0915-7.1.7-Коннекторы Kafka для теста SAP HANA
Автор: Сунь Сяобо
1 Введение и базовая среда
1.1 Знакомство с коннекторами Kafka для SAP
Kafka изначально не предоставляет соединитель для SAP HANA. Проект Kafka Connectors для SAP с открытым исходным кодом GitHub предоставляет соединитель между Kafka и SAP, который может обеспечить запланированное полное или добавочное извлечение данных SAP HANA и отправку их в Kafka. Подробную информацию см. на GitHub: https://github.com/SAP/kafka-connect-sap/tree/master.
1.2 Информация о тестовой среде
Версия Kafka: 2.5.0.7.1.7.2013-1 (cloudera) Версия SAP HANA: HDB (вер. 2.00.048.04.1612945474) Проверьте следующие две ситуации:
- • В среде Kerberos полное и добавочное получение данных. Хана к Кафке
- • В среде без Kerberos полное и добавочное получение данных. Хана к Кафке
1.3 Подготовка JAR-пакета
Необходимо подготовить два пакета jar: драйвер SAP HANA и пакет проекта kafka-connect-sap. Просто выберите соответствующую версию kafka-connect-sap для загрузки и упаковки. Или загрузите jar непосредственно из выпуска GitHub: https://github.com/SAP/kafka-connect-sap/releases. Например, загрузите пакет исходного кода:
cd Downloads/kafka-connect-sap-master-2.8.1
sudo /Applications/IntelliJ\ IDEA.app/Contents/plugins/maven/lib/maven3/bin/mvn clean install -DskipTests -e
ll modules/scala_2.12/target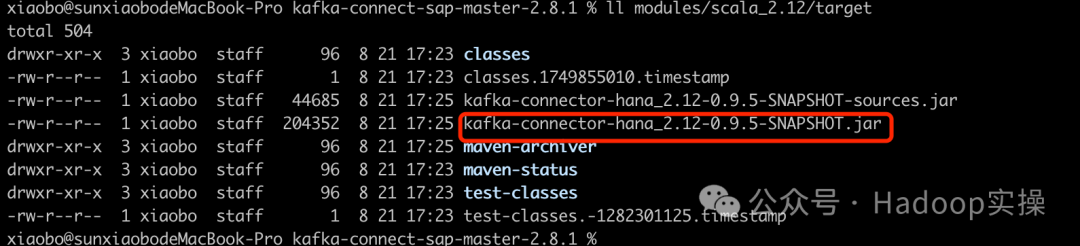
Выберите клиентский узел Kafka и поместите kafka-connector-hana_2.12-0.9.5-SNAPSHOT.jar в /var/lib/kafka/ или /opt/cloudera/parcels/CDH/lib/ клиентского узла kafka/. каталог libs/; Драйвер HANA ngdbc-2.12.9.jar находится в папке /opt/cloudera/parcels/CDH/lib/kafka/libs/.

1.4 Подготовка файла конфигурации
Интерпретацию файла конфигурации Kafka Connect Standalone см. по адресу: https://kafka.apache.org/25/documentation.html#connect_configuring. Интерпретацию файла конфигурации Kafka Connectors для SAP см. по адресу: https:// github.com/SAP/kafka-connect-sap#configuration
1.4.1 worker-nokrb.properties
worker-nokrb.properties: файл конфигурации запуска для автономного режима Kafka Connect в среде без Kerberos. Имя файла конфигурации можно настроить.
bootstrap.servers=hqcncdptst03l:9192
config.storage.replication.factor=1
config.storage.topic=connect-configs
connect.prometheus.metrics.port=28186
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
metrics.jetty.server.port=28084
offset.flush.interval.ms=60000
offset.storage.replication.factor=1
offset.storage.topic=connect-offsets
plugin.path=/var/lib/kafka
rest.extension.classes=com.cloudera.dim.kafka.metrics.JmxJsonMetricsRestExtension
rest.port=28183
ssl.client.auth=none
status.storage.replication.factor=1
status.storage.topic=connect-status
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=true
offset.storage.file.filename=/opt/hana_test/hana_offset.txt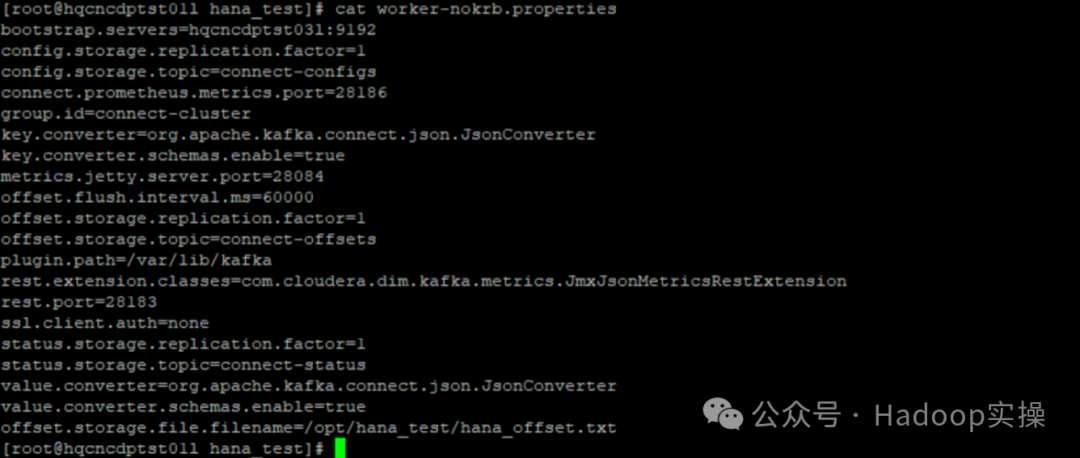
1.4.2 worker.properties
worker.properties: файл конфигурации запуска автономного режима среды Kerberos Kafka Connect, имя файла конфигурации можно настроить.
bootstrap.servers=hqcncdptst01l:9092,hqcncdptst02l:9092,hqcncdptst03l:9092
config.storage.replication.factor=1
config.storage.topic=connect-configs
connect.prometheus.metrics.port=28096
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
metrics.jetty.server.port=28094
offset.flush.interval.ms=60000
offset.storage.replication.factor=1
offset.storage.topic=connect-offsets
plugin.path=/var/lib/kafka
rest.extension.classes=com.cloudera.dim.kafka.metrics.JmxJsonMetricsRestExtension
rest.port=28093
status.storage.replication.factor=1
status.storage.topic=connect-status
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=true
producer.acks = 1
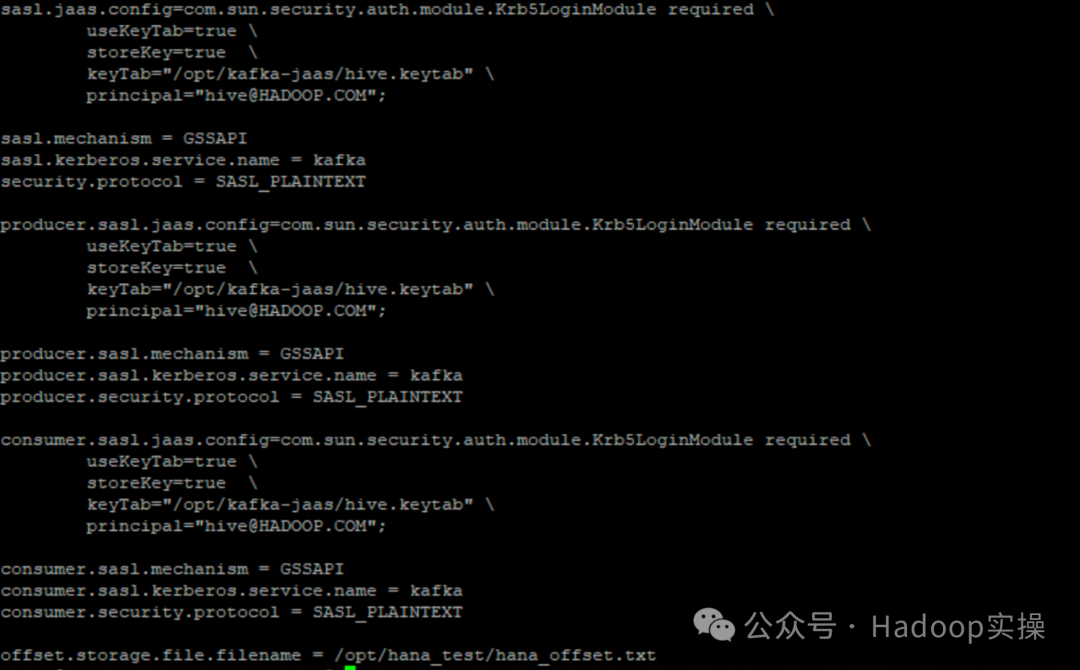
sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \
useKeyTab=true \
storeKey=true \
keyTab="/opt/kafka-jaas/hive.keytab" \
principal="hive@HADOOP.COM";
sasl.mechanism = GSSAPI
sasl.kerberos.service.name = kafka
security.protocol = SASL_PLAINTEXT
producer.sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \
useKeyTab=true \
storeKey=true \
keyTab="/opt/kafka-jaas/hive.keytab" \
principal="hive@HADOOP.COM";
producer.sasl.mechanism = GSSAPI
producer.sasl.kerberos.service.name = kafka
producer.security.protocol = SASL_PLAINTEXT
consumer.sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \
useKeyTab=true \
storeKey=true \
keyTab="/opt/kafka-jaas/hive.keytab" \
principal="hive@HADOOP.COM";
consumer.sasl.mechanism = GSSAPI
consumer.sasl.kerberos.service.name = kafka
consumer.security.protocol = SASL_PLAINTEXT
offset.storage.file.filename = /opt/hana_test/hana_offset.txt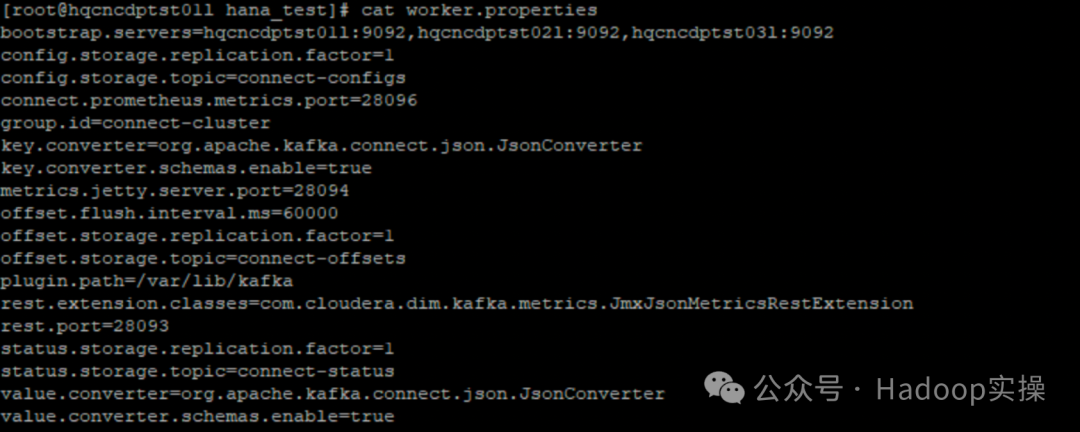
1.4.3 hana_source_full.properties
hana_source_full.properties: файл конфигурации для получения всех данных HANA. Имя файла конфигурации можно настроить.
name=hana_test-source
connector.class=com.sap.kafka.connect.source.hana.HANASourceConnector
tasks.max=1
topics=hana_test
connection.url=jdbc:sap://10.xxx.xxx.xxx:33015?encrypt=true&validateCertificate=false
connection.user=username
connection.password=xxxx
hana_test.table.name="BI_CONNECT"."MAT_SD_TEST_KAFKA"
hana_test.poll.interval.ms=60000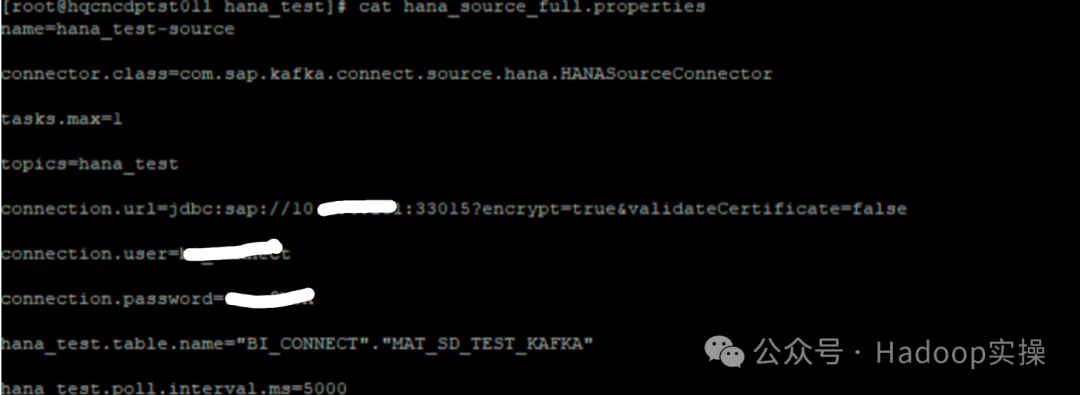
1.4.4 hana_source_incr.properties
hana_source_incr.properties: файл конфигурации для постепенного получения данных HANA. Имя файла конфигурации можно настроить.
name=hana_test-incr-source
connector.class=com.sap.kafka.connect.source.hana.HANASourceConnector
tasks.max=1
mode=incrementing
topics=hana_incr_test
connection.url=jdbc:sap://10.xxx.xxx.xxx:33015?encrypt=true&validateCertificate=false
connection.user=username
connection.password=xxxxx
hana_incr_test.table.name="BI_CONNECT"."MAT_SD_TEST_KAFKA"
hana_incr_test.poll.interval.ms=30000
hana_incr_test.incrementing.column.name=GROUP_ID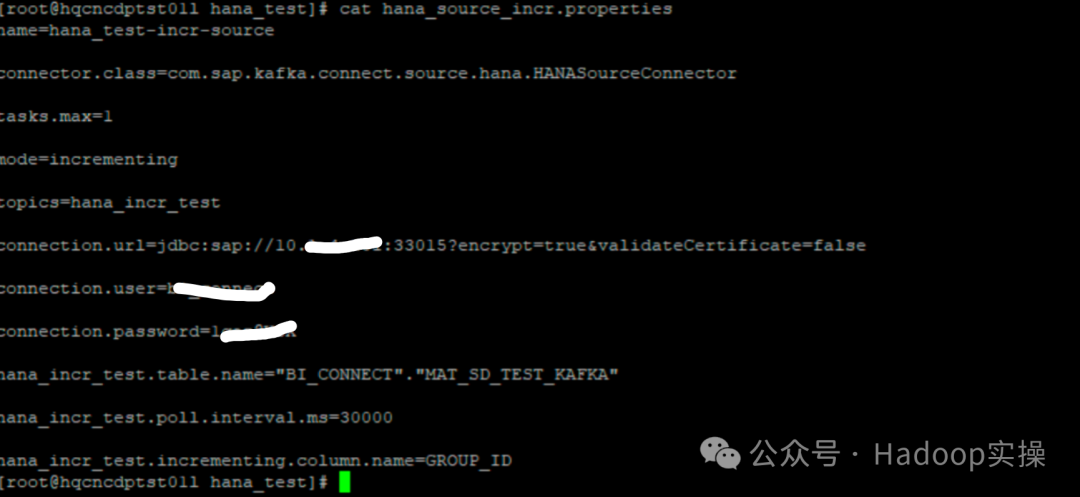
2 Тестирование среды без Kerberos
2.1 Полный тест
1. Запустите автономную задачу Kafka Connect:
/opt/cloudera/parcels/CDH/lib/kafka/bin/connect-standalone.sh worker-nokrb.properties hana_source_full.properties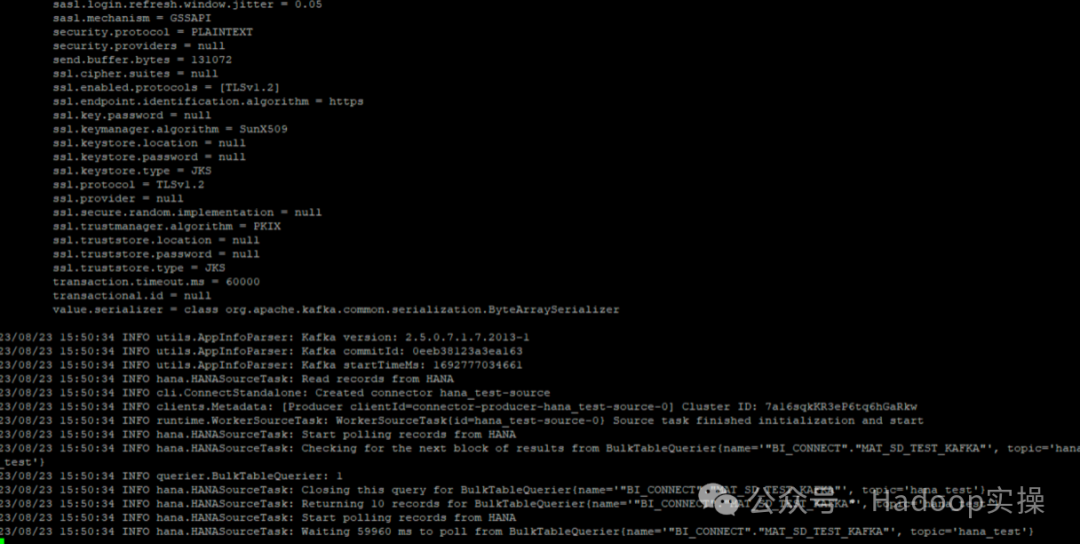
Извлекайте данные «BI_CONNECT».»MAT_SD_TEST_KAFKA» каждые 60 секунд и отправляйте их в тему Kafka hana_test.
2. Просмотр данных SAP HANA
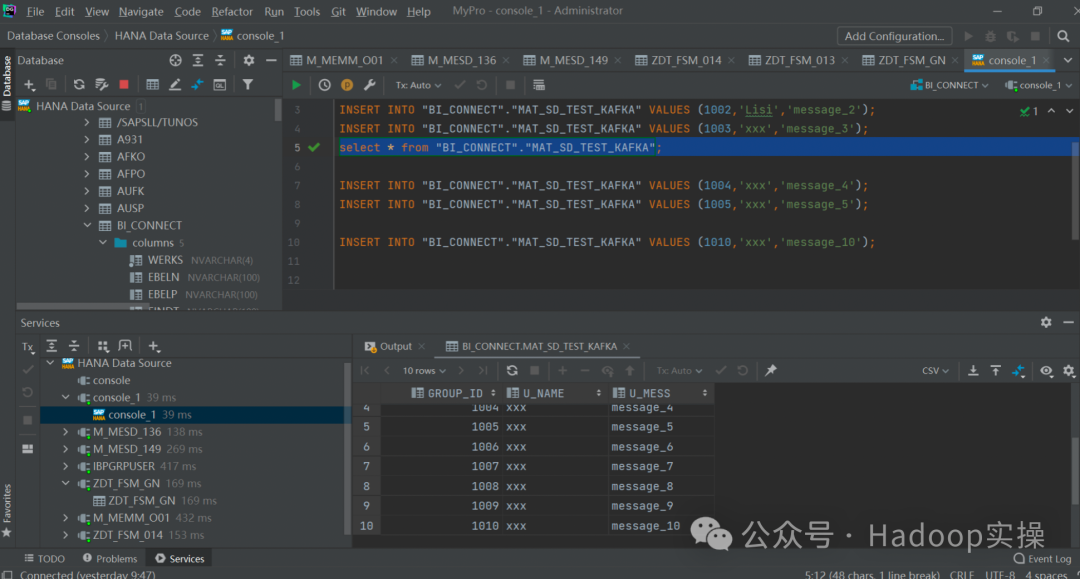
3.Kafka запускает консольного потребителя для просмотра ситуации с полученными данными.
kafka-console-consumer --topic hana_test --from-beginning --bootstrap-server $(hostname):9192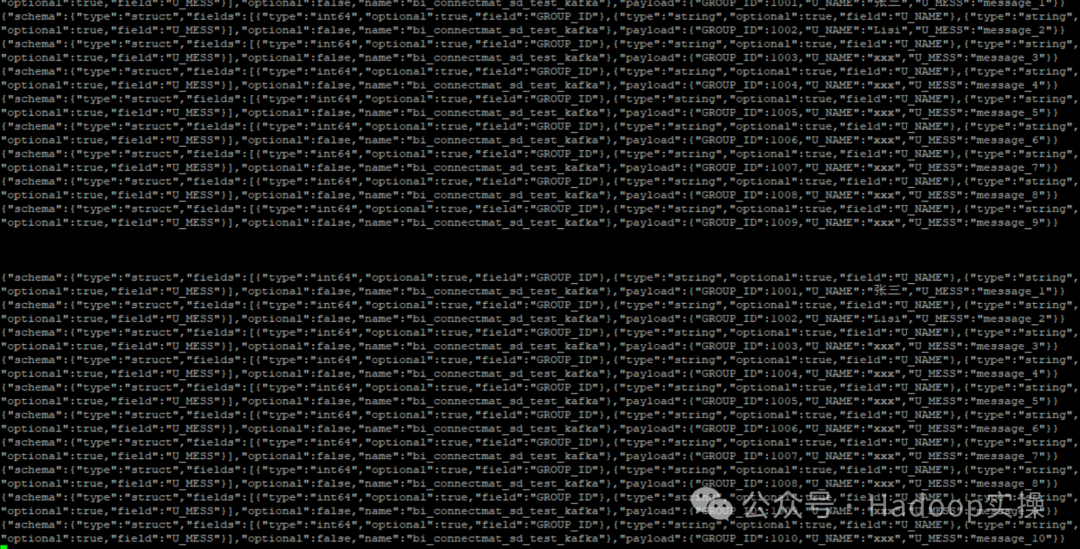
2.2 Инкрементальное тестирование
1. Запустите автономную задачу Kafka Connect:
/opt/cloudera/parcels/CDH/lib/kafka/bin/connect-standalone.sh worker-nokrb.properties hana_source_incr.properties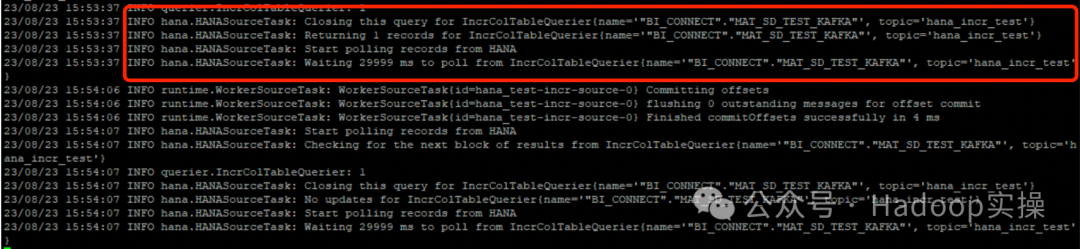
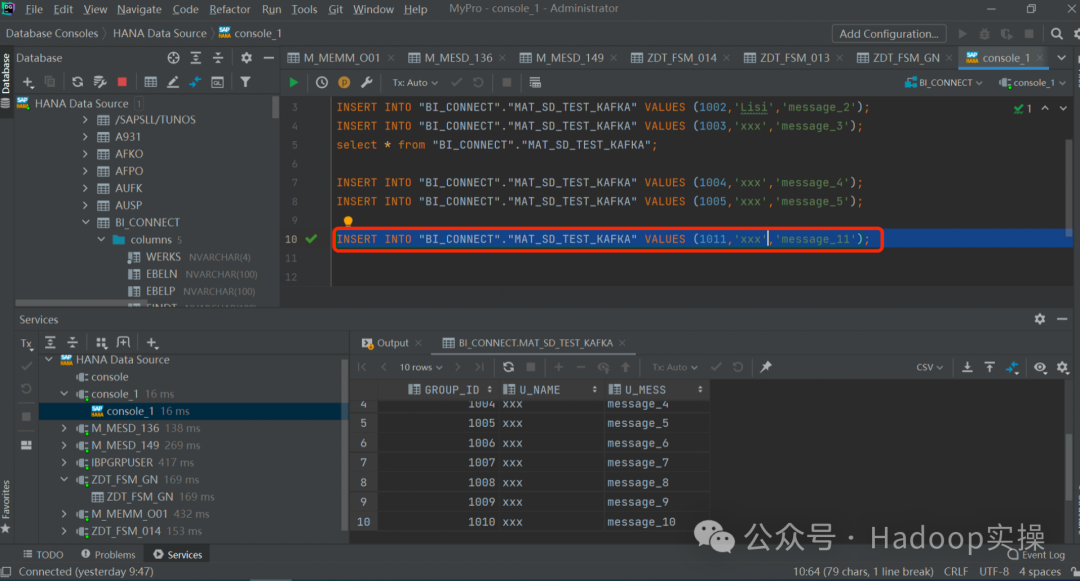
2.HANA вставляет 1 фрагмент данных.
3.Kafka запускает консольного потребителя для просмотра ситуации с полученными данными.
kafka-console-consumer --topic hana_incr_test --from-beginning --bootstrap-server $(hostname):9192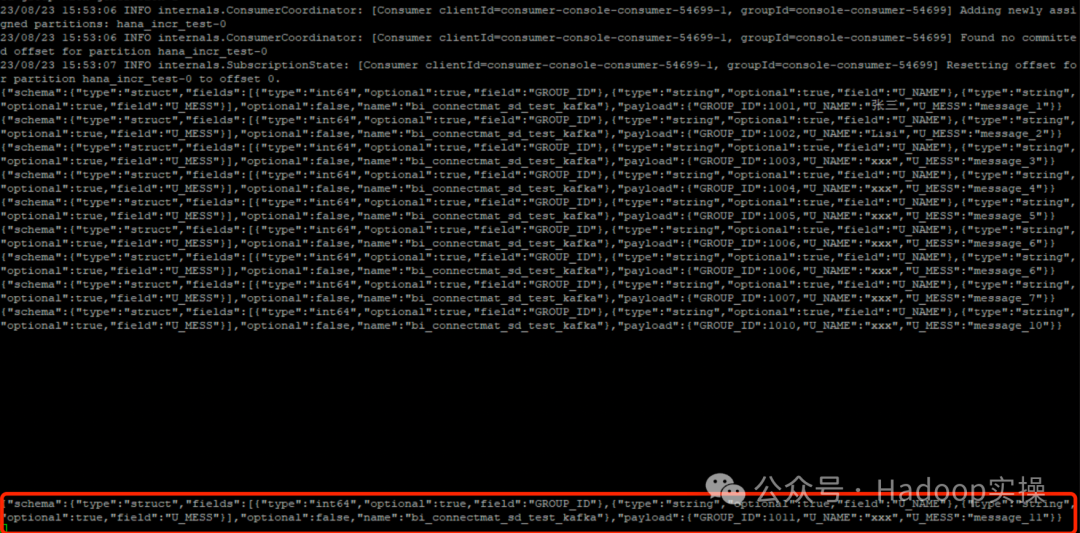
3 Тест Кербероса
3.1 Полный тест
1. Запустите автономную задачу Kafka Connect:
/opt/cloudera/parcels/CDH/lib/kafka/bin/connect-standalone.sh worker.properties hana_source_full.properties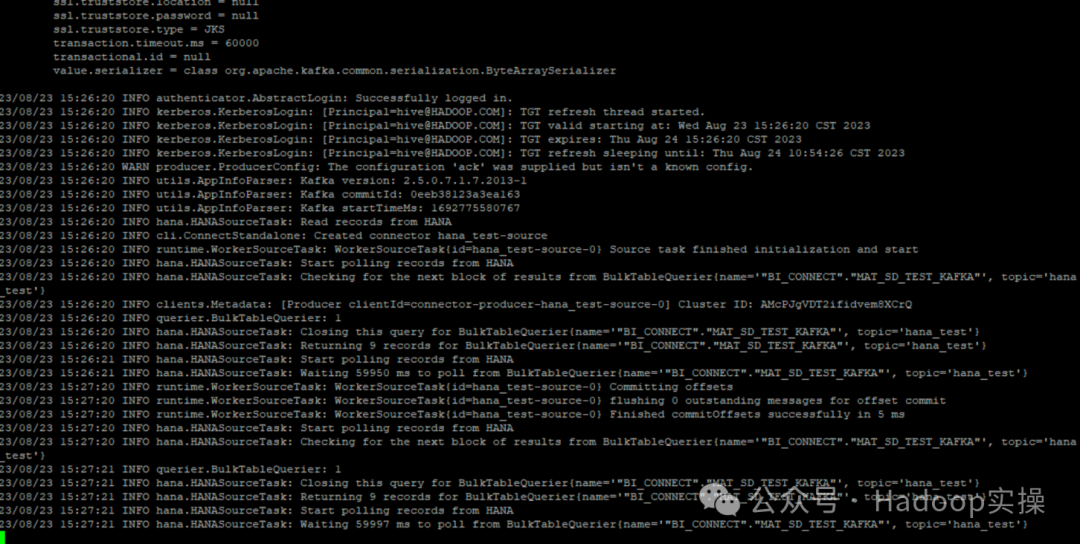
Извлекайте данные «BI_CONNECT».»MAT_SD_TEST_KAFKA» каждые 60 секунд и отправляйте их в тему Kafka hana_test.
2. Просмотр данных SAP HANA
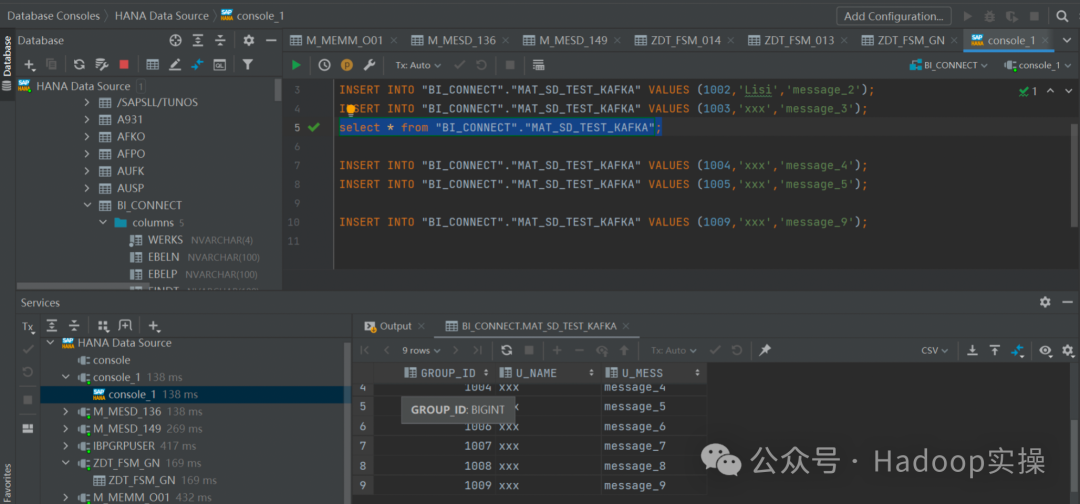
3.Kafka запускает консольного потребителя для просмотра ситуации с полученными данными.
# Приготовь кафку файл jaas и файл client.properties
export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka-jaas/jaas-hive.conf"
kafka-console-consumer --topic hana_test --from-beginning --bootstrap-server $(hostname):9092 --consumer.config client.properties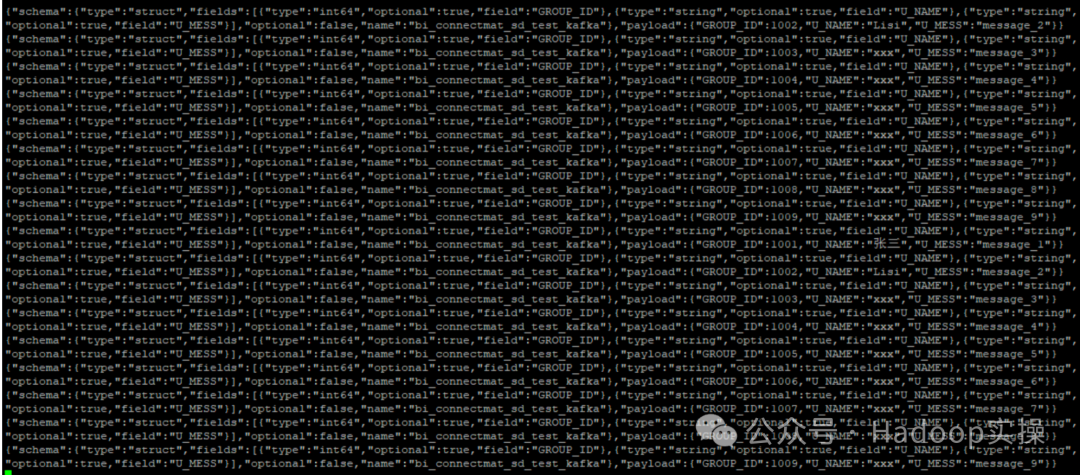
3.2 Инкрементальное тестирование
1. Запустите автономную задачу Kafka Connect:
/opt/cloudera/parcels/CDH/lib/kafka/bin/connect-standalone.sh worker.properties hana_source_incr.properties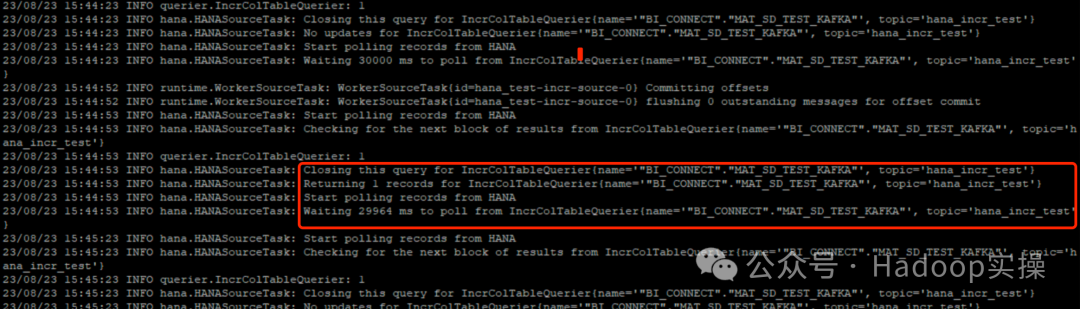
2.HANA вставляет 1 фрагмент данных.
INSERT INTO "BI_CONNECT"."MAT_SD_TEST_KAFKA" VALUES (1010,'xxx','message_10');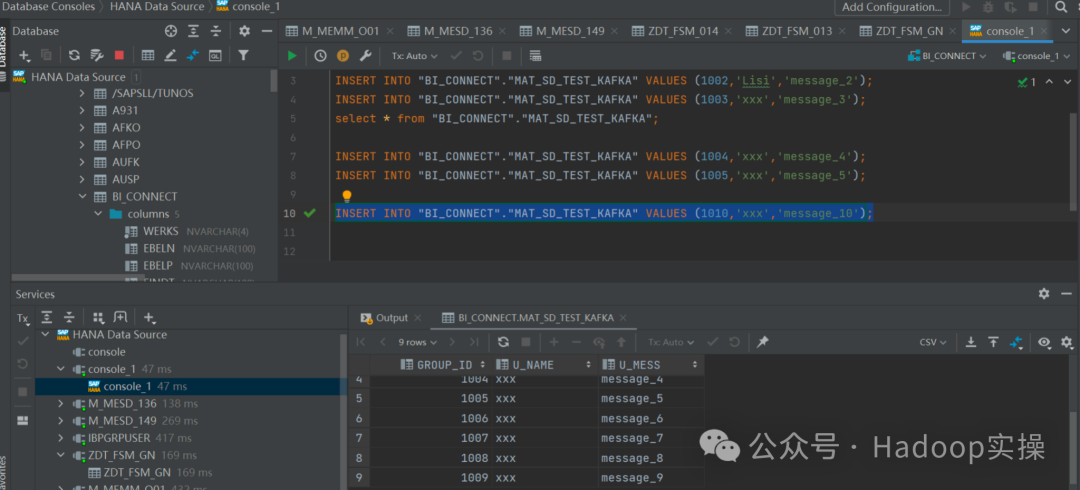
3.Kafka запускает консольного потребителя для просмотра ситуации с полученными данными.
export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka-jaas/jaas-hive.conf"
kafka-console-consumer --topic hana_incr_test --from-beginning --bootstrap-server $(hostname):9092 --consumer.config client.properties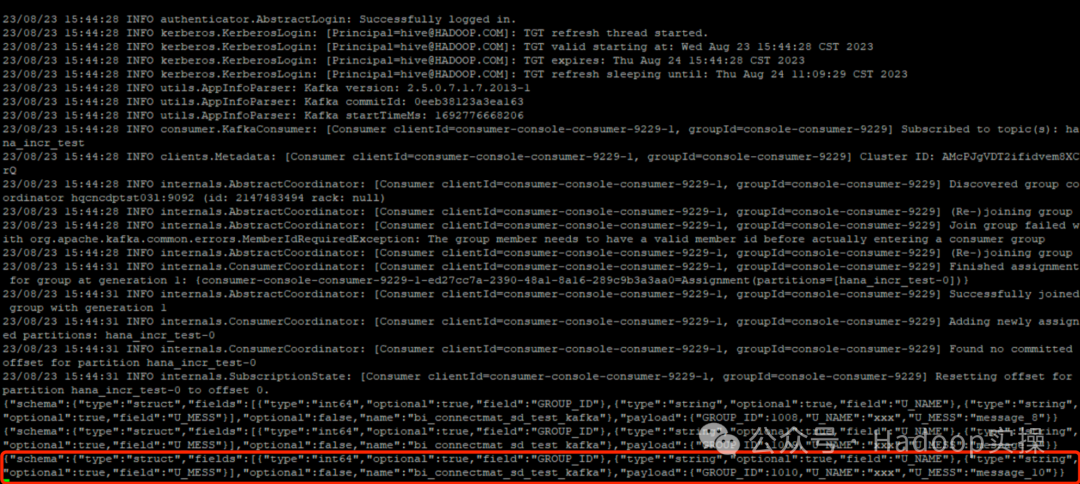
4 теста УДАЛЕНИЕ и ОБНОВЛЕНИЕ
Дополнительное тестирование ситуаций удаления и обновления в среде Kerberos.
4.1 DELETE
В режиме полного извлечения:
- 1. Удаление данных в HANA.
delete from "BI_CONNECT"."MAT_SD_TEST_KAFKA" where GROUP_ID = 1011- 1. Запустить Кафку Connect После выполнения автономной задачи просмотрите Kafka. consumer
{"schema":{"type":"struct","fields":[{"type":"int64","optional":true,"field":"GROUP_ID"},{"type":"string","optional":true,"field":"U_NAME"},{"type":"string","optional":true,"field":"U_MESS"}],"optional":false,"name":"bi_connectmat_sd_test_kafka"},"payload":{"GROUP_ID":1010,"U_NAME":"xxx","U_MESS":"message_10"}}
{"schema":{"type":"struct","fields":[{"type":"int64","optional":true,"field":"GROUP_ID"},{"type":"string","optional":true,"field":"U_NAME"},{"type":"string","optional":true,"field":"U_MESS"}],"optional":false,"name":"bi_connectmat_sd_test_kafka"},"payload":{"GROUP_ID":1012,"U_NAME":"xxx","U_MESS":"message_12_new"}}В результате данных нет удаленных данных, что указывает на то, что удаленные данные не отправляются в Kafka. В режиме постепенного извлечения:
- 1. Удаление данных в HANA.
delete from "BI_CONNECT"."MAT_SD_TEST_KAFKA" where GROUP_ID = 10102. После выполнения автономной задачи Kafka Connect убедитесь, что удаления, удаленные потребителем Kafka, не отправляются в тему Kafka.
3. Просмотрите журнал выходных данных автономной задачи Kafka Connect.
23/08/24 10:02:56 INFO querier.IncrColTableQuerier: 1
23/08/24 10:02:56 INFO hana.HANASourceTask: Closing this query for IncrColTableQuerier{name='"BI_CONNECT"."MAT_SD_TEST_KAFKA"', topic='hana_incr_test'}
23/08/24 10:02:56 INFO hana.HANASourceTask: No updates for IncrColTableQuerier{name='"BI_CONNECT"."MAT_SD_TEST_KAFKA"', topic='hana_incr_test'}
23/08/24 10:02:56 INFO hana.HANASourceTask: Start polling records from HANA
23/08/24 10:02:56 INFO hana.HANASourceTask: Waiting 30000 ms to poll from IncrColTableQuerier{name='"BI_CONNECT"."MAT_SD_TEST_KAFKA"', topic='hana_incr_test'}В журнале нет обновлений данных.
4.2 UPDATE
В режиме полного извлечения:
1. Обновите часть данных в HANA.
update "BI_CONNECT"."MAT_SD_TEST_KAFKA" set U_MESS = 'message_12_new' where GROUP_ID = 10122. После выполнения автономной задачи Kafka Connect просмотрите потребитель Kafka.
{"schema":{"type":"struct","fields":[{"type":"int64","optional":true,"field":"GROUP_ID"},{"type":"string","optional":true,"field":"U_NAME"},{"type":"string","optional":true,"field":"U_MESS"}],"optional":false,"name":"bi_connectmat_sd_test_kafka"},"payload":{"GROUP_ID":1012,"U_NAME":"xxx","U_MESS":"message_12_new"}}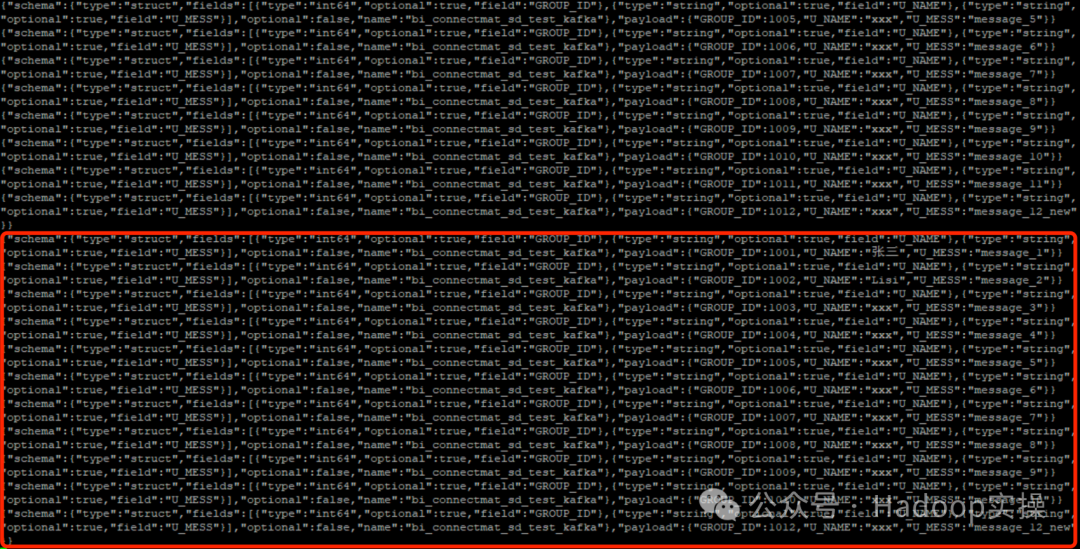
После того, как Данные Хана будут изменены, извлеките всю сумму и отправьте ее в Кафку. В режиме постепенного извлечения:
1. Обновите две части данных в HANA.
update "BI_CONNECT"."MAT_SD_TEST_KAFKA" set U_MESS = 'message_9_new' where GROUP_ID = 1009
update "BI_CONNECT"."MAT_SD_TEST_KAFKA" set GROUP_ID = 10088 where U_MESS = 'message_8'Обновите значения полей GROUP_ID и U_MESS соответственно.
2. После выполнения автономной задачи Kafka Connect просмотрите потребитель Kafka.
{"schema":{"type":"struct","fields":[{"type":"int64","optional":true,"field":"GROUP_ID"},{"type":"string","optional":true,"field":"U_NAME"},{"type":"string","optional":true,"field":"U_MESS"}],"optional":false,"name":"bi_connectmat_sd_test_kafka"},"payload":{"GROUP_ID":10088,"U_NAME":"xxx","U_MESS":"message_8"}}Результаты показывают, что обновленные данные GROUP_ID будут извлечены и отправлены в Kafka, поскольку мы указали параметр hana_incr_test.incrementing.column.name=GROUP_ID в файле конфигурации hana_source_incr.properties, а изменение GROUP_ID используется для определения данных. приращение. Таким образом, только если столбец, указанный в файле конфигурации с именем увеличивающегося.столбца.имя, изменяется, он считается инкрементными данными и может быть отправлен в Kafka.
4.3 Итоги испытаний
1. В режиме полного извлечения полный объем данных будет регулярно извлекаться и отправляться в Kafka через указанный интервал полного извлечения. Данные всегда основаны на данных, запрошенных HANA, а неизмененные и измененные данные будут отображаться. Отправьте всю сумму в тему Kafka.
2. В режиме добавочного извлечения необходимо указать столбец таблицы HANA как добавочный столбец. Независимо от того, является ли столбец первичным ключом, следующие выводы являются последовательными.
- • Когда обновленные данные представляют собой добавленный столбец, указанный в файле конфигурации, обновленные данные отправляются в Kafka. topic。
- • Если обновленные данные представляют собой столбец, который не указан в файле конфигурации, они не будут отправлены в Kafka. topic。
- • При удалении данных удаляемые данные не могут обнаружить обновления и не будут отправлены в Kafka. topic。
5 Другие способы решения проблем и меры предосторожности
1. Измените автономный сценарий запуска Kafka Connect. Файл конфигурации log4j указан в сценарии запуска, но на самом деле он не существует. Будет сообщено об ошибке:
java.io.FileNotFoundException: /opt/cloudera/parcels/CDH/lib/kafka/bin/../config/connect-log4j.properties (No such file or directoryЧтобы решить проблему, вы можете закомментировать следующее:
vim /opt/cloudera/parcels/CDH/lib/kafka/bin/connect-standalone.sh
if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/connect-log4j.properties"
fi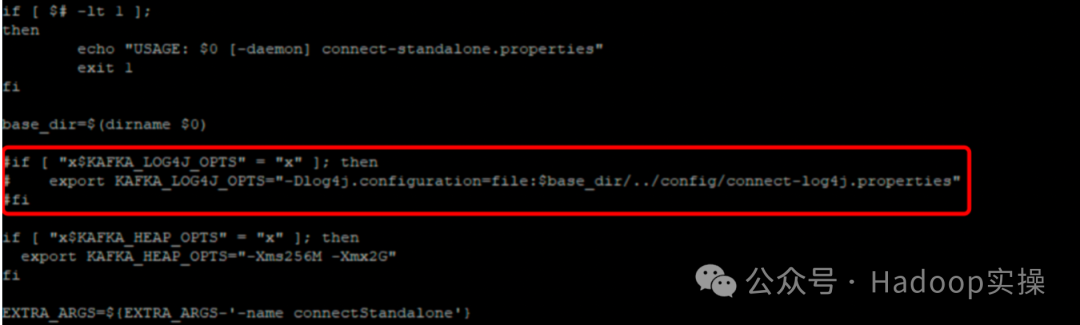
2. При запуске автономного подключения kafka сообщается о некоторых ошибках, например: org.reflections.ReflectionsException: не удалось получить тип для имени org.springframework.beans.factory.FactoryBean, которое можно игнорировать.
3. В автономном файле конфигурации Kafka Connect необходимо указать адрес файла смещения хранилища. Вы можете сначала создать пустой файл.
offset.storage.file.filename = /opt/hana_test/hana_offset.txt4. В среде Kerberos в автономной конфигурации Kafka Connect тип аутентификации и конфигурацию jaas потребителя и производителя необходимо указывать отдельно с помощью conmuser.xxx и Producer.xxx соответственно.
producer.sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \
useKeyTab=true \
storeKey=true \
keyTab="/opt/kafka-jaas/hive.keytab" \
principal="hive@HADOOP.COM";
producer.sasl.mechanism = GSSAPI
producer.sasl.kerberos.service.name = kafka
producer.security.protocol = SASL_PLAINTEXT
consumer.sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \
useKeyTab=true \
storeKey=true \
keyTab="/opt/kafka-jaas/hive.keytab" \
principal="hive@HADOOP.COM";
consumer.sasl.mechanism = GSSAPI
consumer.sasl.kerberos.service.name = kafka
consumer.security.protocol = SASL_PLAINTEXT


Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
