15 лучших бесплатных систем мониторинга с открытым исходным кодом
Отслеживая и контролируя производительность сервера, сетевой трафик, производительность приложений и взаимодействие с пользователем, он может помочь нам лучше понять рабочее состояние всей ИТ-среды и обеспечить поддержку работы, обслуживания и настройки системы. Освоение некоторых хороших инструментов мониторинга может предоставить нам лучшее решение для лучшего отслеживания состояния сервера и постоянной оптимизации системы.
В этой статье в основном перечислены некоторые из лучших бесплатных инструментов мониторинга системы с открытым исходным кодом, используемых в настоящее время.
01
Nagios
https://www.nagios.org/
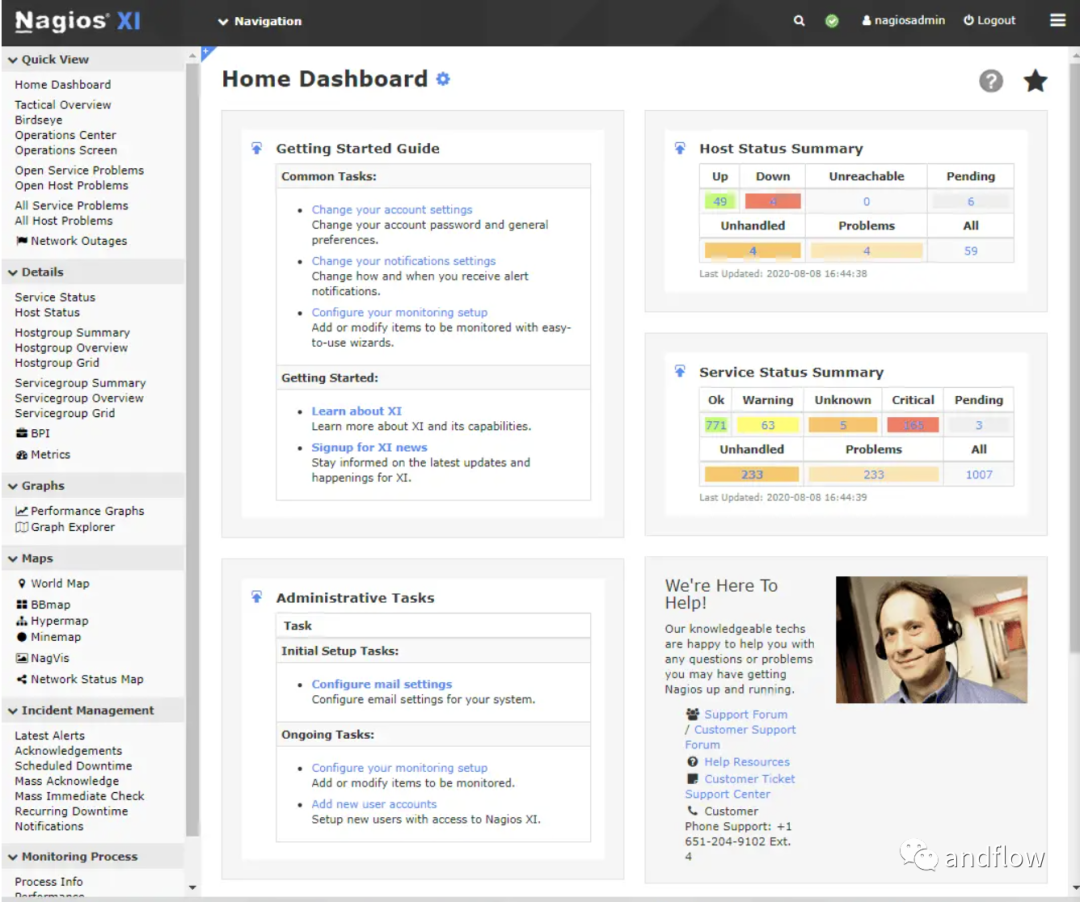
Nagios — мощный инструмент с открытым исходным кодом для мониторинга систем, сетей и инфраструктуры. Это дедушка инструментов мониторинга, появившийся в 1999 году. Этот мощный инструмент с открытым исходным кодом обеспечивает мониторинг систем, сетей и инфраструктуры. Nagios может постоянно контролировать сервер, отслеживать потенциальные проблемы на сервере и оперативно предупреждать обслуживающий и обслуживающий персонал, прежде чем потенциальные проблемы перерастут в серьезные проблемы. Основным преимуществом Nagios является его расширяемая библиотека плагинов, а возможности персонализации библиотеки плагинов Nagios могут значительно расширить функциональность инструмента. Однако кривая обучения Nagios довольно крутая, что может быть недостатком для новичков.
02
Zabbix
https://www.zabbix.com
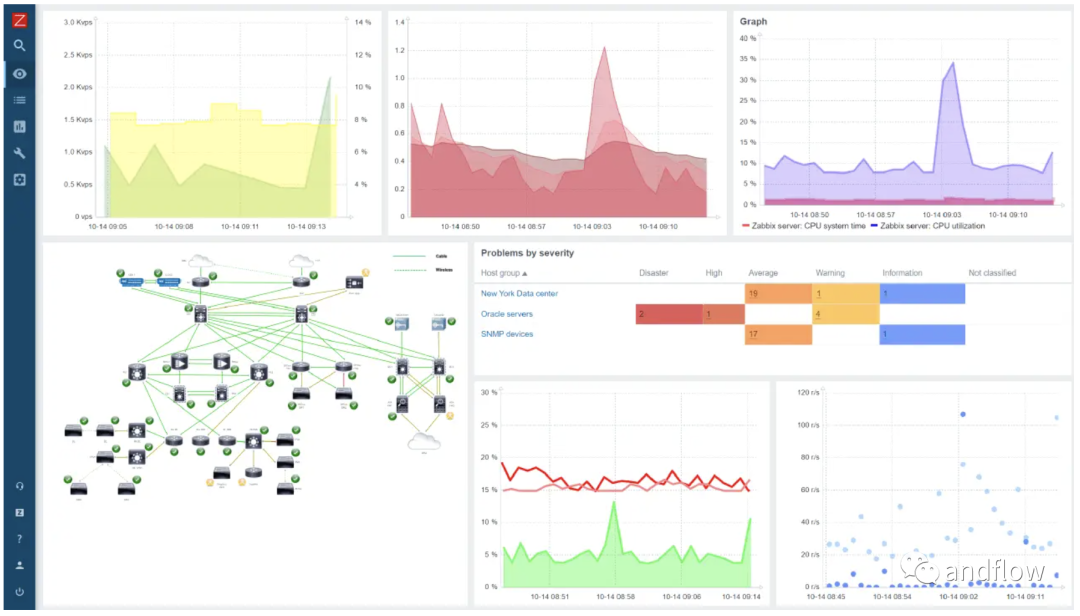
Zabbix — еще одно популярное решение для мониторинга с открытым исходным кодом, которое можно использовать для мониторинга сетей, серверов, приложений и многого другого. Этот мощный инструмент позволяет эффективно управлять сложными сетями, предоставляя операторам подробную информацию и контроль над производительностью всей инфраструктуры. Хотя весь интерфейс Zabbix недостаточно лаконичен, мощную функцию шаблонов Zabbix можно использовать для упрощения всей настройки мониторинга.
03
Prometheus
https://prometheus.io/
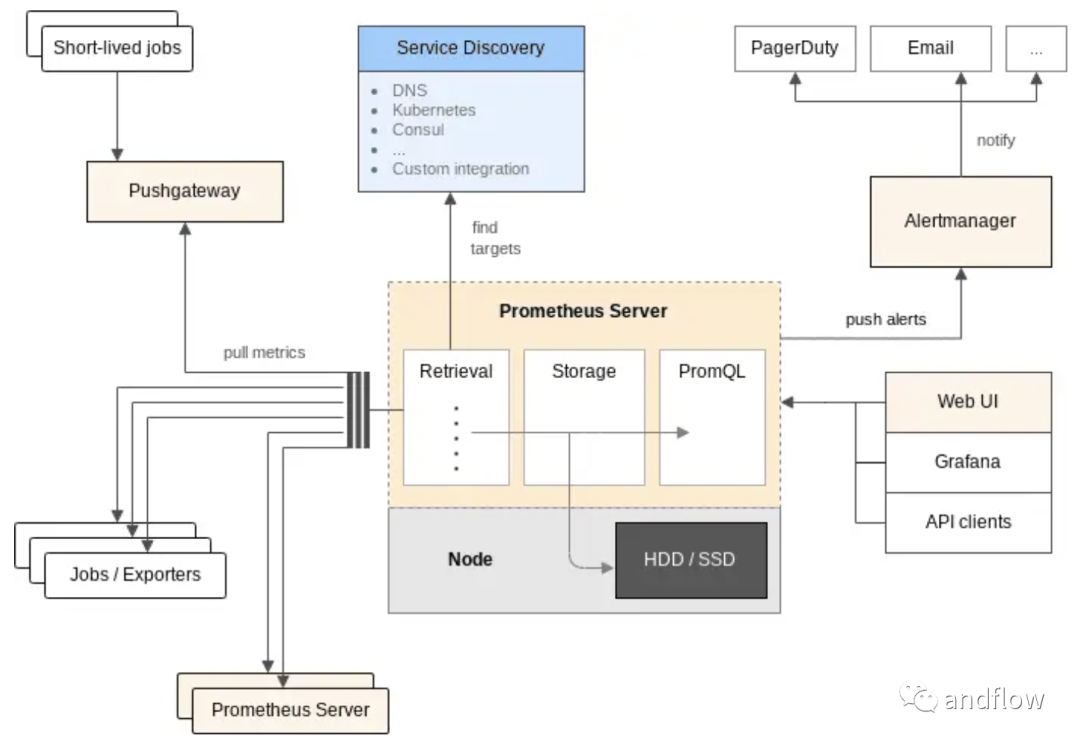
Prometheus — это система мониторинга с открытым исходным кодом, основанная на базе данных временных рядов, специально разработанная для мониторинга крупномасштабных микросервисов и контейнеров. Он особенно подходит для сбора различных показателей работы и предоставления отчетов в среде Kubernetes. Этот инструмент является фаворитом для облачных систем.
Кроме того, возможности визуализации Prometheus можно улучшить за счет интеграции Grafana.
04
Grafana
https://grafana.com/
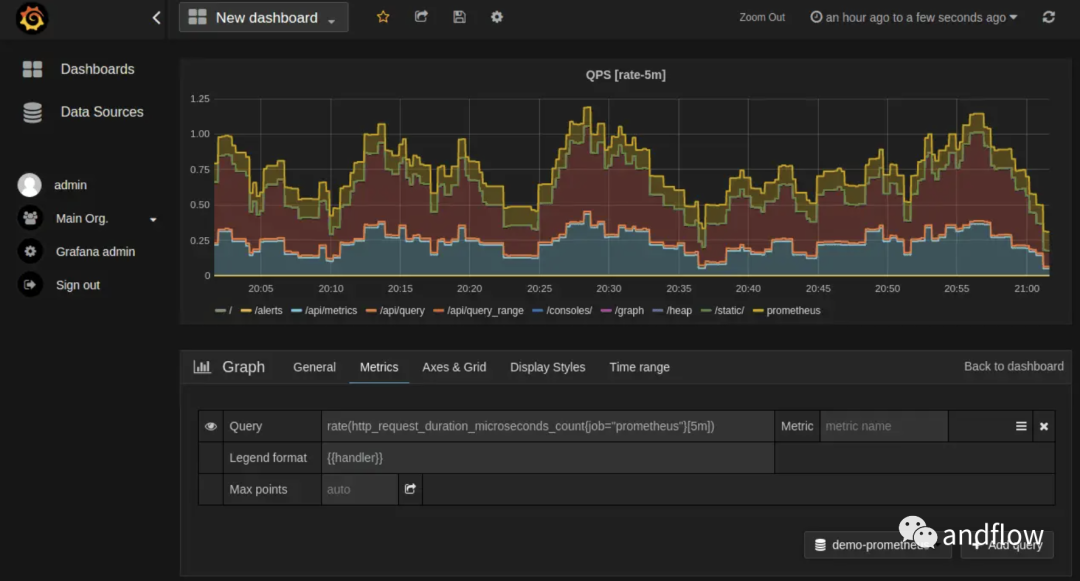
Grafana — это платформа с открытым исходным кодом, которая поддерживает несколько платформ, может анализироваться и визуализироваться и часто используется в сочетании с такими инструментами мониторинга, как Prometheus. Он поддерживает создание красивых и интуитивно понятных информационных панелей на основе данных мониторинга.
Grafana может преобразовывать данные мониторинга, такие как время отклика сервера приложений, параллелизм, показатели ЦП и показатели памяти, в визуальные диаграммы, что упрощает для персонала по эксплуатации и техническому обслуживанию понимание операционных тенденций или системных проблем.
05
Netdata
https://www.netdata.cloud/
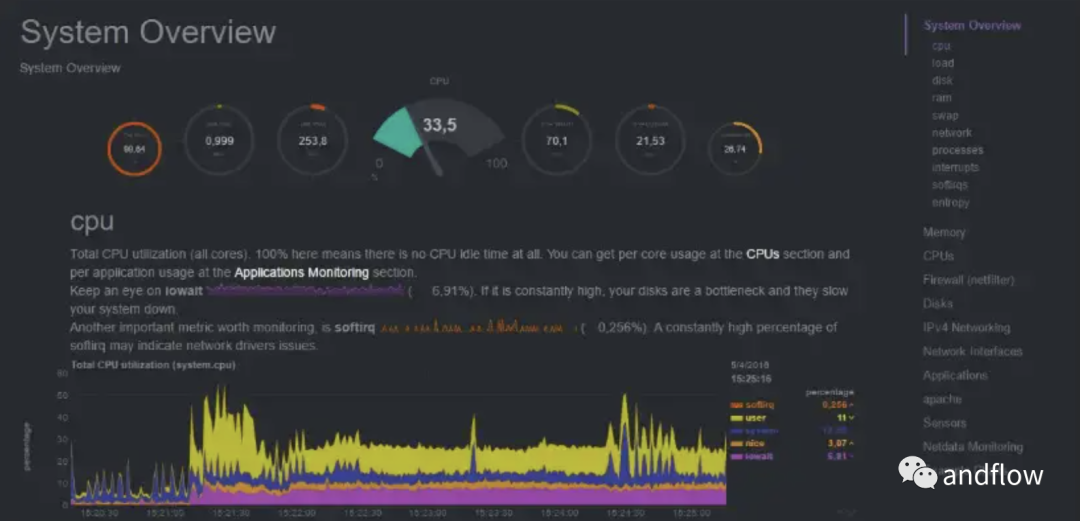
Netdata — это легкий инструмент мониторинга с открытым исходным кодом для мониторинга производительности и состояния систем и приложений в режиме реального времени. Он может работать в различных системах, а его интерфейсная веб-страница также очень проста в использовании.
Netdata может предоставить анализ дискового ввода-вывода сервера, использования процессора, оперативной памяти и пропускной способности сети.
06
ELK Stack

ELK Stack — это набор инструментов для анализа структурированных и неструктурированных данных. ELK Stack объединяет три инструмента с открытым исходным кодом: Elasticsearch, Logstash и Kibana, которые могут выполнять поиск и анализ в режиме реального времени большинства типов структурированных и неструктурированных данных, а также предоставлять аналитические отчеты. В настоящее время он широко используется для журнала операций системы и анализа данных о событиях.
В архитектуре микросервисов ELK Stack может собирать журналы каждого микросервиса, анализировать данные и представлять их в простой для понимания форме. Однако общая работа ELK потребляет ресурсы, поэтому рекомендуется регулярно настраивать конфигурацию ELK, чтобы избежать бесполезной траты ресурсов.
07
Icinga
https://icinga.com/
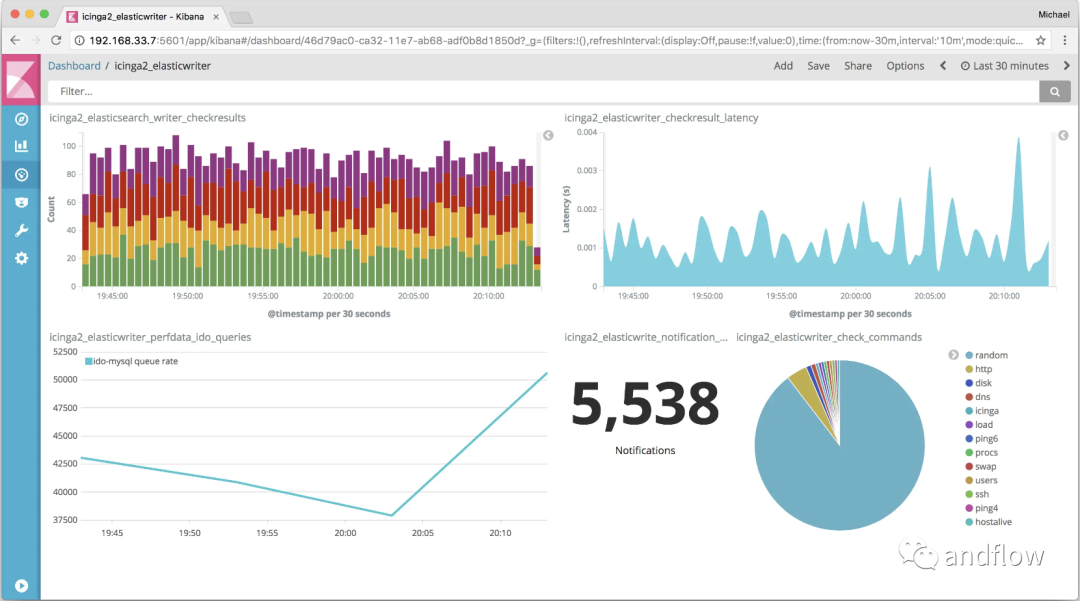
Icinga — это система мониторинга сети с открытым исходным кодом, которая может проверять доступность сетевых ресурсов, своевременно уведомлять пользователей о сбоях в сети и генерировать отчеты о производительности на основе данных. Этот инструмент обладает хорошей масштабируемостью и расширяемостью, что делает его идеальным для больших и сложных сред.
В большой сетевой среде IoT-устройств Icinga может отслеживать каждое устройство, чтобы убедиться, что оно подключено к сети и работает правильно. Но настройка Icinga может быть немного сложной, и начинающим пользователям придется потратить некоторое время.
08
Cacti
https://www.cacti.net/
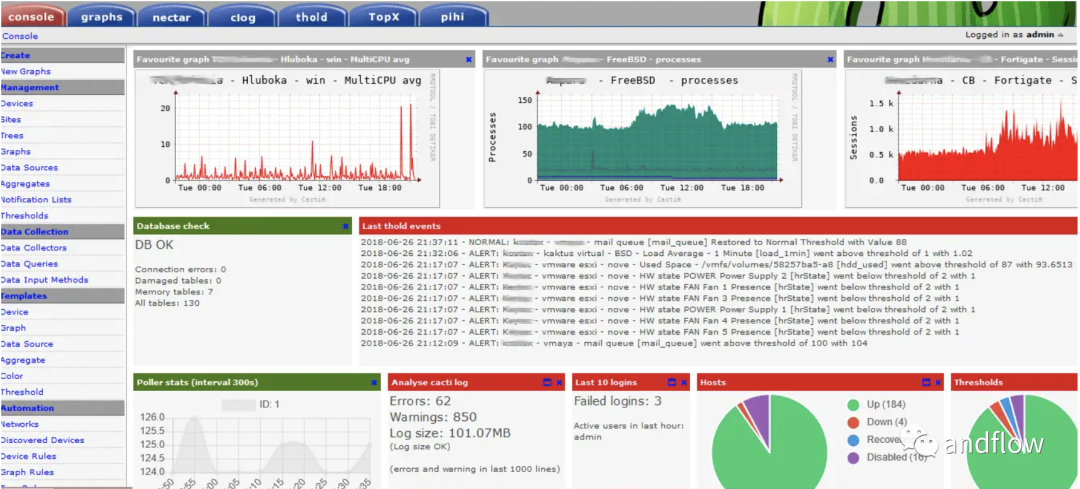
Cacti — это веб-инструмент мониторинга сети, который использует RRDTool для хранения и отображения сетевой статистики. Он предоставляет быстрый опрос, расширенные графические шаблоны и различные методы сбора данных.
Если в сети много типов устройств, SNMP Cacti поддерживает извлечение индикаторов от различных сетевых устройств и отображение информации об индикаторах в виде простой для понимания графики. Но главный недостаток Cacti заключается в том, что пользовательский интерфейс не очень интуитивно понятен.
09
OpenNMS
https://www.opennms.com/
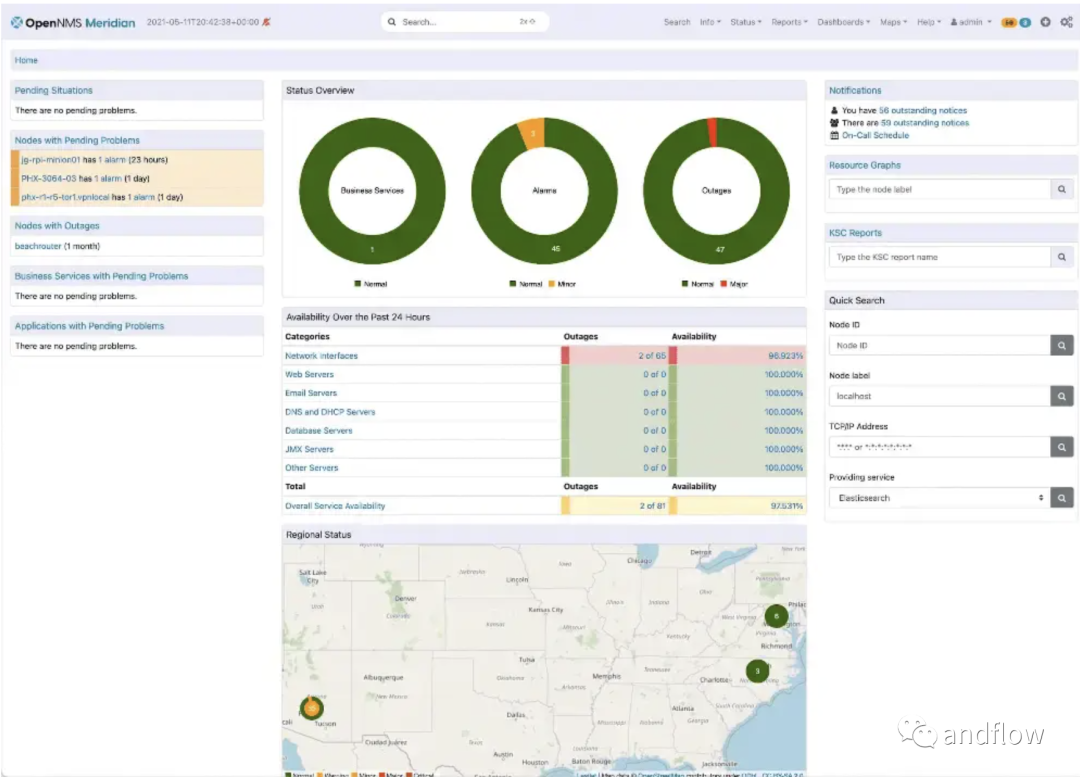
OpenNMS — это приложение для управления сетью с открытым исходным кодом, которое предоставляет такие функции, как автоматическое обнаружение, управление событиями, управление уведомлениями, обнаружение производительности и обеспечение обслуживания. Например, OpenNMS может контролировать оборудование базовой сети и предупреждать о таких проблемах, как соединения с высокой задержкой или неисправное оборудование.
10
Collectd
https://github.com/collectd/collectd
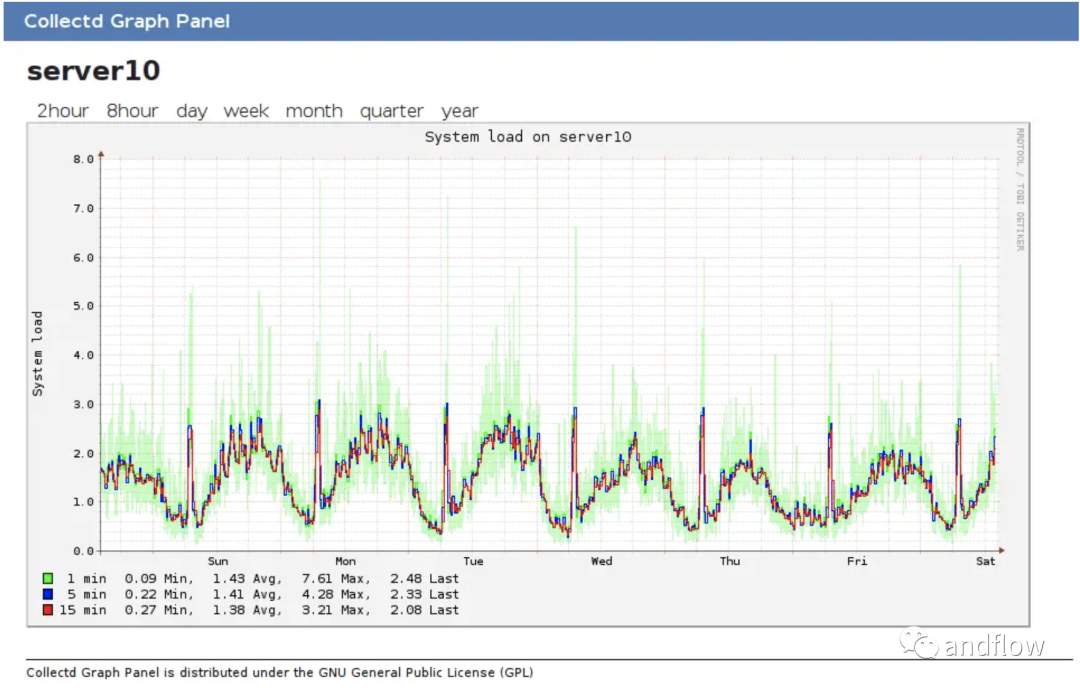
Collectd — это исполняемый демон, который периодически собирает показатели производительности системы и приложений и сохраняет эти значения. Этот инструмент очень легкий и может работать практически в любой системе.
Например, Collectd можно использовать для мониторинга небольшой домашней сети и сбора данных о задержке сети, использовании полосы пропускания и состоянии устройства. Объедините Collectd с инструментами визуализации, такими как Grafana, для более полного решения для мониторинга.
11
Sensu
https://github.com/sensu
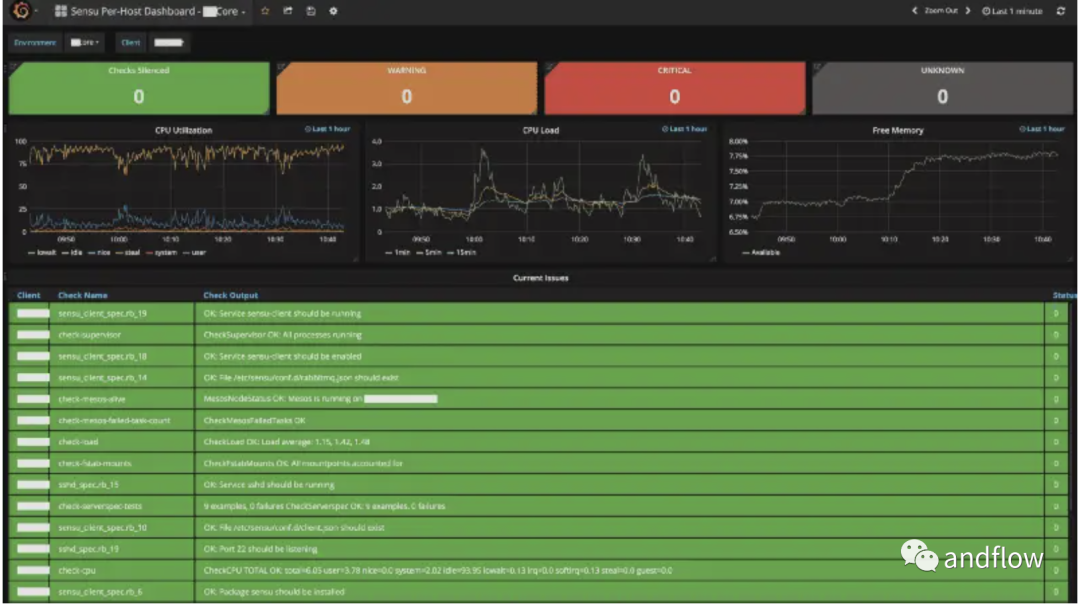
Sensu — это конвейер событий мониторинга с открытым исходным кодом, который обеспечивает автоматизированный рабочий процесс мониторинга. Мощную платформу Sensu можно использовать в различных реализациях небольших и крупных облачных инфраструктур для наблюдения, автоматизации и контроля. Особенно подходит для использования в облачной инфраструктуре.
Например, в большой облачной среде с множеством различных сервисов Sensu может не только отслеживать состояние этих сервисов, но и автоматически реагировать на такие события, как сбои автоматического перезапуска и другие сервисы.
12
InfluxDB
https://github.com/influxdata/influxdb
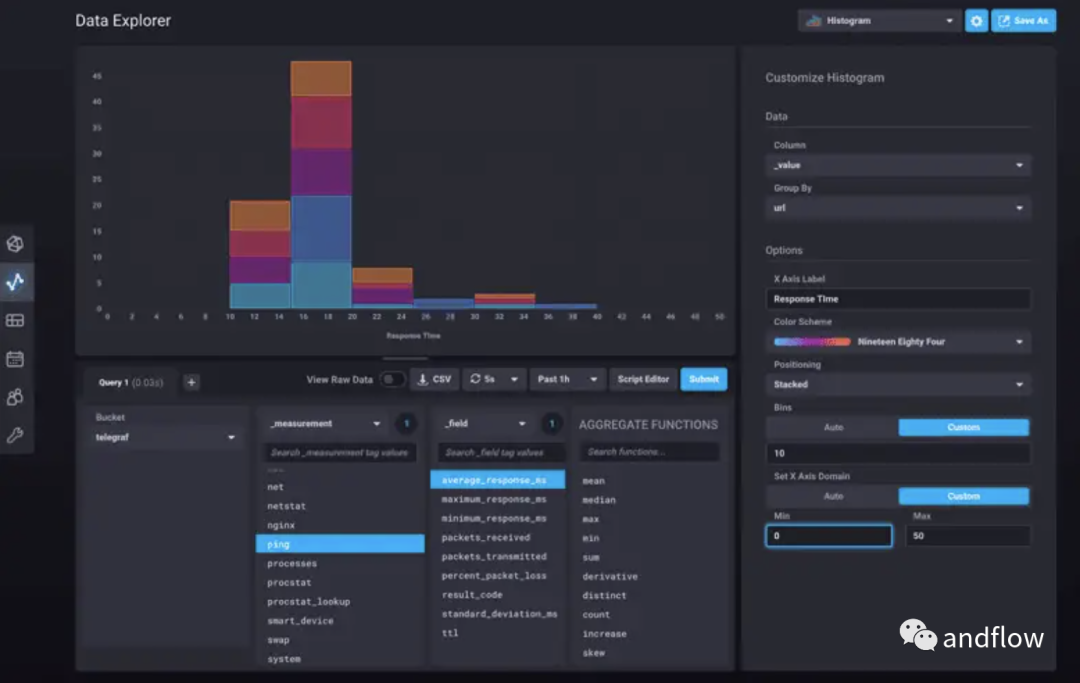
InfluxDB на самом деле представляет собой базу данных временных рядов, которая может обрабатывать большие нагрузки на запись и запросы. Она предназначена для хранения больших объемов данных с метками времени. Ее высокопроизводительная структура может обрабатывать большие объемы операций записи и запросов, а также поддерживает хранение и анализ данных. относительно длительный период. Тенденция данных во времени.
Таким образом, InfluxDB может быть идеальным для мониторинга приложений, аналитики в реальном времени и многого другого.
Например, если мы хотим отслеживать активность пользователей на веб-сайте, InfluxDB может хранить соответствующие показатели, включая рейтинг кликов, показатель отказов и время пребывания. Это дает нам полное представление о поведении пользователей с течением времени.
кроме того,Поскольку InfluxDB по сути является библиотекой данных.,Для облегчения анализа,Может использоваться сGrafanaреализовано вместеВизуализация данных наблюдения。
13
Fluentd
https://github.com/fluent/fluentd
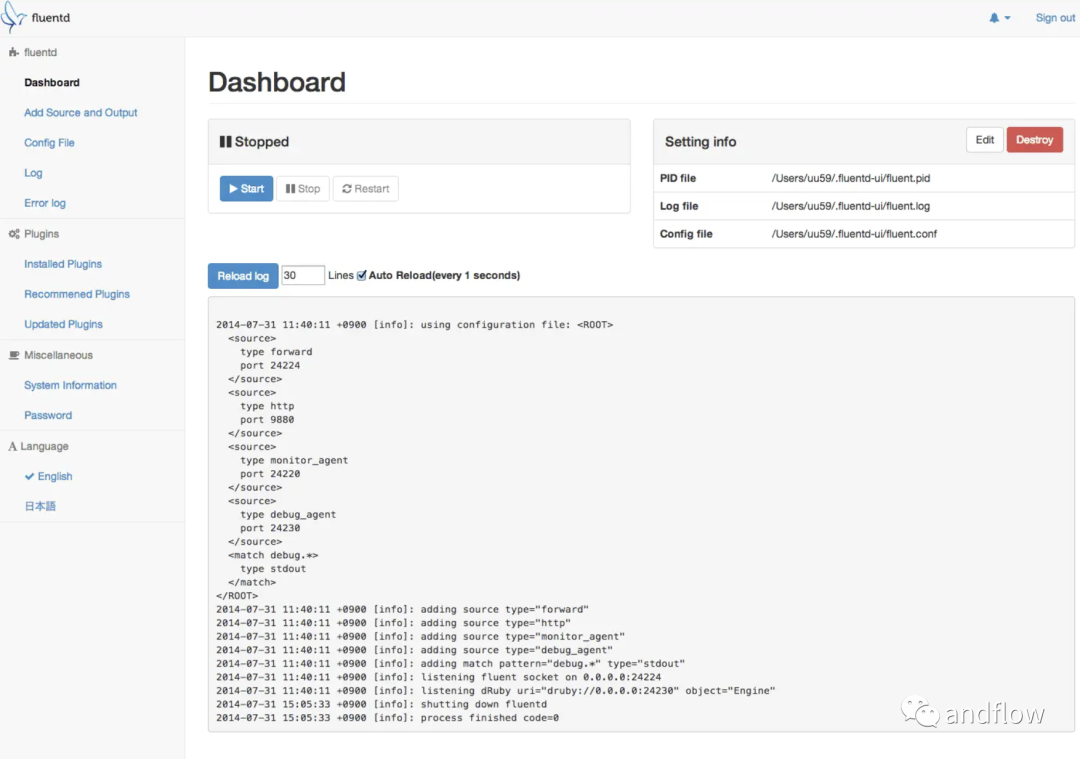
Fluentd — это инструмент с открытым исходным кодом для сбора и анализа данных, который можно использовать для создания единой инфраструктуры журналирования. Поддерживает сбор журналов из различных источников, таких как веб-серверы, базы данных и приложения, и их вывод в нескольких форматах. Журналы и отчеты также можно отправлять в Elasticsearch.
14
Telegraf
https://github.com/influxdata/telegraf
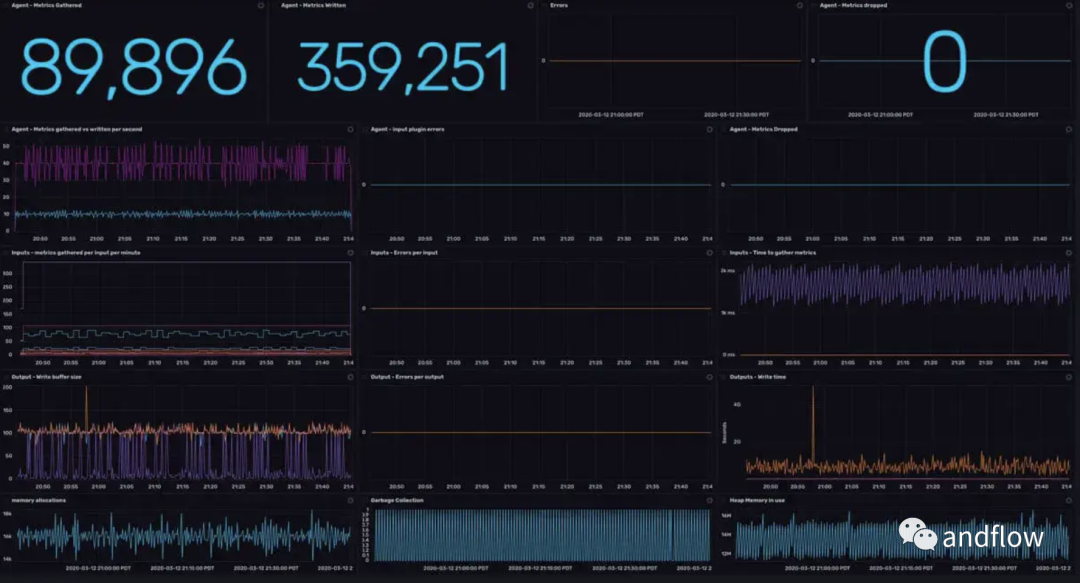
Телеграф — агент сбора, обработки, агрегирования и записи метрик для сбора и отправки различных метрик системы. Это часть платформы InfluxData (InfluxDB также является частью InfluxData).
еслиНеобходимо отслеживать производительность нескольких разных приложений, работающих на разных платформах.。Тогда вы можете использоватьTelegrafСобирайте метрики из каждого приложения и сохраняйте их вInfluxDB,Таким образом создается единая мониторная платформа. Telegraf — это просто и гибко,Но это также просто прокси-сервер метрик журнала.
15
Logstash
https://github.com/elastic/logstash
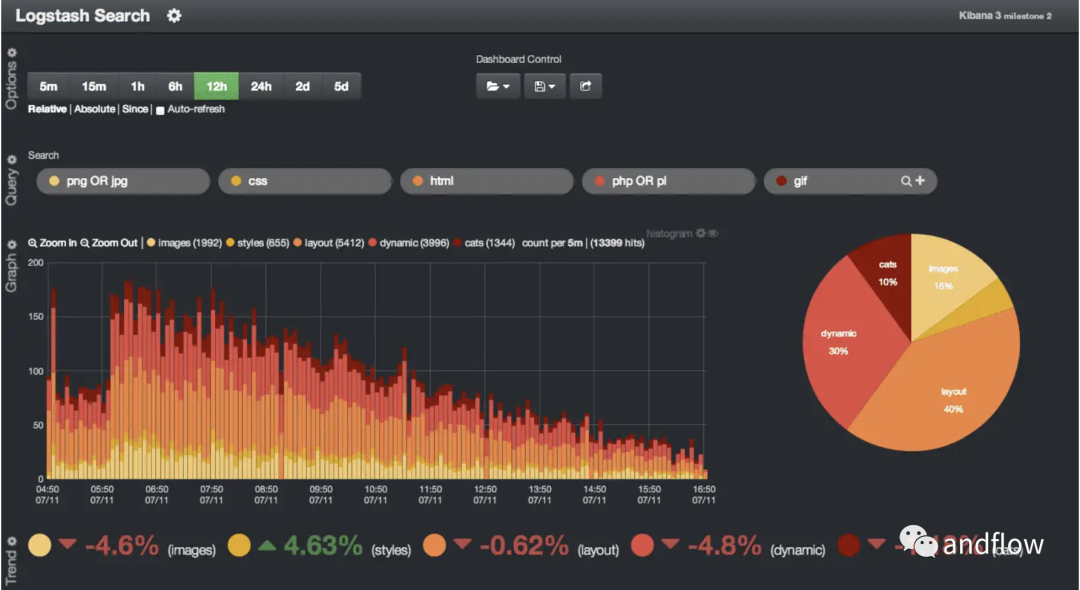
Logstash является важным компонентом стека ELK и служит конвейером для обработки данных. Он может получать данные практически из любого типа источника, динамически преобразовывать данные и отправлять их в пункт назначения.
Если мы хотим отслеживать несколько систем (например, веб-серверы, устройства безопасности и базы данных), Logstash может собирать журналы со всех этих систем и отправлять собранные данные в Elasticsearch в едином формате. Это упрощает анализ и устранение неполадок. Несмотря на то, что Logstash является мощным инструментом, он потребляет определенные ресурсы. Если вы используете Logstash в более крупной среде, вам необходимо регулярно отслеживать производительность и выполнять тонкую настройку, чтобы избежать бесполезной траты ресурсов.
Суммируя
Каждый из перечисленных выше инструментов имеет свои преимущества и недостатки. Выбор подходящего инструмента мониторинга системы зависит от конкретной операционной среды и требований к мониторингу. Кроме того, в реальной производственной среде инструменты не могут решить все проблемы, но хороший инструмент может предоставить нам лучшее решение.


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
