2024 год! Глубокое понимание методов тонкой настройки модели большого языка (LLM) (резюме)
введение
Как мы все знаем, большие языковые модели (LLM) быстро развиваются, и в каждой отрасли есть своя большая модель. Среди них очень важную роль в этом процессе играет технология точной настройки больших моделей. Она повышает эффективность создания и адаптируемость модели, позволяя ей проявлять большую ценность в различных сценариях применения.
Так,Сегодняшняя статья даст вам более глубокое понимание большой тонкой настройки модели. В основном они включают в себя большую тонкую настройку модели, когда необходима большая настройка модели?、большой Модельметод тонкой настройки Подвести итог、большой Модель Лучшие практики точной настройкиждать。Получить соответствующие документы,отвечать:Точная настройка LLM
Жизненный цикл проекта LLM
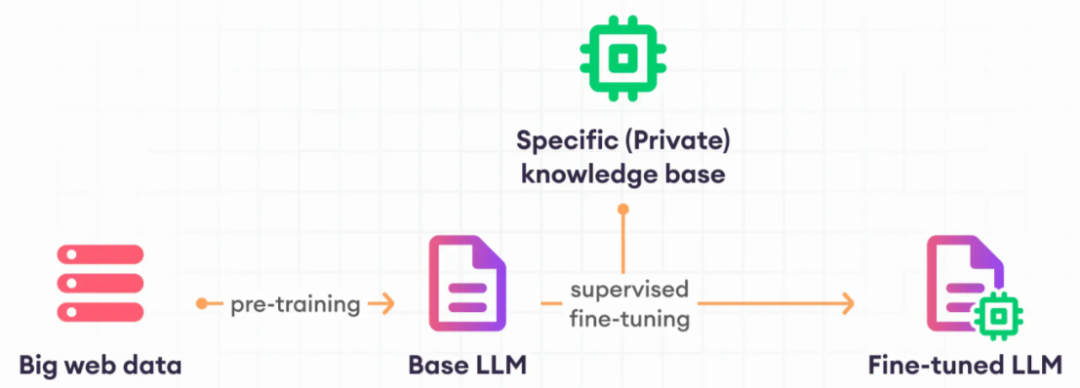
Представляем великолепный Модельметод тонкой настройки До,Во-первых, давайте посмотрим на жизненный цикл проекта Большой Языковой Модели.,Условно его можно разделить на следующие этапы,Как показано ниже

«1. Цели проекта»:первый,Уточнить цели проекта. Решите, будет ли LLM использоваться в качестве инструмента общего назначения или ориентирован на конкретную задачу (например, распознавание именованных объектов). Четкие цели помогают сэкономить время и ресурсы.
«2. Выбор модели»:обучение с нуля Модельи изменить существующие Модельвыбирать между。во многих случаях,Адаптация существующей Модели эффективна,но в некоторых случаях,Возможно, потребуется доработка новой модели.
"3. Производительность и настройка модели":Подготовить Модельназад,оценить егопроизводительность。еслипроизводительность Не хорошо,Попробуйте быстрое проектирование(prompt инженерное дело) или дальнейшая доводка. Убедитесь, что выходные данные модели соответствуют предпочтениям человека.
«4. Оценка и итерация»:Регулярно проводите оценку с использованием показателей и контрольных показателей.。Проект в кратчайшие сроки、тонкая настройкаперебирать между и оценивать,до тех пор, пока не будет достигнут желаемый результат.
«5. Развертывание модели»:когда Модель Когда производительность соответствует ожиданиям,Развертывать. на этом этапе,оптимизация Эффективность вычислений и удобство использования.
Точная настройка LLM
Точная настройка LLM — это процесс, в котором предварительно обученная Модель дополнительно обучается на меньшем конкретном наборе данных.,Цель состоит в том, чтобы усовершенствовать способности Модели.,улучшить свою производительность в конкретной задаче или областипроизводительность。«Цель тонкой настройки — преобразовать общую модель в специальную, устранить разрыв между общей моделью предварительного обучения и конкретными требованиями приложения и обеспечить, чтобы языковая модель была ближе к человеческим ожиданиям».。
Возьмем, к примеру, GPT-3 от OpenAI, усовершенствованный LLM, предназначенный для широкого спектра задач обработки естественного языка (NLP). Допустим, медицинская организация хочет использовать GPT-3, чтобы помочь врачам создавать отчеты о пациентах из текстовых заметок. Хотя GPT-3 может понимать и создавать общий текст, он не может быть оптимизирован для сложной медицинской терминологии и конкретной медицинской терминологии.
Чтобы улучшить производительность GPT-3 в этой специализированной роли, организация будет настраивать GPT-3 на наборе данных, содержащем медицинские отчеты и записи пациентов. Возможно, можно будет использовать такой инструмент, как специальный редактор LLM от SuperAnnotate, для создания модели с желаемым интерфейсом. Благодаря этому процессу модель лучше знакомится с медицинской терминологией, тонкостями клинического языка и типичными структурами отчетности. После тонкой настройки GPT-3 может помочь врачам создавать точные и последовательные отчеты о пациентах, демонстрируя его адаптируемость к конкретным задачам.
Хотя точная настройка кажется ценной для каждого LLM, имейте в виду, что за нее приходится платить. Далее эти затраты обсуждаются подробно.
Когда необходима Точная настройка LLM?
Когда речь идет о LLM, всегда затрагиваются такие темы, как контекстное обучение, рассуждения с нулевой выборкой, одной выборкой и несколькими выборками. Давайте кратко рассмотрим их основные функции.
**Контекстное обучение** – это метод улучшения подсказок путем добавления к подсказкам примеров для конкретных задач, что дает LLM схему выполнения задач.
«Нулевой, одноразовый и малошаговый рассуждения» Вывод с нулевым выстрелом использует входные данные непосредственно в приглашении без добавления дополнительных примеров. Если вывод с нулевым шагом не дает ожидаемых результатов, вы можете использовать вывод с одним или несколькими шагами. Эти стратегии включают добавление в приглашение одного или нескольких завершенных примеров, чтобы помочь небольшим LLM работать лучше.
«Проблема контекстного обучения» Применение этих методов непосредственно к подсказкам пользователя направлено на оптимизацию вывода модели для лучшего соответствия предпочтениям пользователя. Проблема в том, что они не всегда работают, особенно с небольшими LLM. Кроме того, любые примеры, включенные в приглашение, занимают ценное пространство контекстного окна, уменьшая пространство для другой полезной информации.
«Когда вышеуказанные методы не могут решить соответствующие проблемы, для этого требуется Точная настройка LLM」。Но он используется на этапе предварительной подготовки.большойколичество неструктурированного текстаданныедругой,Точная настройка — это контролируемый процесс обучения. Это означает, что вы используете набор помеченных примеров для обновления весов LLM. Эти отмеченные примеры обычно представляют собой быстрый ответ.,Сделайте Модель более способной выполнять определенные задачи.
Контролируемая точная настройка (SFT)
Контролируемыйтонкая настройкаозначает использование разметкиданные Обновить предварительно обученные языки Модельдля выполнения конкретных задач。использовалданные Проверено заранее。Это то же самое, что не проверятьданныенеконтролируемый методдругой。«Обычно первоначальное обучение языковых моделей проходит без присмотра, но контролируется точная настройка».。Далее мы познакомим васбольшой Модельтонкая настройка Конкретный процесс,Как показано ниже:
«1. Подготовка данных» Существует множество наборов данных с открытым исходным кодом, которые могут дать представление о поведении и предпочтениях пользователей, даже если они напрямую не отформатированы как поучительные данные. Например, мы можем использовать большой набор данных обзоров продуктов Amazon и превратить его в точно настроенный набор данных с подсказками. Библиотека шаблонов подсказок содержит множество шаблонов для разных задач и разных наборов данных.
«2. Выполнить тонкую настройку» Разделите набор данных на части обучения, проверки и тестирования. Во время тонкой настройки вы выбираете реплики из набора обучающих данных и передаете их в LLM, а модель генерирует готовый текст.
В частности, когда модель подвергается воздействию нового помеченного набора данных для целевой задачи, она вычисляет ошибку или разницу между ее прогнозами и фактическими метками. Затем модель использует эту ошибку для корректировки своих весов, обычно с помощью алгоритма оптимизации, такого как градиентный спуск. Величина и направление корректировок веса зависят от градиента, который показывает, насколько каждый вес вносит вклад в ошибку. Веса, которые вносят больший вклад в ошибку, корректируются больше, а веса, которые вносят меньший вклад, корректируются меньше.
«3. Итеративная корректировка» В течение нескольких итераций или эпох набора данных модель продолжает корректировать свои веса, постепенно находя конфигурацию, которая минимизирует ошибку для конкретной задачи. Цель состоит в том, чтобы адаптировать ранее полученные общие знания к нюансам и конкретным закономерностям в новых наборах данных, делая модель более специализированной и эффективной для решения целевой задачи.
«4. Обновление модели» В ходе этого процесса модель обновляется на основе помеченных данных. Он меняется в зависимости от разницы между его предположением и фактическим ответом. Это помогает модели изучить детали помеченных данных. Благодаря этому производительность модели при выполнении точно настроенной задачи будет улучшена.
Приведем простой пример: на вопрос «Почему небо голубое?» перед точной настройкой модели дается ответ: «Из-за того, как атмосфера рассеивает солнечный свет, однако, если модель применить к науке». и образовательной платформы, ответ кажется слишком кратким. После сбора соответствующих данных и точной настройки модели был получен ответ: «Причина, по которой небо кажется синим, заключается в явлении, называемом рэлеевским рассеянием. Когда солнечный свет попадает в атмосферу Земли, он содержит свет разных цветов, каждый из которых имеет разные цвета. у всех есть определенные длины волн. Синий свет имеет более короткие длины волн и рассеивается во всех направлениях газами и частицами в атмосфере. В результате этого рассеяния прямой солнечный свет кажется белым, а само небо кажется голубым», - выше. подходит для научных и образовательных платформ.
метод тонкой настройки
Точная настройка LLM — это контролируемый процесс обучения, который в основном использует аннотированные наборы данных для обновления весов LLM и позволяет Модели улучшить свои возможности для конкретной задачи. Далее мы познакомим вас с одним заслуживающим внимания методом. тонкой настройки。
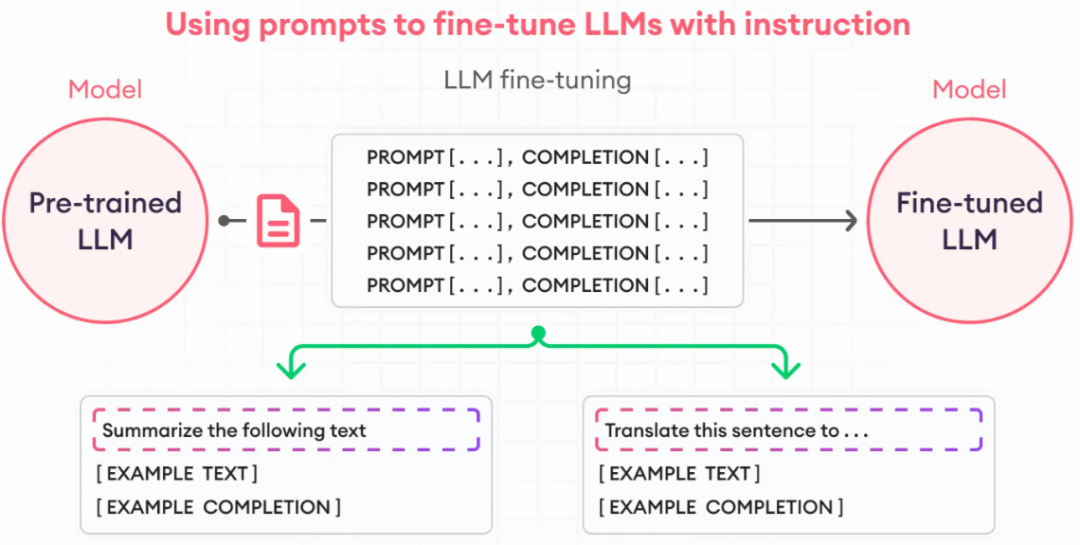
«1. Доработка инструкций» Одной из стратегий улучшения производительности модели при выполнении различных задач является точная настройка инструкций. Это предполагает обучение модели машинного обучения с использованием примеров, показывающих, как модель должна реагировать на запросы. Набор данных, используемый для точной настройки больших языковых моделей, должен соответствовать целям ваших инструкций.
Например, если вы хотите улучшить возможности суммирования вашей модели, вам следует создать набор данных, содержащий сводные инструкции и связанный текст. В задачу перевода должны быть включены такие инструкции, как «перевести этот текст». Эти подсказки помогают модели «думать» по-новому профессионально и решать конкретные задачи. Как показано ниже
«2. Полная точная настройка (БПФ)» То есть процесс обновления всех весов модели называется полной тонкой настройкой. В результате этого процесса создается новая версия модели с обновленными весами. Важно отметить, что, как и предварительное обучение, полная точная настройка требует достаточного объема памяти и вычислительного бюджета для хранения и обработки всех градиентов, оптимизаторов и других компонентов обновления во время обучения.
«3. Эффективная точная настройка параметров (PEFT) )」язык обучения Модельэто вычислительно интенсивная задача。дляLLMПолныйтонкая настройка,Память предназначена не только для хранения моделей.,Также сохраняйте необходимые параметры во время процесса обучения. Ваш компьютер может обрабатывать модели веса.,Но могут возникнуть проблемы с выделением лишней памяти для состояний оптимизации, градиентов и прямой активации во время обучения.
Простое оборудование не может справиться с этой задачей.。Это параметр эффективноститонкая настройка(PEFT)Ключ к。«В то время как полная Точная настройка LLM обновляет вес каждой Модели во время контролируемого обучения, метод PEFT обновляет только небольшую часть параметров»。Этот метод трансферного обучения выбирает конкретные Модель Компоненты и“заморозить”остальные параметры。оказаться,По сравнению с оригинальной моделью,Значительно уменьшено количество параметров (в некоторых случаях,только для оригинальных весов15-20%;2021предложено Microsoft LORA, предложенный Стэнфордом Префикс-Тюнинг, предложенный Google Prompt Настройка, предложенная Университетом Цинхуа в 2022 году. P-tuning v2, QLoRA, предложенный Вашингтонским университетом в 2023 году, DoRA, предложенный NVIDIA в 2024 году, и т. д. в основном попадают в эту категорию).
Это делает требования к памяти более управляемыми. И не только это,«PEFT также решает проблему катастрофического забывания. Поскольку он не затрагивает исходный LLM, модель не забудет ранее изученную информацию».。Полныйтонкая настройка Для каждого учебного задания будет создана новая версия.Модель,Каждая новая версия имеет тот же размер, что и оригинальная модель.,Если вы настраиваетесь на несколько задач,Это может создать дорогостоящие проблемы с хранением.
Другие виды тонкой настройки
«1. Трансферное обучение»:Трансферное обучение станет обычным явлением、большойшкаладанные Тренировался на съемочной площадке Модель,наборы данных, применяемые для конкретных задач. Этот метод подходит для ситуаций, когда данных недостаточно или время имеет решающее значение.,Преимуществом является более высокая скорость обучения и точность после обучения. Вы можете использовать LLM, такие как GPT-3 и BERT, которые предварительно обучены на большом количестве данных.,И настройте его под свой вариант использования.
«2. Тонкая настройка под конкретную задачу»:конкретная задачатонкая настройкапо конкретной задаче или сфере,Выполните точную настройку предварительно обученной модели, используя набор данных, предназначенный для этого домена. Этот метод требует больше данных и времени, чем трансферное обучение.,Но вы можете получить более высокую производительность на конкретных задачах.
«3. Катастрофическое забывание»:существовать Полныйтонкая настройкав процессе,Изменен вес Модели в одной задаче.,Может привести к падению производительности при выполнении других задач. Например,Модель может лучше работать при выполнении задач НЛП, таких как анализ настроений, после точной настройки.,Но может забыть, как выполнять другие задачи.
«4. Многозадачное обучение»:многозадачностьтонкая настройка Это одна задачатонкая настройкарасширение,Обучающий набор содержит примеры входных и выходных данных для нескольких задач. Этот метод может улучшить производительность Модели одновременно при выполнении всех задач.,Избегайте проблемы катастрофического забывания. Во время тренировки,Обновление весов модели путем расчета потерь за несколько периодов,В результате получается модель спиннера, которая хорошо справляется со многими задачами. Но многозадачная точная настройка модели требует большого количества данных.,Вероятно, потребуется от 50 000 до 100 000 примеров.
«5. Точная настройка последовательности»:заказтонкая настройкаэто предварительная подготовка Модель Последовательно адаптируйтесь к нескольким связанным задачам。При первоначальной миграции на общее поленазад,LLM может быть настроен для более конкретных подмножеств.,Например, от общего языка к медицинскому языку.,в детскую кардиологию.
Обратите внимание, что существуют и другие типы тонкой настройки, такие как адаптивная, поведенческая и обучающая, а также точная настройка с подкреплением, которые охватывают некоторые важные конкретные случаи обучения языковых моделей.
Получить улучшенную RAG
Говоря о тонкой настройке модели,Здесь я должен упомянуть Tweet улучшенную RAG. RAG – альтернатива тонкой настройке,Он сочетает в себе генерацию естественного языка и поиск информации.。RAGобеспечить язык Модель Предоставить источники информации через внешние новейшие знания или соответствующую документацию.。«Эта технология устраняет разрыв между обширными знаниями общих моделей и новейшими потребностями в знаниях и информации».。поэтому,RAG — важный метод, когда факты меняются с течением времени.
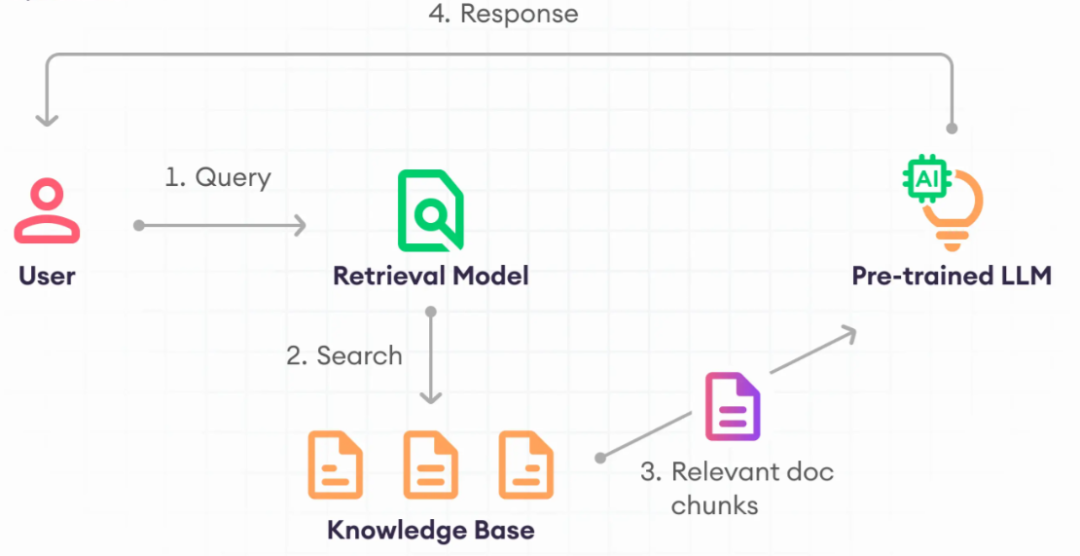
«Преимущества RAG» Одним из преимуществ RAG перед тонкой настройкой является управление информацией. Традиционная точная настройка включает в себя данные в архитектуру модели, по сути, «жесткое кодирование» знаний, которые нелегко модифицировать. RAG позволяет постоянно обновлять данные обучения, а также удалять или пересматривать данные, чтобы гарантировать точность модели.
«Взаимосвязь RAG и тонкой настройки» В контексте языковых моделей RAG и тонкая настройка часто рассматриваются как конкурирующие методы. Однако их совместное использование позволяет значительно повысить производительность. В частности, к системам RAG можно применить тонкую настройку, чтобы выявить и улучшить их более слабые компоненты, помогая им хорошо выполнять конкретные задачи LLM.
Подробное введение в RAG можно найти в этих двух статьях:
Лучшие практики точной настройки
«Ясная миссия»:существоватьтонкая настройкабольшойввести язык Модельв процессе,Уточнение миссии является основным шагом. оно может обеспечить четкое направление,Убедитесь, что мощные возможности Модели направлены на достижение конкретных целей.,И установите четкие ориентиры для измерения производительности.
«Выберите подходящую предварительно обученную модель»:Используйте предварительную тренировку Модельруководитьтонкая настройкаключевой,Потому что он использует знания, полученные из большого количества данных.,Убедитесь, что Модель не учится с нуля. Этот метод является одновременно эффективным в вычислительном отношении и экономит время. также,Предварительное обучение обеспечивает универсальное понимание языка,Включите тонкую настройку, чтобы сосредоточиться на деталях, специфичных для домена.,Обычно приводит к лучшей моделипроизводительности в профессиональных задачах.
«Установить гиперпараметры»:Гиперпараметры Модель Переменные, которые можно корректировать во время обучения,Крайне важно найти оптимальную конфигурацию для выполнения задачи. Скорость обучения, размер партии, количество эпох, снижение веса и т. д. являются ключевыми гиперпараметрами.,Необходимость подстроиться под оптимизацию Модель.
«Оценить производительность модели»:тонкая настройка Заканчиватьназад,Оцените Модельпроизводительность на тестовом наборе. Это обеспечивает объективную оценку ожидаемой производительности Модели на невидимых данных. Если у модели еще есть возможности для улучшения,Также следует учитывать модель оптимизации итерации.

5 шагов для установки среды протокола

Наиболее полные коды состояния HTTP
На основе языка Go мы шаг за шагом научим вас внедрять структуру системы управления серверной частью.
Эффективное управление журналами с помощью Spring Boot и Log4j2: подробное объяснение конфигурации

Что делать, если telnet не является внутренней или внешней командой [легко понять]

php-объект для анализа json_php json

Введение в принцип запуска Springboot, процесс запуска и механизм запуска.

Высокоуровневые операции Mongo, если данные не существуют, вставка и обновление, если они существуют (pymongo)
Проектирование и внедрение системы управления электронной коммерцией на базе Vue и SpringBoot.

Статья длиной в 9000 слов знакомит вас с процессом запуска SpringBoot — самым подробным процессом запуска SpringBoot в истории — с изображениями и текстом.

Как настроить размер экрана в PR. Учебное пособие по настройке размера видео в PR [подробное объяснение]
Элегантный и мощный: упростите операции ElasticSearch с помощью easy-es
Проект аутентификации по микросервисному токену: концепция и практика

【Java】Решено: org.springframework.http.converter.HttpMessageNotWritableException.
Изучите Kimi Smart Assistant: как использовать сверхдлинный текст, чтобы открыть новую сферу эффективной обработки информации
Начало работы с Docker: использование томов данных и монтирования файлов для хранения и совместного использования данных

Использование Python для реализации автоматической публикации статей в публичном аккаунте WeChat
Разберитесь в механизме и принципах взаимодействия потребителя и брокера Kafka в одной статье.
Spring Boot — использование Resilience4j-Circuitbreaker для реализации режима автоматического выключателя_предотвращения каскадных сбоев

13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS
