16 векторных баз данных, рекомендованных в 2024 году: повысьте производительность ваших приложений искусственного интеллекта
В эпоху искусственного интеллекта векторные базы данных стали неотъемлемой частью управления данными и моделей искусственного интеллекта. База данных векторов — это база данных, специально предназначенная для хранения и запроса векторных данных. Эти векторные внедрения являются ключевыми представлениями данных, используемыми моделями ИИ для выявления шаблонов, ассоциаций и скрытых структур. Учитывая популярность приложений искусственного интеллекта и машинного обучения, встраивания, создаваемые этими моделями, содержат большое количество атрибутов или функций, что затрудняет управление их представлением. Вот почему специалистам по работе с данными нужна база данных, специально разработанная для обработки такого рода данных, и именно здесь на помощь приходят векторные базы данных.
Разница между векторной библиотекой и векторной базой данных
Основное различие между библиотекой векторов и базой данных векторов заключается в том, что библиотека векторов используется для выполнения математических операций и геометрических расчетов с векторами, тогда как база данных векторов используется для хранения, поиска и управления крупномасштабными наборами векторных данных, таких как встраивания для машинного обучения и научных приложений данных. . Векторные библиотеки, такие как NumPy, предоставляют широкий набор математических операций и функций для работы с векторами, матрицами и многомерными массивами. Они оптимизируют производительность и широко используются в научных вычислениях, анализе данных и обучении. Библиотека векторов подходит для наборов данных небольшого и среднего размера и не обеспечивает встроенной поддержки многомерного поиска по сходству векторов или крупномасштабного управления данными. С другой стороны, векторные базы данных, такие как Milvus, Pinecone и Weaviate, предназначены для обработки крупномасштабных наборов векторных данных и предоставляют эффективные возможности поиска и управления сходством векторов. Они поддерживают многомерные векторы и предоставляют расширенные методы индексации, такие как HNSW, IVF и PQ, для быстрого и точного поиска сходства векторов. Векторные базы данных также обеспечивают масштабируемость и отказоустойчивость, что делает их пригодными для производственных сред и реальных приложений.
Векторные базы данных предоставляют эффективные возможности хранения и запроса уникальной структуры вложений векторов. Они открывают двери для простого поиска, высокой скорости, масштабируемости и поиска данных, обнаруживая сходства.
16 лучших рекомендаций по базам данных векторов
1. Pinecone
- Pinecone: https://www.pinecone.io/
- Нет открытого исходного кода
- решать проблемы:
- Pinecone — это размещенная в облаке векторная графика. база данных,Имеет простой API,Никаких требований к инфраструктуре не требуется. Пользователи могут быстро запускать, использовать и масштабировать свои решения искусственного интеллекта.,Нет необходимости выполнять какое-либо обслуживание инфраструктуры, мониторинг сервисов или отладку алгоритмов.
- Решение способно быстро обрабатывать данные.,и позволяет пользователям достигать высококачественных корреляций с помощью мета-данных фильтров и поддержки разреженной индексации.,Обеспечение быстрых и точных результатов для различных приложений.
- Ключевые особенности сосновой шишки включают в себя:
- Обнаружение дубликатов: помогает пользователям идентифицировать и удалять дубликаты данных.
- Отслеживание рейтинга: отслеживайте рейтинг данных в результатах поиска, помогая оптимизировать и корректировать стратегии поиска.
- данныепоиск:быстрыйпоискбаза данныхвданные,Комплекс поддержкипоисксостояние
- Классификация: классифицируйте данные для удобства управления и поиска.
- Дедупликация: автоматическое выявление и удаление дубликатов данных.,Поддерживать чистоту и согласованность набора данных.
2. MongoDB
- MongoDB: https://www.mongodb.com/
- GitHub stars: 25.2k
- решать проблемы:
- Обработка различных транзакционных и транзакционных рабочих нагрузок: MongoDB Atlas — это размещенная платформа данных для разработчиков, способная решать множество сложных задач по управлению данными.
- Функция векторного поиска: Атлас Vector Поиск использует специализированный векторный индекс, который можно использовать с базовой базой данных. автоматическая синхронизация данных, обеспечивающая интегрированную базу данных Преимущества независимого расширения данных.
- Ключевые особенности MongoDB Atlas включают:
- интегрированныйбаза данные+Векторный поиск: Обеспечивает мощную базу данных. функции данных и возможности векторного поиска
- Независимо предоставляемая база индексы данных и поиска: позволяет пользователям самостоятельно настраивать и расширять базу данныхипоискиндекс
- данныехранилище:Каждый документ можетхранилище Гандам16 MBизданные
- Высокая доступность、Надежная гарантия сделки、Многоуровневое сохранение данных、Архивы и резервные копии: обеспечение сохранности и надежности данных
- Лучшее в отрасли шифрование данных транзакций: защита данных от несанкционированного доступа
- Смешайте поиск: объедините несколько функций поиска.,Обеспечьте гибкий и мощный опыт поиска
3. Milvus
- Milvus: https://milvus.io/
- GitHub stars: 21.1k
- решать проблемы:
- Milvus — векторная графика с открытым исходным кодом. база данных, предназначенных для содействия внедрению векторов, эффективному поиску по сходству и приложениям искусственного интеллекта. Он был запущен как Apache с открытым исходным кодом в октябре 2019 года. Выпущена лицензия 2.0, в настоящее время LF AI & Data Дипломный проект при поддержке Фонда.
- Этот инструмент упрощает поиск неструктурированных данных.,И обеспечивает унифицированный пользовательский интерфейс независимо от среды развертывания. Для повышения устойчивости и адаптивности,Milvus Все компоненты рефакторинга 2.0 не имеют состояния.
- Milvusиз Случаи применения включают в себяизображениепоиск、Чат-боты и поиск химических структур.
- Ключевые особенности Милвуса:
- Набор векторных данных уровня миллисекунды на уровне триллиона
- Простое управление неструктурированными данными
- Надежная векторная база данных, всегда доступная
- Высокая масштабируемость и адаптируемость
- смешиваниепоиск
- Унифицированная лямбда-структура
- Поддерживается сообществом и признается отраслью
4. Chroma
- Chroma: https://www.trychroma.com/
- GitHub stars: 7k
- решать проблемы:
- Chroma DB — это встроенная векторная векторная система с открытым исходным кодом, созданная для искусственного интеллекта. база данных,Разработан для упрощения моделей машинного обучения за счет возможности подключения знаний, фактов и навыков в масштабе модели большого языка (LLM).,Процесс создания приложений LLM на основе обработки естественного языка.,Также избегайте галлюцинаций.
- Многие инженеры надеются создать «ChatGPT, предназначенный для данных».,Chroma обеспечивает такой тип связи посредством поиска документов на основе встраивания. Он также предоставляет комплексное обслуживание,Здесь есть все, что нужно вашей команде для хранения, внедрения и запроса данных.,Включает мощные возможности фильтрации,В ближайшее время появятся дополнительные функции, такие как интеллектуальная группировка и корреляция запросов.
- Ключевые особенности Chroma включают в себя:
- Богатые функции: поддерживает запросы, фильтрацию, оценку плотности и другие функции.
- Языковая цепочка (LangChain), LlamaIndex и другие функции будут добавлены в ближайшее время.
- Тот же API можно запустить в блокноте Python или распространить на кластер для разработки, тестирования и производства.
5. Weaviate
- Weaviate: https://github.com/weaviate/weaviate
- GitHub stars: 6.7k
- решать проблемы:
- Weaviate — это облачная векторная графика с открытым исходным кодом. база данные, эластичные, масштабируемые и быстрые. Этот инструмент использует передовые модели и алгоритмы машинного обучения для преобразования текста, фотографий и другого контента в читаемый векторный формат. база данных。
- Поиск соседей 10-NN можно выполнять по миллионам элементов.,Завершается за однозначные миллисекунды. Инженеры могут использовать это для векторизации своих данных в процессе импорта.,или отправьте свой вектор,Наконец создайте вопросы и ответыизвлекать、Подвести Итог и система классификации.
- Модуль Weaviate поддерживает использование известных сервисов и центров моделей, таких как OpenAI, Cohere или HuggingFace, а также использование локальных и пользовательских моделей. Weaviate разработан с учетом масштаба, репликации и безопасности.
- Ключевые особенности Weaviate включают в себя:
- Встроенный поиск на основе искусственного интеллекта、Вопросы и ответы、Интегрируйте LLM с вашими модулями данных и автоматической классификации.
- Полная функциональность CRUD (создание, чтение, обновление, удаление).
- Облачный, распределенный, способный масштабироваться по мере роста рабочих нагрузок и хорошо работающий в Kubernetes.
- Возможность беспрепятственного переноса моделей машинного обучения в MLOps.
6. Deep Lake
- Deep Lake: https://github.com/activeloopai/deeplake
- GitHub stars: 6.4k
- решать проблемы:
- Deep Lake — это искусственный интеллект, управляемый собственным форматом хранения данных. данных,Предназначен для глубокого обучения и приложений на основе больших языковых моделей (LLM).,Эти приложения используют обработку естественного языка.。он проходит векторхранилищеи Ряд функций помогает инженерам быстрее развертывать продукты корпоративного уровня.изLLMпродукт。
- Deep Lake может обрабатывать данные любого размера,бессерверный,Позволяет находиться в одном местехранилищевседанные。
- Он также обеспечивает интеграцию инструментов, помогающую упростить операции глубокого обучения. Например, используя Deep Озеро и гири & Biases,Может отслеживать эксперименты и реализовывать модели.из Полностью повторяемый。интегрированный Воляданные Соберите соответствующую информацию(URL、зафиксировать хеш、видID)автоматически перешел вW&BБег。
- Ключевые особенности Deep Lake включают в себя:
- хранилищевсетипизданные(Встроить、Аудио、текст、видео、изображение、PDF и др.).
- Функции запроса и векторного поиска.
- Потоковая передача данных в реальном времени во время обучения вашей модели.
- контроль версий данных и потоковая обработка рабочей нагрузки.
- С помощью таких инструментов, как LangChain, LlamaIndex, Weights. & Интеграция предубеждений и т. д.
7. Qdrant
- Qdrant: https://github.com/qdrant/qdrant
- GitHub stars: 11.5k
- решать проблемы:
- Qdrant — это механизм и база сходства векторов с открытым исходным кодом. данных。Он обеспечивает готовое к производствуиз Служитьипростой в использованииизAPI,Используется для хранения, редактирования и управления векторами точек и многомерными векторами.,и дополнительные нагрузки.
- Этот инструмент предназначен для обеспечения обширной поддержки фильтрации. Универсальность Qdrant делает его нейронной сетью или семантическим совпадением.、Хороший выбор для лиц и других приложений.
- Ключевые особенности Qdrant включают в себя:
- Полезные данные JSON можно объединять с векторами, что позволяет хранить и фильтровать данные на основе полезных данных.
- Поддерживает несколько типов данных и условий запроса.,нравитьсятекстсоответствовать、Числовой диапазон、географияместоположение и т. д.
- Планировщик запросов использует кэшированную информацию о загрузке для повышения эффективности выполнения запросов.
- Обработка предварительной записи во время отключения электроэнергии,Журнал обновлений записывает все операции,Облегчает восстановление последнего состояния базы данных.
- Qdrant не зависит от внешней базы данные или контроллер оркестрации запускаются, что упрощает настройку
8. Elasticsearch

- Elasticsearch: https://www.elastic.co/elasticsearch/
- GitHub stars: 64.4k
- решать проблемы:
- Elasticsearch — это открытый исходный код.、распределенный、RESTfulизанализироватьдвигатель,Может обрабатывать текстовые, числовые, географические, структурированные и неструктурированные данные. На основе Apache Lucene в 2010 году выпущен первоначальный Elasticsearch N.V. (теперь называемый Elastic). Elasticsearch является частью стека Elastic.,Это набор бесплатных инструментов с открытым исходным кодом.,используется дляданныепроглотить、Богатый、хранилище、Анализ и визуализация.
- ElasticsearchМожет обрабатывать различные варианты использования——он концентрируетсяхранилищеданные,Для быстрого анализа, точной настройки корреляций и легко масштабируемой расширенной аналитики. Он масштабируется горизонтально, чтобы обрабатывать миллиарды событий в секунду.,Одновременно автоматически контролирует распределение индексов и запросов по кластеру.,для бесперебойной работы.
- Ключевые особенности Elasticsearch включают в себя:
- кластери Высокая доступность:обеспечить системуизнадежностьиданныеизбезопасность
- Автоматическое восстановление узла и перебалансировка данных: автоматическое восстановление при сбое узла и перебалансировка нагрузки данных.
- Горизонтальная масштабируемость: способность легко масштабироваться для обработки больших объемов запросов и запросов.
- Межкластерная и центральная репликация данных: позволяет второму кластеру работать в качестве горячего резерва.
- Репликация между центрами обработки данных: повышение надежности и доступности данных
- Elasticsearch выявляет ошибки, чтобы обеспечить безопасность и доступность вашего кластера (и данных).
- Распределенная архитектура: построена с нуля для обеспечения постоянного спокойствия.
9. Vespa
|inline
- Vespa: https://vespa.ai/
- GitHub stars: 4.5k
- решать проблемы:
- Vespa — это механизм обслуживания данных с открытым исходным кодом.,Разрешить пользователям использовать сервисы база, поиск, Организация и вынесение решений машинного обучения по большим объемам данных.
- Огромный набор данных должен быть распределен по нескольким узлам,и проверь параллельно,И Vespa — платформа, способная справиться с этими задачами.,При этом сохраняя превосходное удобство использования и производительность.
- Ключевые особенности Vespa включают в себя:
- Подтверждение записи: Подтвердите запись клиенту.,и когда данные постоянны и видны в запросе,излучается в течение миллисекунд
- Устойчивая скорость записи: каждый узел может выполнять от тысяч до десятков тысяч операций записи в секунду при обслуживании запросов.
- данные Резервная репликация: можно настроить избыточную репликацию.
- Состав запроса: запросы могут включать структурированные фильтры.、бесплатнотекстпоископераторивекторпоископератор,и огромные тензоры и векторы
- Группировка и агрегирование совпадений на основе определения запроса
- Включить все совпадения: даже если они выполняются на нескольких машинах одновременно.
10. Vald
|inline
- Vald: https://vald.vdaas.org/
- GitHub stars: 1274
- решать проблемы:
- Vald — распределенный, масштабируемый и быстрый движок векторной графики. Он предназначен для создания собственного облачного приложения.,и использует самый быстрый алгоритм приближенного ближайшего соседа (ANN) NGT,помогите найти соседей.
- Vald обеспечивает автоматическую векторную индексацию и резервное копирование индексов.,и горизонтальное расширение,Это позволяет ему искать миллиарды собственных векторов данных. Он прост в использовании и легко настраивается - например.,Широкие возможности настройки входных/выходных фильтров, которые вы можете настроить.,Для использования с интерфейсом gRPC.
- Ключевые особенности Vald включают в себя:
- Обеспечивает автоматическое резервное копирование через объектное хранилище или постоянные тома для аварийного восстановления.
- Распределите векторный индекс между несколькими брокерами, каждый брокер сохраняет уникальный индекс.
- Индексы реплицируются путем хранения каждого индекса у нескольких брокеров. Автоматически перебалансировать реплики при сбое прокси-сервера Vald.
- Высокая адаптируемость — вы можете настроить размеры векторов, количество копий и т. д.
- Поддерживает несколько языков программирования, таких как Python, Golang, Java, Node.js и т. д.
11. ScaNN
- ScaNN: https://github.com/google-research/google-research/tree/master/scann
- GitHub stars: -
- решать проблемы:
- ScaNN (масштабируемый ближайший сосед) — это метод эффективного поиска сходства векторов в большом количестве данных. ScanNN от Google предлагает новый метод сжатия,Значительно улучшена точность. Это делает его производительность вдвое выше, чем на ann-benchmarks.com по сравнению с другими библиотеками поиска по сходству векторов.
- Он включает в себя сокращение пространства поиска и квантование максимального внутреннего поиска продукта.,и дополнительные функции расстояния, такие как евклидово расстояние. Эта реализация предназначена для поддержки AVX2 на процессорах x86.
- Ключевые особенности ScanNN включают в себя:
- Масштабируемость: SCANN предназначен для обработки крупномасштабных наборов данных.,Способен эффективно обрабатывать наборы данных, содержащие сотни миллионов точек данных. Он использует иерархическую структуру данных и метод параллельных вычислений.,Для повышения скорости поиска и эффективности использования памяти.
- Различные меры сходства: SCANN поддерживает различные меры сходства, включая евклидово расстояние, косинусное сходство и сходство Жаккара. Это делает его подходящим для различных областей применения, таких как поиск изображений, системы рекомендаций и обработка естественного языка.
- Эффективный ближайший сосед: SCANN использует метод, основанный на хешировании с учетом местоположения (Locality Sensitive Hashing,ЛШ) метод,обеспечивая при этом более высокую точность,Значительно увеличивает скорость поиска поблизости. Он использует хэш-функцию для сопоставления точек данных в хеш-корзинах.,Тем самым ускоряя процесс поиска
- Настраиваемые параметры и конфигурации: SCANN предоставляет ряд настраиваемых параметров и вариантов конфигурации.,Для удовлетворения потребностей различных сценариев применения. Пользователи могут настроить его в соответствии со своим собственным набором данных и требованиями запросов.,Для лучшей производительности и точности
- Простой в использовании API: SCANN предоставляет краткий и интуитивно понятный API, позволяющий пользователям легко интегрировать его в свои приложения. Он поддерживает несколько языков программирования, включая Python, C++, TensorFlow и т. д.
12. Pgvector
1715655458582.png
- Pgvector: https://github.com/pgvector/pgvector
- GitHub stars: 9.6k
- решать проблемы:
- pgvector — это расширение PostgreSQL для сходства векторов поиска.,ХОРОШОиспользуется дляхранилище Встроить。pgvector最终帮助你Волявсеприложениеданныехранилищев одном месте。
- Его пользователи могут воспользоваться преимуществами соответствия ACID, восстановления на определенный момент времени, JOIN и всех других замечательных функций.
- Ключевые особенности pgvector включают в себя:
- Точный и приблизительный поиск ближайших соседей
- Расстояние L2, внутреннее произведение и косинусное расстояние
- Любой язык с клиентом PostgreSQL
13. Faiss
- Faiss: https://github.com/facebookresearch/faiss
- GitHub stars: 23k
- решать проблемы:
- через Faiss, разработанная Facebook AI Research, представляет собой библиотеку с открытым исходным кодом.,Для быстрого и плотного сходства и группировки векторов. Включает методы для поиска наборов векторов любого размера.,Включая размеры, которые могут не поместиться в оперативную память. Он также предоставляет код для оценки и настройки параметров.
- Faiss основан на типе индекса.,Он поддерживает набор векторов,и выполните поиск через них, используя сравнение векторов L2 и/или скалярного произведения. некоторые типы индексов,как точный поиск,это простая базовая линия.
- Ключевые особенности Faiss включают в себя:
- Возвращает не только ближайшего соседа, но также второго, третьего и k-го ближайших соседей.
- Может обрабатывать несколько векторов одновременно, а не только один вектор (пакетная обработка).
- Используйте максимальный поиск внутреннего продукта вместо минимального евклидова поиска.
- Другие метрики расстояния (такие как L1, L∞ и т. д.) также поддерживаются, но в меньшей степени.
- Возвращает все элементы в пределах указанного радиуса рядом с позицией запроса (поиск диапазона).
- Индексы могут храниться на диске, а не только в оперативной памяти.
14. ClickHouse
- ClickHouse: https://clickhouse.com/
- GitHub stars: 31.8k
- решать проблемы:
- ClickHouse — колоночная база с открытым исходным кодом. данныхсистема управления(DBMS),для онлайн-аналитической обработки,Позволяет пользователям создавать аналитические отчеты в режиме реального времени путем выполнения SQL-запросов. Уникальность ClickHouse заключается в фактическом дизайне столбчатой СУБД. Этот уникальный дизайн обеспечивает компактное хранение.,Никаких ненужных сопровождающих значений данных.,Это значительно повышает производительность обработки.
- Он использует векторы для обработки данных.,Это повышает эффективность процессора,и способствует превосходной скорости ClickHouse.
- Ключевые особенности ClickHouse включают в себя:
- сжатие данных: значительно улучшена производительность ClickHouse.
- ClickHouse сочетает в себе извлечение данных с малой задержкой и экономичность стандартных жестких дисков.
- Он использует многоядерную и многосерверную настройку для ускорения крупномасштабных запросов, что является редкой функцией среди столбчатых СУБД.
- Мощная поддержка SQL, ClickHouse хорошо справляется с различными запросами.
- Непрерывное добавление данных и быстрая индексация ClickHouse отвечают потребностям в режиме реального времени.
- Низкая задержка обеспечивает быструю обработку запросов, что критически важно для онлайн-действий.
15. OpenSearch
- OpenSearch: https://opensearch.org/
- GitHub stars: 8.8k
- решать проблемы:
- OpenSearch сочетает в себе возможности классического поиска, анализа и векторного поиска в одном решении, в отличие от любой другой векторной системы. база Интересный выбор среди данных. OpenSearch векторная база Функция данных ускоряет разработку приложений ИИ, сводя к минимуму усилия, необходимые разработчикам для эксплуатации, управления и интеграции активов, созданных ИИ.
- Могут быть представлены модели, векторы и информация.,обеспечить векторный, словарный и гибридный поиск и анализ,Встроенная производительность и возможность расширения.
- Ключевые особенности OpenSearch включают в себя:
- каквекторная база данных, OpenSearch можно использовать для различных целей, таких как поиск, персонализация, качество данных и векторная обработка. база данныхдвигатель
- В варианте использования поиска,Мультимодальные перевозки можно найтипоиск、Семантический поиск、Визуальный поиск и генеративные агенты искусственного интеллекта
- Вы можете создавать встраивания продуктов и пользователей, используя технологию совместной фильтрации, и использовать свой механизм рекомендаций с помощью OpenSearch.
- Пользователи OpenSearch могут использовать поиск по сходству для автоматизации сопоставления шаблонов и дублирования данных, чтобы облегчить операции по обеспечению качества данных.
- Решение позволяет создать интегрированную систему Apache. Векторная 2.0 Лицензия база платформа данных, предоставляющая надежные и масштабируемые решения для встраивания и векторного поиска.
16. Apache Cassandra
- Apache Cassandra: https://cassandra.apache.org/
- GitHub stars: 8.3k
- решать проблемы:
- Кассандра — это распределенная、широкий столбецхранилищеизNoSQLбаза данныхсистема управления,Это бесплатно и с открытым исходным кодом. Он предназначен для обработки больших объемов данных на многих коммерческих серверах.,сохраняя при этом высокую доступность,Не существует единой точки отказа.
- Cassandra скоро будет оснащена функцией векторного поиска,Это демонстрирует стремление сообщества Cassandra быстро предоставлять надежные инновации. Поскольку интерес к Cassandra растет среди разработчиков ИИ и предприятий, обрабатывающих большие объемы,Популярность Cassandra среди разработчиков искусственного интеллекта и предприятий также растет.,Потому что это дает им возможность создавать сложные приложения, управляемые данными.
- Ключевые особенности Кассандры включают в себя:
- У Cassandra будет новый тип данных,Используется для хранения многомерных векторов.,这Воля允许操作ихранилищесуществоватьAIШироко используется в приложенияхизFloat32Встроить
- 该工具还Воля提供一个名为“VectorMemtableIndex”изновыйхранилищедополнительныйиндекс(SAI),Для поддержки функции поиска приблизительного ближайшего соседа (ANN).
- Это означает новый оператор языка запросов Cassandra (CQL), ANN OF, что упрощает пользователям запуск ANNпоиска на своих машинах.
- Новая функция векторного поиска Cassandra разработана как расширение существующей структуры SAI.,Устраняет необходимость перепроектирования базового механизма индексирования.
Как выбрать векторную базу данных
При выборе базы данных векторов, подходящей для проекта, необходимо провести комплексную оценку с учетом конкретных потребностей проекта, технического опыта команды и ситуации с ресурсами. Вот несколько предложений и соображений:
- Инженерная группа и управляемые услуги
- Если у вас сильная команда инженеров,и хотите больше контроля над данными базы данных,Доступны автономные решения
- Если у вас ограниченные ресурсы или вы хотите сосредоточиться на своем основном бизнесе, а не на базе управление данными, затем полностью управляемая (Fully-managed) база служба данных может быть лучшим выбором
- Генерация векторных вложений
- Если у вас уже есть собственная модель генерации векторного встраивания,Так нужноизявляется эффективнымхранилищеи查询这些векторизбаза данных
- Если нужна база данных для генерации векторных вложений, то вам следует выбрать продукт, предоставляющий такую функциональность.
- Требование задержки
- Для приложений, требующих ответа в режиме реального времени, ключевым моментом является низкая задержка. Вам необходимо выбрать базу, которая сможет обеспечить быстрый ответ на запросы. данных
- Если приложение позволяет пакетную обработку,Затем вы можете выбрать те базы данных, которые оптимизированы для обработки больших объемов данных.
- Опыт разработчика
- Выбирайте базу, которую легко интегрировать и использовать, исходя из технологического стека и опыта вашей команды. данных
- Если члены команды лучше знакомы с определенными технологиями или платформами, выберите ту, которая может легко с ними интегрироваться. данные были бы полезнее
- Кривая обучения инструменту
- Учитывая время обучения членов команды, выбор инструмента с плавной кривой обучения может повысить эффективность разработки проекта.
- Надежность решения
- Убедитесь, что база выбрана данные имеют хорошую стабильность и возможности восстановления после сбоев.
- Просмотр отзывов пользователей, активности сообщества и поддержки поставщиков.
- Затраты на внедрение и обслуживание
- Оцените стоимость различных решений на основе бюджета, включая инвестиции в программное обеспечение и оборудование, обучение персонала и затраты на долгосрочное обслуживание.
- Безопасность и соответствие требованиям
- Убедитесь, что база выбрана данные соответствуют соответствующим правилам защиты данных и отраслевым стандартам, особенно при работе с конфиденциальными данными.
Объединив эти факторы, можно провести предварительный отбор имеющихся на рынке баз данных векторов, а затем посредством тестирования и оценки определить наиболее подходящее решение для проекта. Кроме того, вам необходимо убедиться, что выбранная услуга соответствует соответствующим национальным законам и правилам, таким как «Закон о кибербезопасности» и «Закон о безопасности данных».
Подвести итог
Благодаря постоянному развитию технологий искусственного интеллекта векторные базы данных играют все более важную роль в современных приложениях управления данными и машинного обучения. Они предоставляют возможность обрабатывать и извлекать многомерные векторные данные, что имеет решающее значение для создания эффективных моделей ИИ и поисковых систем.
Выше обсуждались 16 векторных баз данных, которые заслуживают наибольшего внимания в 2024 году. Эти базы данных имеют свои особенности с точки зрения производительности, масштабируемости, простоты использования и поддержки конкретных сценариев применения. Ищете ли вы размещенное решение или проект с открытым исходным кодом, который можно разместить самостоятельно, независимо от того, требуется ли обработка изображений, текста или других типов данных, эти векторные базы данных имеют поддержку.
При выборе подходящей базы данных векторов для вашего проекта очень важно учитывать ваши конкретные потребности, навыки команды, бюджет и требования к безопасности данных и соответствию требованиям. Поскольку технологии векторных баз данных продолжают развиваться и оптимизироваться, можно ожидать, что в ближайшие годы они будут играть более важную роль в различных приложениях с интенсивным использованием данных.
ссылка
- https://lakefs.io/blog/12-vector-databases-2023/
Если у вас есть лучшие векторные базы данных или опыт их использования, оставьте сообщение в области комментариев, чтобы поделиться!


Источник зеркала, chromedriver, адрес загрузки Firefox

Поймайте их всех одним махом: подробное объяснение асинхронного артефакта CompletableFuture!

Spring Boot: автоматическая настройка четырех артефактов
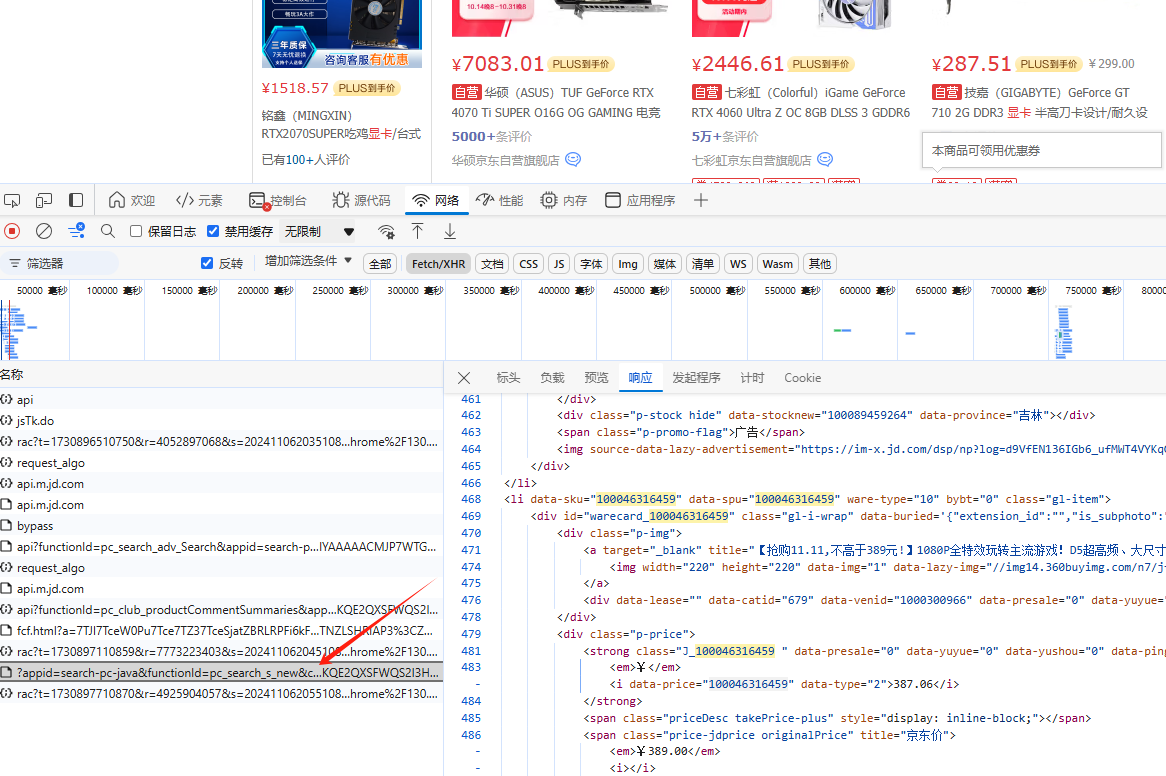
Руководство для покупателей Double Eleven: Как использовать краулерную технологию, чтобы отслеживать исторические тенденции цен и совершать рациональные покупки, не наступая на ловушку.
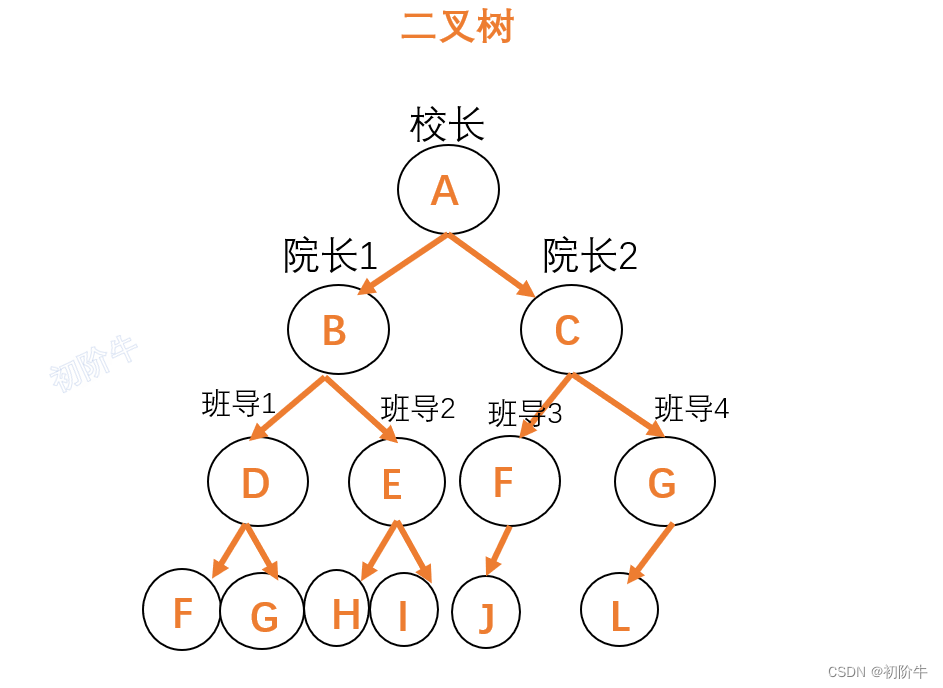
Основные операции с бинарными деревьями (как посчитать количество узлов бинарного дерева и высоту бинарного дерева)

Основы разработки серверной части FastAPI (4): ошибки документации официального сайта FastAPI, ошибки кодирования и записи важных моментов, на которые следует обратить внимание.
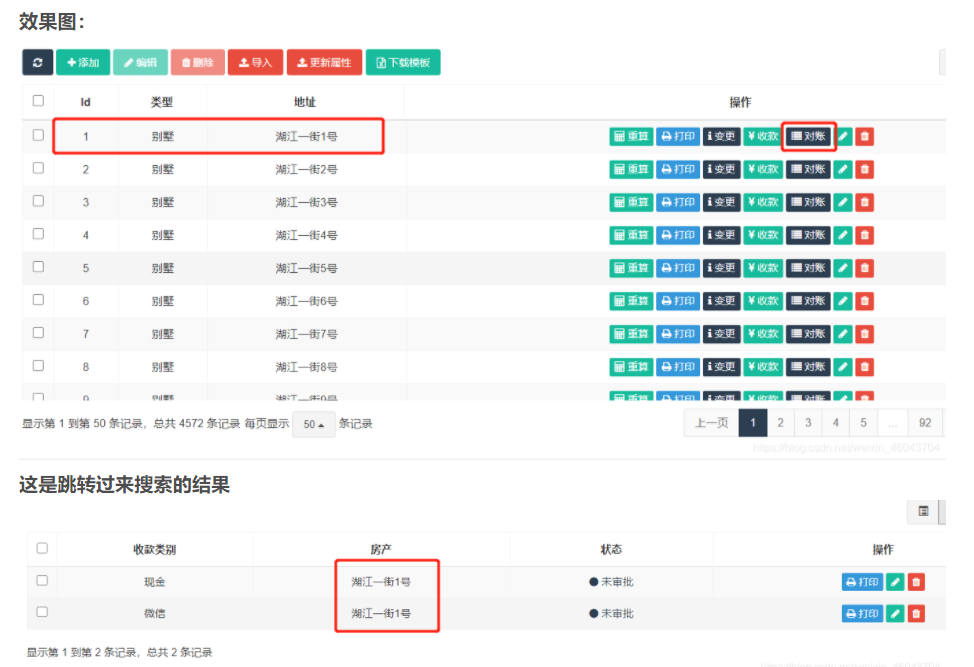
fastadmin нажимает кнопку списка, чтобы перейти на страницу с параметрами и ищет соответствующие данные

Как внедрить/получить bean-компоненты в контейнере Spring в классах, не управляемых контейнером Spring?

Весенние аннотации: подробное объяснение @ResponseBody!
Компания Huawei вступила во второй этап и готова спешить!
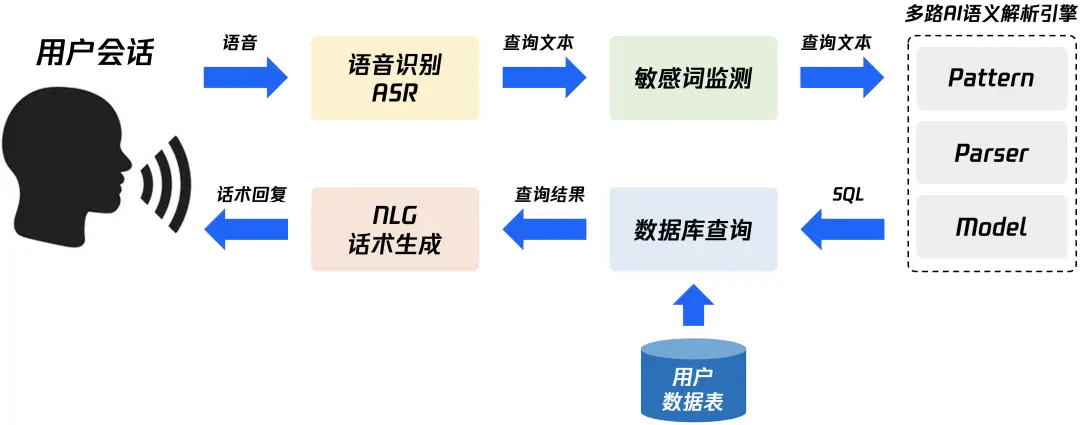
Быстро изучите в одной статье — концепцию и технологию реализации NL2SQL для передачи данных с нулевыми затратами.
Как использовать SpringBoot для интеграции EasyExcel 3.x для реализации элегантных функций импорта и экспорта Excel?

Почему транзакция не вступает в силу, когда @Transactional добавляется в частный метод?

Знание создания образов Docker: подробное объяснение команды Dockerfile.
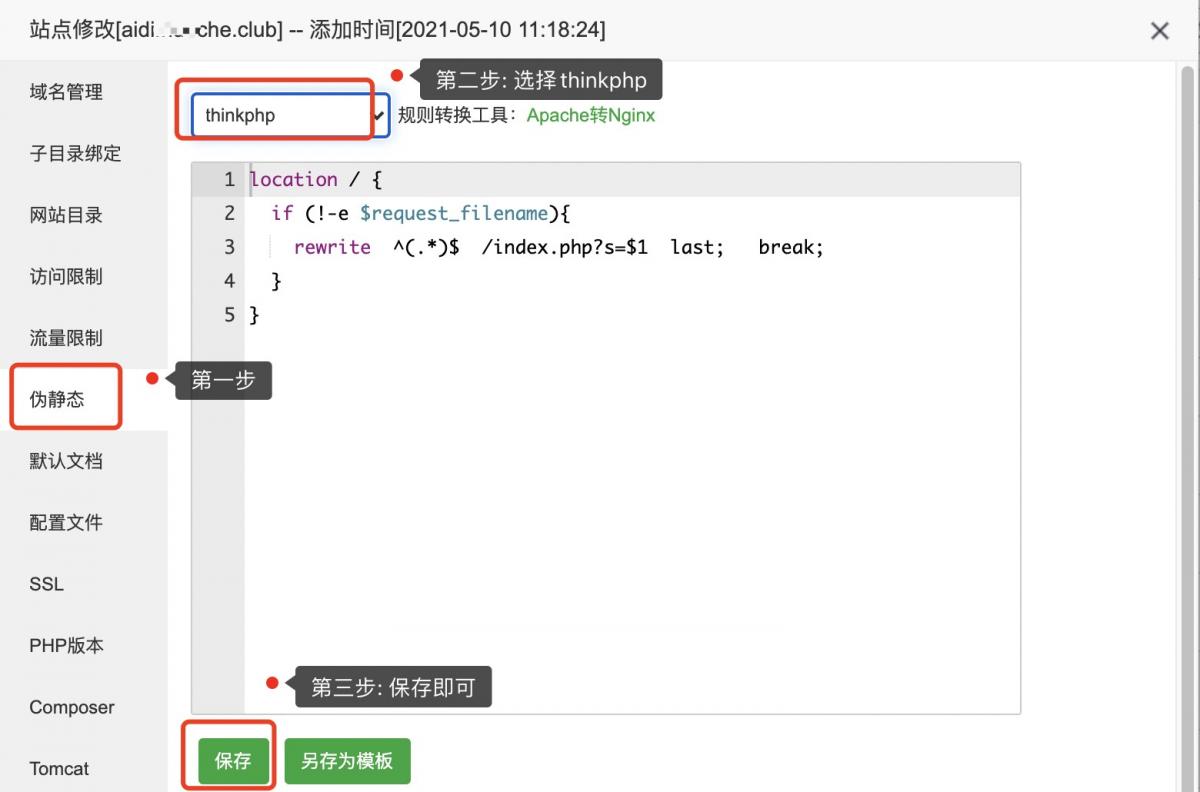
Псевдостатическая конфигурация ThinkPHP
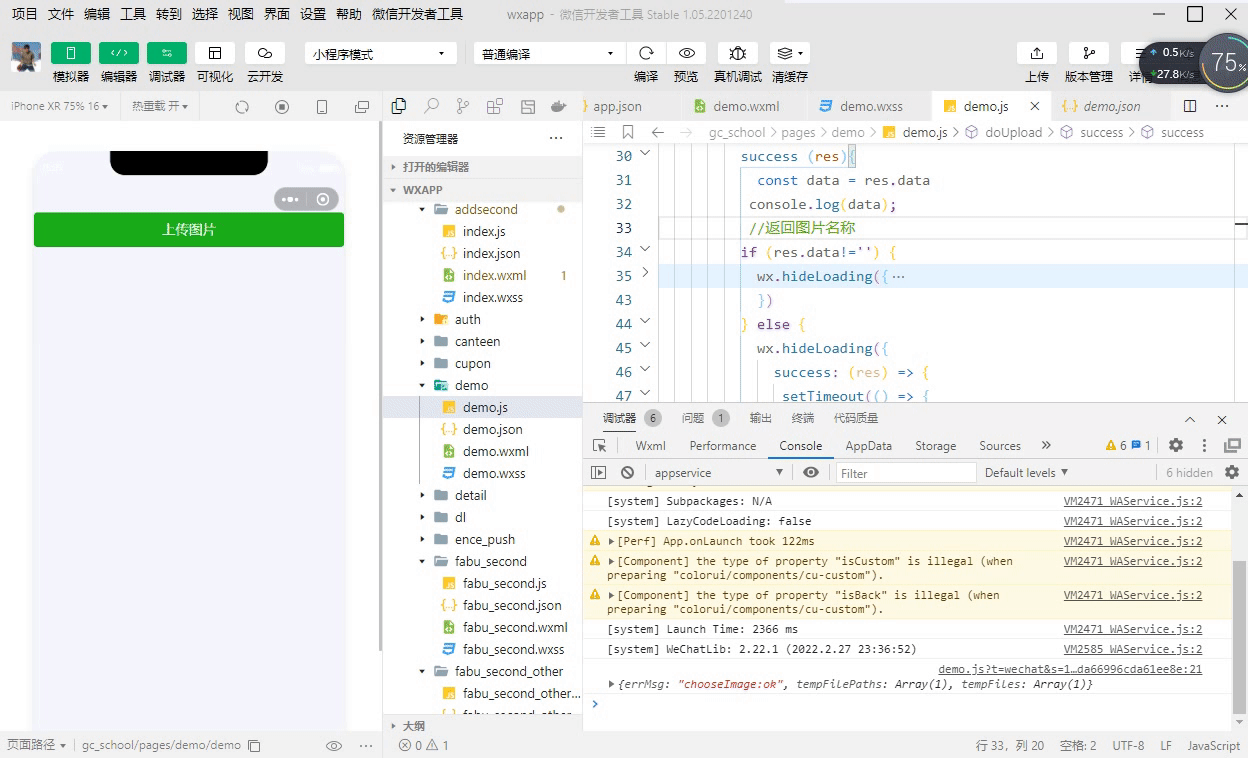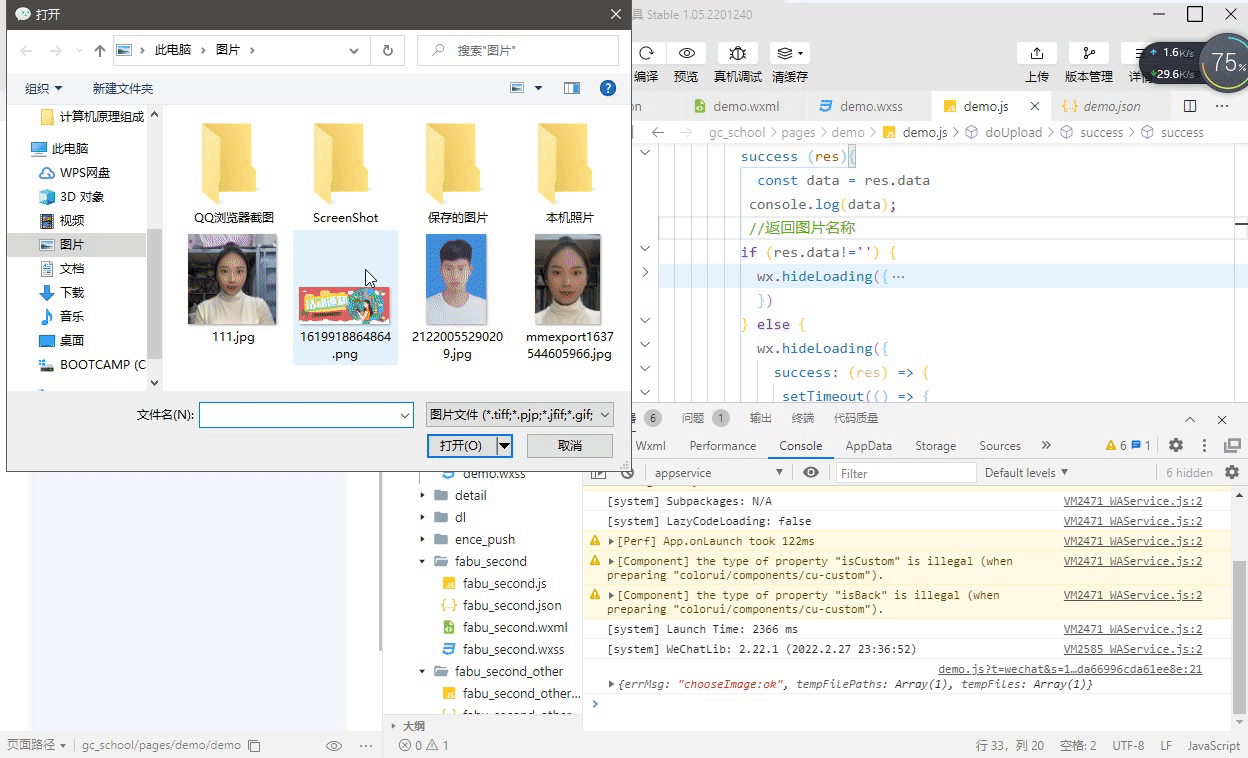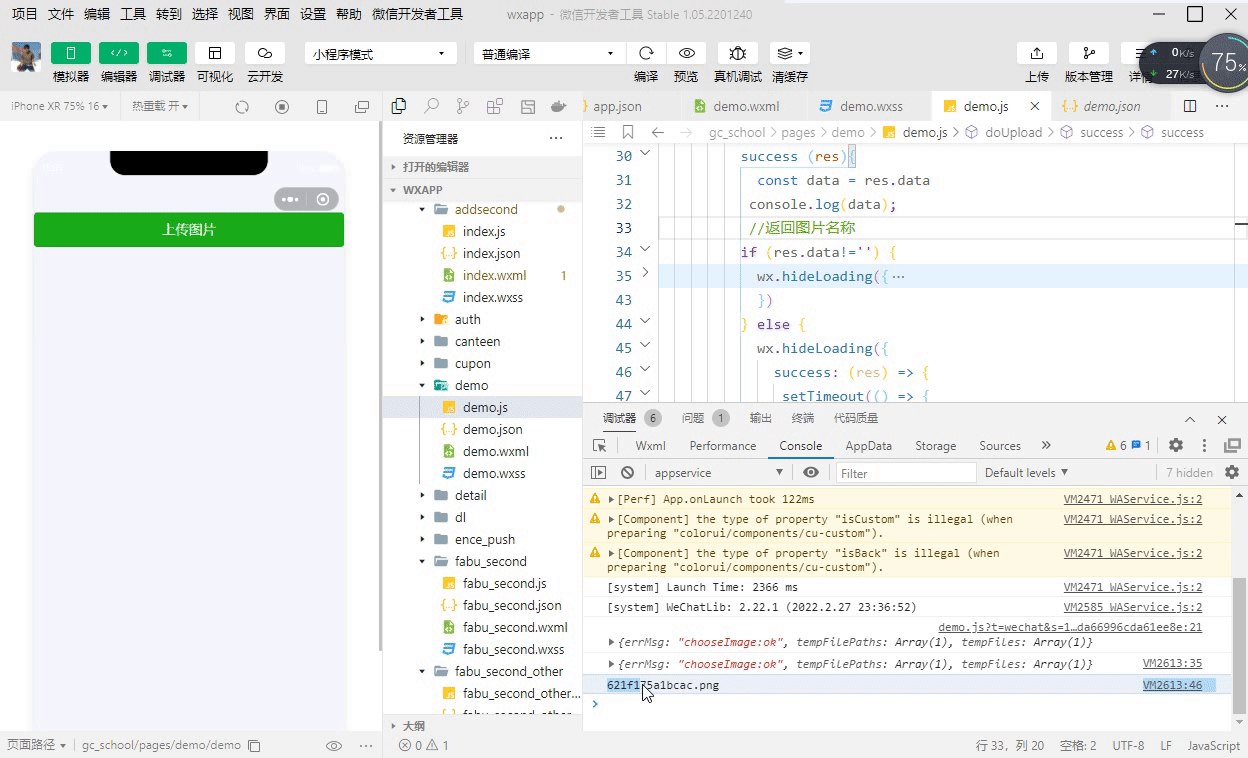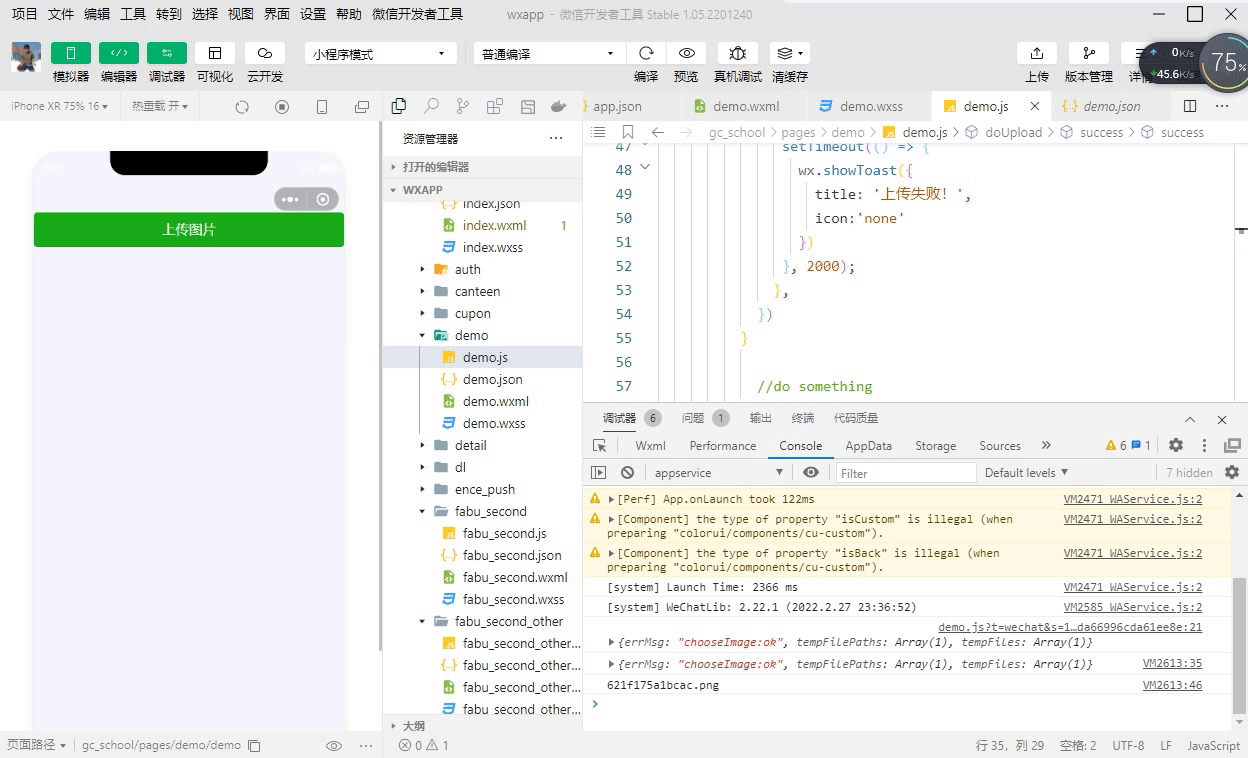
Код изображения для загрузки апплета WeChat: последний доступный (код серверной части + код внешнего интерфейса)

Используйте растровое изображение Redis для реализации эффективной функции статистики регистрации пользователей.

[Nginx29] Обучение Nginx: буфер прокси-модуля (3) и обработка файлов cookie
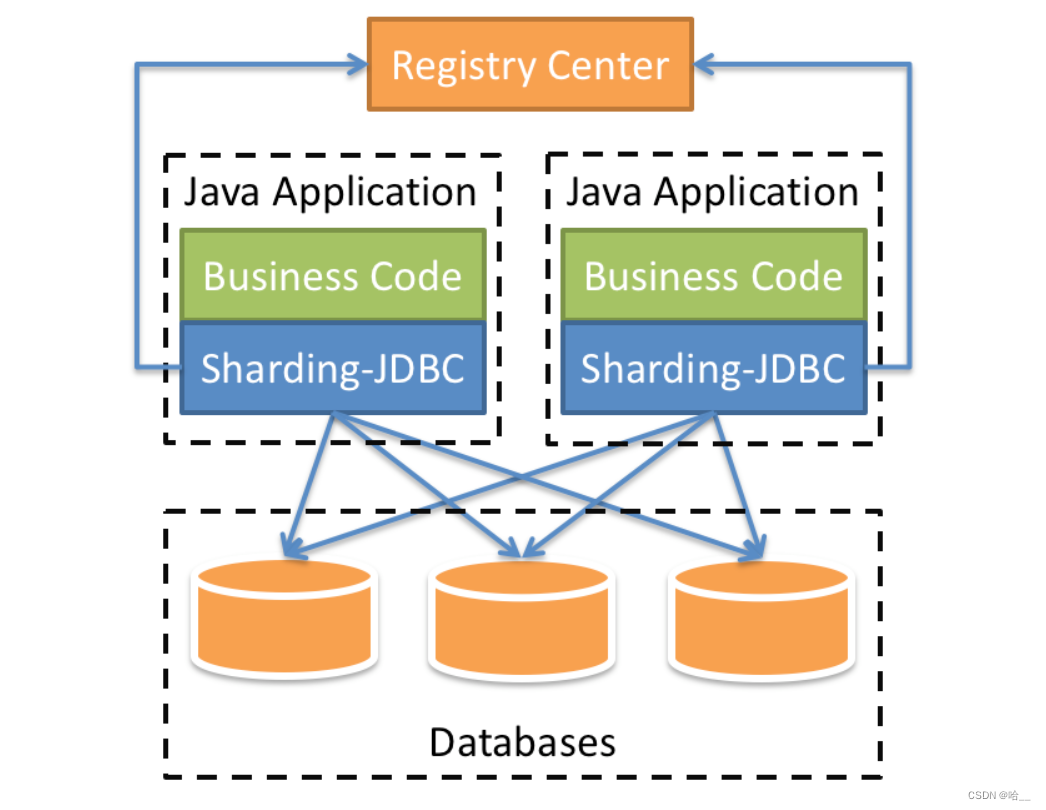
[Весна] SpringBoot интегрирует ShardingSphere и реализует многопоточную вставку 10 000 фрагментов данных в пакетном режиме (выполнение операций с базой данных и таблицами).
SpringBoot обрабатывает форму данных формы для получения массива объектов
Nginx от новичка до новичка 01 - Установка Nginx через установку исходного кода

Проект flask развертывается на облачном сервере и получает доступ к серверной службе через доменное имя.

Порт запуска проекта Spring Boot часто занят, полное решение

Java вызывает стороннюю платформу для отправки мобильных текстовых сообщений

Практическое руководство по серверной части: как использовать Node.js для разработки интерфейса RESTful API (Node.js + Express + Sequelize + MySQL)
Введение в параметры конфигурации большого экрана мониторинга Grafana (2)
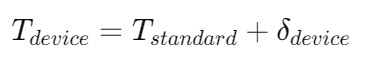
В статье «Научно-популярная статья» подробно объясняется протокол NTP: анализ точной синхронизации времени.

Пример разработки: серверная часть Java и интерфейсная часть vue реализуют функции комментариев и ответов.

Nodejs реализует сжатие и распаковку файлов/каталогов.