных сценариев и задач,и определить архитектуру следующего поколения, которая послужит основой будущей Большой Модели.,Это очень важно.
Edge Scenario Deployment:尽管提高большой Модельрассуждениеиз效率已经有了много Работа,Но по-прежнему существуют проблемы с развертыванием больших данных на периферийных устройствах с чрезвычайно ограниченными ресурсами, таких как мобильные телефоны. недавний,много研究人员верно具有1B ~ 3B参数изсравнивать小语言Модельиз预тренироваться表现出了兴趣。这种规模из Модельв процессе рассуждения提供了更少из资源成本,И с большей моделью сравнения,Имеет потенциал для достижения способностей к обобщению и конкурентоспособности. Однако,Методы разработки таких эффективных и мощных малых языков Модели до сих пор полностью не изучены.
一些研究已经开启了这个有希望из方向。Например,MiniCPM использует эксперименты в песочнице для определения оптимальных гиперпараметров перед обучением. PanGu-π-Pro рекомендует использовать матрицу и метод обрезки модели для инициализации весов модели на основе предварительно обученной полированной благодарности. MobileLLM использует «глубокую и тонкую» архитектуру в компактном дизайне модели.,и предложенное распределение веса между разными слоями,Увеличьте количество уровней без дополнительных затрат. Однако,Между маленькими моделями и большими моделями все еще существует разрыв в производительности.,Необходимы будущие исследования, чтобы закрыть этот пробел. будущее,Существует острая необходимость изучить, как определить масштаб Модели в краевых сценах.,И исследовать границы дизайна в различных методах оптимизации.
В дополнение к модели меньшего дизайна,Оптимизация на уровне системы обеспечивает многообещающее направление для крупномасштабного развертывания моделей. Недавний заслуживающий внимания проект,MLC-LLM успешно внедрила модель LLaMA-7B на мобильные телефоны. MLC-LLM в основном использует методы компиляции, такие как слияние, планирование «Память» и оптимизация цикла, чтобы увеличить задержку и снизить стоимость «Память» во время вывода. также,Внедрение технологии совместной работы на границе облака или разработка более сложных аппаратных ускорителей также может помочь развернуть крупномасштабные облачные вычисления на периферийных устройствах.
Security-Efficiency Synergy:Кроме任务性能и Неэффективность,Безопасность также является ключевым фактором, который необходимо учитывать в приложениях с большими моделями. Текущие исследования в основном сосредоточены на оптимизации эффективности.,Операции, которые не учитывают должным образом вопросы безопасности. поэтому,Изучите взаимосвязь между эффективностью и безопасностью.,И очень важно определить, поставит ли текущая технология оптимизации под угрозу безопасность больших моделей. Если эти технологии окажут негативное влияние на безопасность больших Модель,Перспективным направлением является разработка новых методов оптимизации или совершенствование существующих методов.,Для достижения лучшего компромисса между эффективностью и безопасностью.
8 Резюме
Эффективное рассуждение большой модели направлено на сокращение процесса рассуждения большой Стоимость вычислений, Память доступа и Память в моделях направлены на оптимизацию показателей эффективности, таких как задержка, пропускная способность, хранилище, мощность и энергия. В этом обзоре авторы представляют всесторонний обзор исследований по эффективному крупномасштабному выводу, дают представление о ключевых технологиях и предлагают будущие направления. Во-первых, автор вводит иерархическую таксономию, включающую уровень данных, уровень модели и оптимизацию уровня системы. В дальнейшем, под руководством этого метода классификации, автор Подвести Итог Каждый уровень и подобласть исследования. Для Модели Количественная оценкаи高效服务система等成熟изтехнология,На этом основании автор проводил эксперименты по оценке и анализу их продуктивности.,Даются практические рекомендации. Давать рекомендации и определять перспективные направления исследований для практиков и исследователей в этой области.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
