2024 год принадлежит эпохе маленьких моделей? Популярность TinyLlama и других небольших моделей резко возросла: легкие параметры, высокая производительность!
Маленькое тело, большая энергия.
Пока все изучают масштаб параметров больших моделей (LLM), достигающий десятков, а то и сотен миллиардов, внимание исследователей начинают привлекать небольшие модели, компактные и высокопроизводительные.
Маленькие модели имеют широкий спектр приложений на периферийных устройствах, таких как смартфоны, устройства Интернета вещей и встроенные системы. Эти периферийные устройства обычно имеют ограниченную вычислительную мощность и пространство для хранения, и они не могут эффективно запускать большие языковые модели. Поэтому особенно важно глубже вникать в небольшие модели.
Два исследования, которые мы представим далее, могут удовлетворить ваши потребности в небольших моделях.
TinyLlama-1.1B
Исследователи из Сингапурского университета технологий и дизайна (SUTD) недавно запустили TinyLlama. Языковая модель имеет 1,1 миллиарда параметров и предварительно обучена примерно на 3 триллионах токенов.

- Адрес статьи: https://arxiv.org/pdf/2401.02385.pdf.
- Адрес проекта: https://github.com/jzhang38/TinyLlama/blob/main/README_zh-CN.md
TinyLlama основана на архитектуре и токенизаторе Llama 2, что означает, что TinyLlama может автоматически подключаться ко многим проектам с открытым исходным кодом на основе Llama. Кроме того, TinyLlama имеет всего 1,1 миллиарда параметров и имеет небольшой размер, что делает ее подходящей для множества приложений, требующих ограниченного использования вычислительных ресурсов и памяти.
Исследование показывает, что только 16 графических процессоров A100-40G можно использовать для обучения TinyLlama за 90 дней.

Проект продолжает привлекать внимание с момента его запуска, а текущее количество звезд достигло 4,7 тыс.
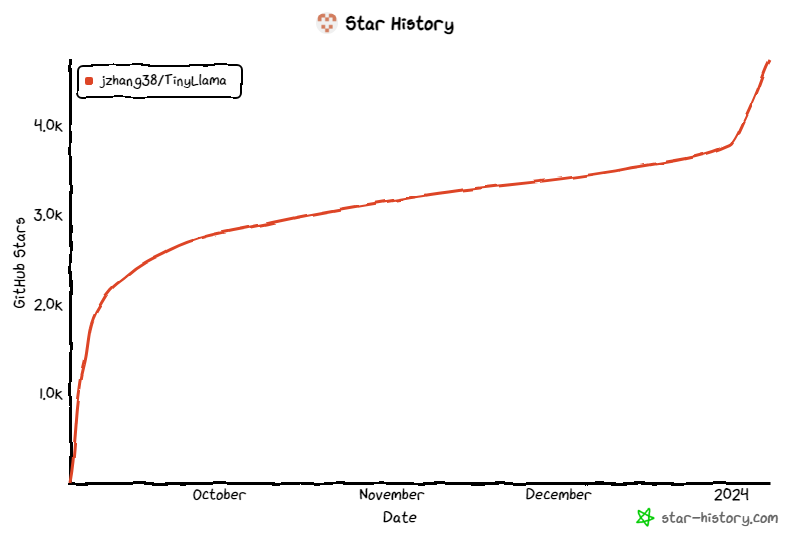
Детали архитектуры модели TinyLlama следующие:

Подробности обучения следующие:
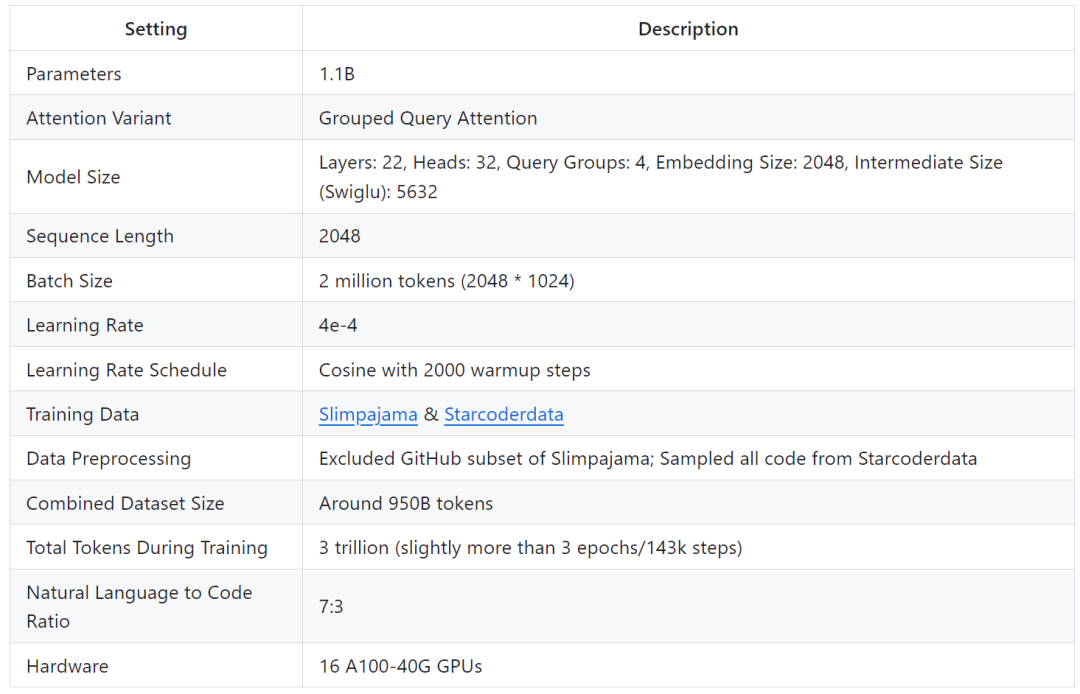
Исследователи заявили, что исследование направлено на изучение потенциала использования больших наборов данных для обучения меньших моделей. Они сосредоточились на изучении поведения моделей меньшего размера при обучении с использованием гораздо большего количества токенов, чем рекомендовано законом масштабирования.
В частности, в исследовании использовалось около 3 триллионов токенов для обучения модели Transformer (только декодер) с параметрами 1,1 млрд. Насколько нам известно, это первая попытка использовать такой большой объем данных для обучения модели с параметрами 1B.
Несмотря на относительно небольшой размер, TinyLlama чрезвычайно хорошо справляется с целым рядом последующих задач, значительно превосходя по производительности существующие языковые модели с открытым исходным кодом аналогичного размера. В частности, TinyLlama превосходит OPT-1.3B и Pythia1.4B в различных последующих задачах.
Кроме того, TinyLlama также использует различные методы оптимизации, такие как flash-внимание 2, FSDP (Fully Sharded Data Parallel), xFormers и т. д.
Благодаря поддержке этих технологий пропускная способность обучения TinyLlama достигает 24 000 токенов в секунду на графический процессор A100-40G. Например, модель TinyLlama-1.1B требует всего 3456 часов графического процессора A100 для токенов 300B по сравнению с 4830 часами для Pythia и 7920 часами для MPT. Это показывает эффективность оптимизации данного исследования и возможность сэкономить значительное время и ресурсы при обучении крупномасштабных моделей.
TinyLlama достигает скорости обучения 24 тыс. токенов в секунду/A100. Эта скорость эквивалентна тому, что пользователи могут обучать оптимальную для шиншиллы модель с 1,1 миллиардом параметров и 22 миллиардами токенов за 32 часа на 8 A100. В то же время эти оптимизации также значительно сокращают использование памяти. Пользователи могут поместить модель с 1,1 миллиарда параметров в графический процессор емкостью 40 ГБ, сохраняя при этом размер пакета для каждого графического процессора в размере 16 000 токенов. Просто измените размер пакета немного меньше, и вы сможете обучать TinyLlama на RTX 3090/4090.

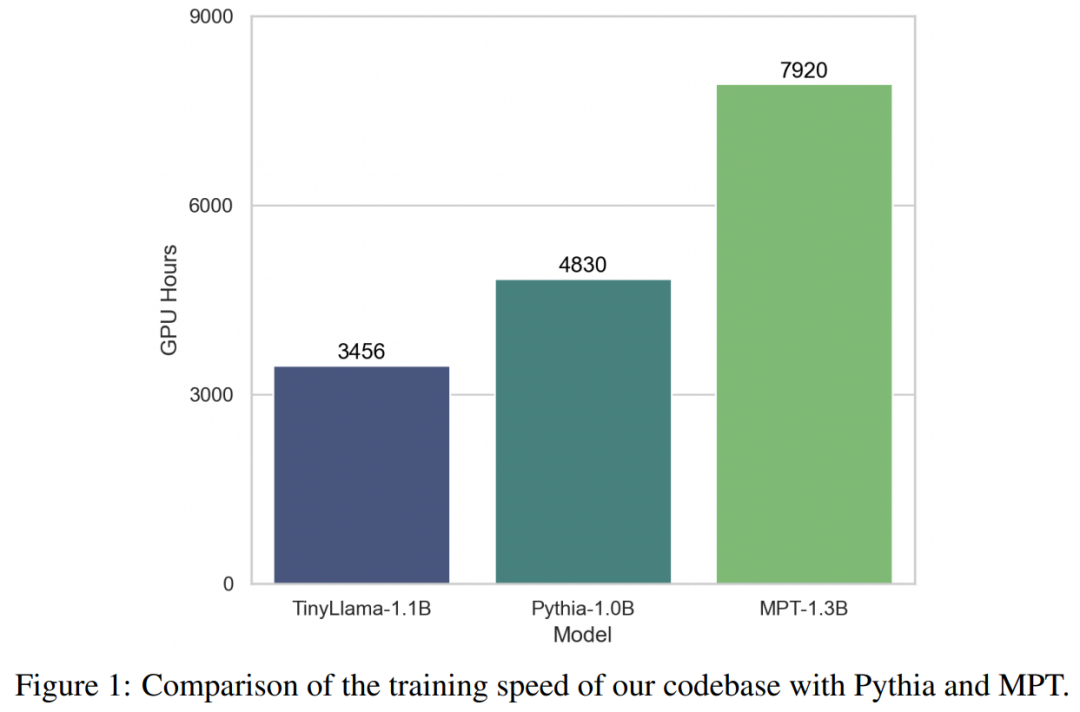
Экспериментально исследование сосредоточено на языковых моделях с чистой архитектурой декодера, содержащих около 1 миллиарда параметров. В частности, в исследовании сравнивали TinyLlama с OPT-1.3B, Pythia-1.0B и Pythia-1.4B.
Ниже показана производительность TinyLlama в решении задач на основе здравого смысла. Видно, что TinyLlama превосходит базовый уровень по многим задачам и достигает наивысшего среднего балла.

Кроме того, исследователи отслеживали точность TinyLlama в тестах на здравый смысл во время предварительного обучения. Как показано на рисунке 2, производительность TinyLlama улучшилась с увеличением вычислительных ресурсов, превзойдя точность Pythia-1.4B.
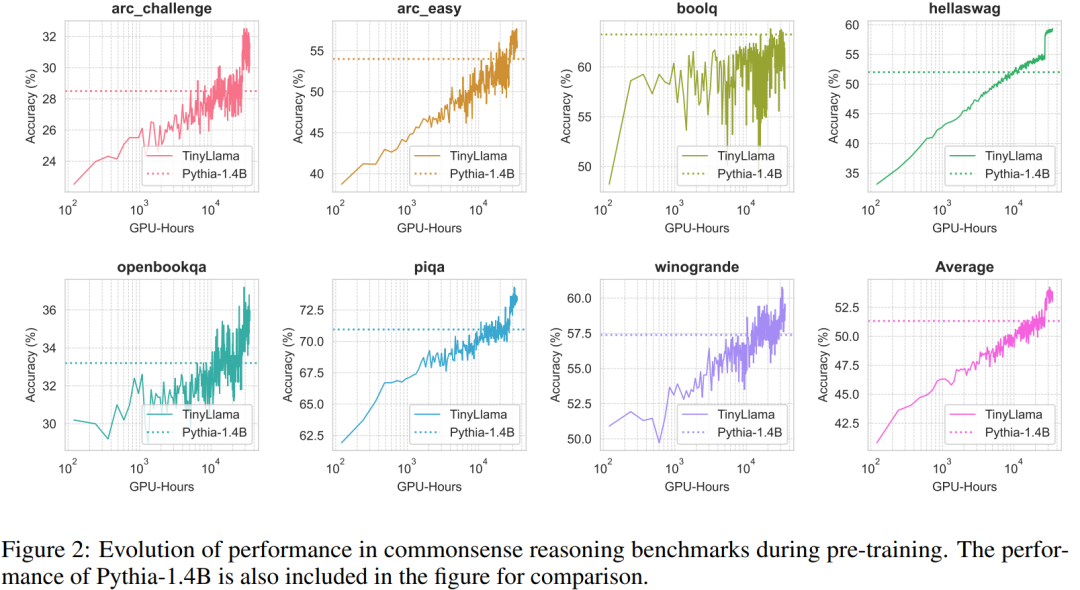
Таблица 3 показывает, что TinyLlama демонстрирует лучшие возможности решения проблем по сравнению с существующими моделями.
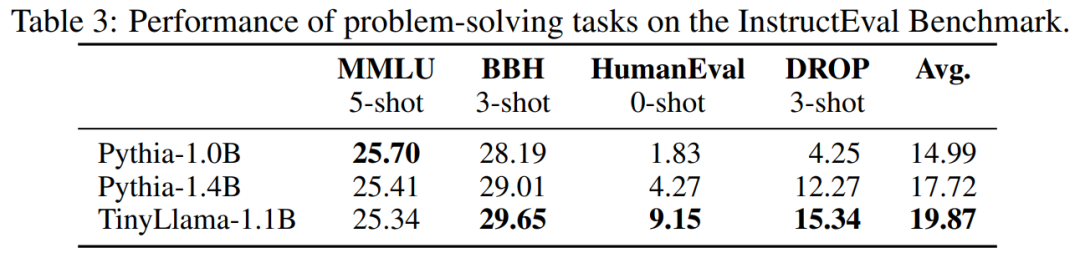
Пользователи сети с быстрыми руками уже начали усердно работать: эффект от бега на удивление хорош: на GTX3060 он может работать со скоростью 136 ток/сек.
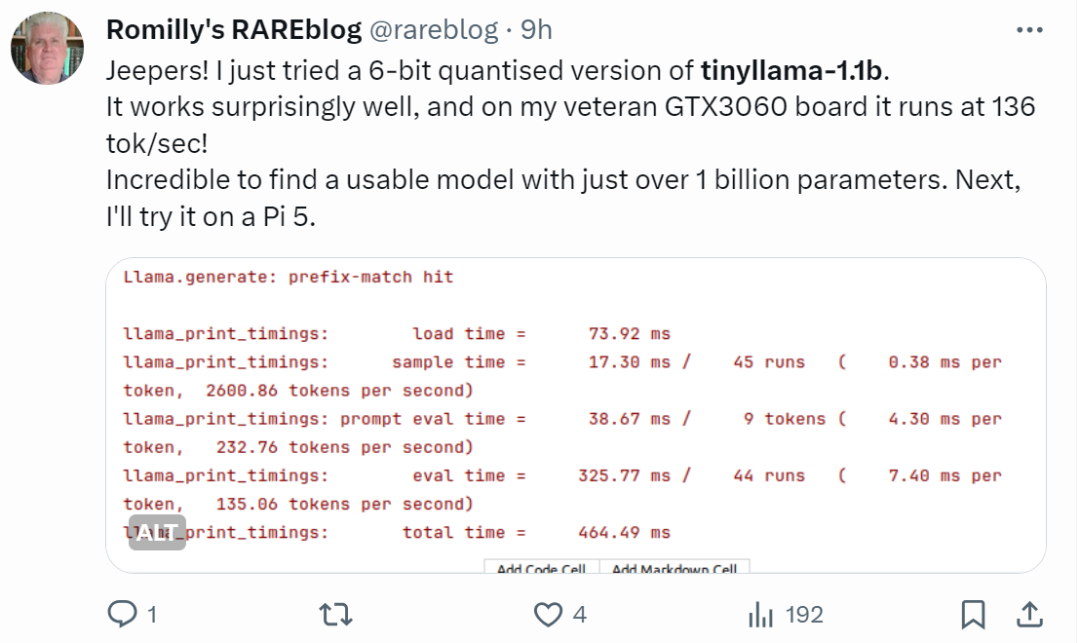
«Это действительно быстро!»
Маленькая модель LiteLlama
SLM (Small Language Model) начала привлекать много внимания благодаря выпуску TinyLlama. Сяотянь Хан из Техасского технологического университета и Университета A&M выпустил SLM-LiteLlama. Он имеет 460M параметров и обучается с помощью токенов 1T. Это ответвление LLaMa 2 от Meta AI с открытым исходным кодом, но со значительно меньшим размером модели.
Адрес проекта: https://huggingface.co/ahxt/LiteLlama-460M-1T
LiteLlama-460M-1T обучен на наборе данных RedPajama и использует GPT2Tokenizer для токенизации текста. Автор оценивал модель на задаче MMLU, и результаты показаны на рисунке ниже. Даже при значительно уменьшенном количестве параметров LiteLlama-460M-1T все равно может достигать результатов, сравнимых с другими моделями или превосходящих их.
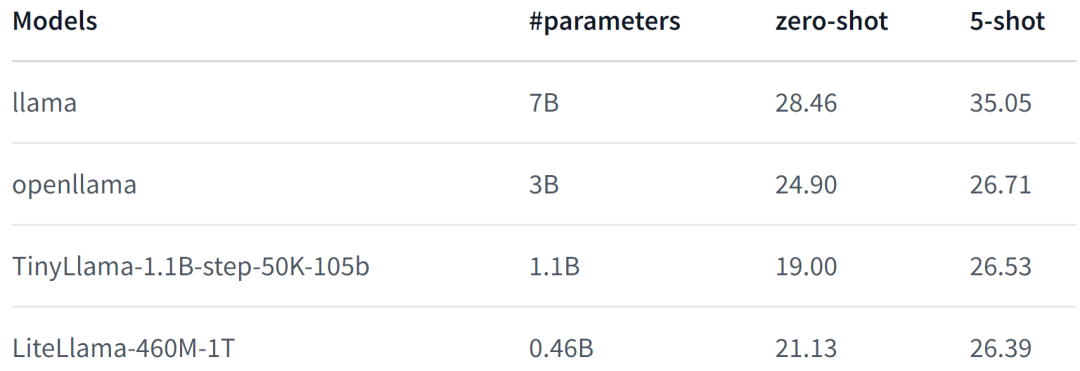
Ниже приведены характеристики модели. Для получения более подробной информации см.:
https://huggingface.co/datasets/open-llm-leaderboard/details_ahxt__llama2_xs_460M_experimental
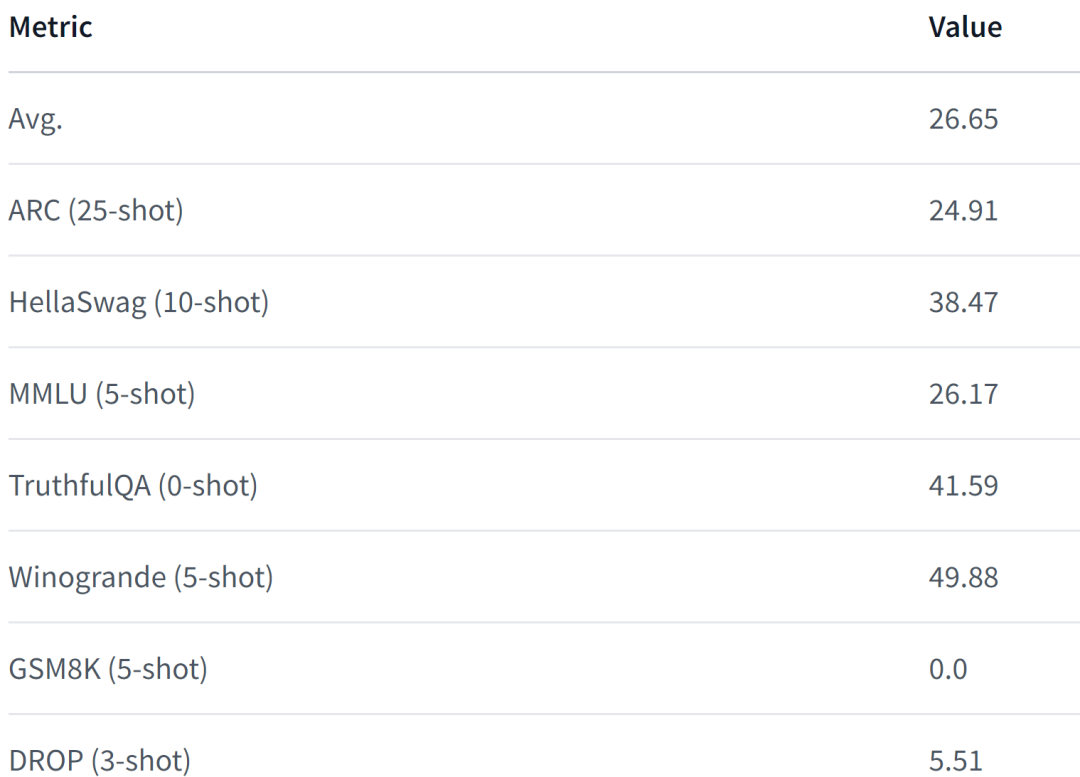
Столкнувшись со значительно уменьшенным размером LiteLlama, некоторые пользователи сети задаются вопросом, сможет ли он работать на 4 ГБ памяти. Если вы тоже хотите это знать, почему бы не попробовать самому.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
