0911-7.1.7-Как использовать SQL-клиент Flink в кластере CDP и интегрироваться с Hive
1 Обзор документа
передFaysonпредставил《0876-7.1.7-Как развернуть Flink1.14 в CDP》,В то же время Flink также предоставляет SQL. Возможности клиента предоставляют простой способ написания, отладки и отправки программ в кластер Flink без написания единой строки кода Java или Scala. В этой статье в основном рассказывается, как использовать Flink в кластере CDP. SQL Клиент интегрирован с Hive. Интеграция Flink и Hive в основном преследует две следующие цели:
Во-первых, вы можете использовать Metastore Hive в качестве постоянного каталога и HiveCatalog Flink для хранения метаданных, специфичных для Flink, между сеансами. Например: пользователи могут использовать HiveCatalog для хранения таблиц Kafka и ElasticSearch в HiveMetastore, а затем повторно использовать их в запросах SQL.
Во-вторых, Flink можно использовать как альтернативный движок для чтения и записи Hive.
- • тестовая среда
- 1. CM7.4.4 и CDP7.1.7.
- 2. Операционная система Redhat7.6.
- 3. Flink1.14.0-csa1.6.1.0
- 4. кластерKerberos не включен
2 Инструкции по интеграции с Hive и подготовке зависимостей
1. Flink поддерживает следующие версии Hive:

Уведомление:Hiveразные версии сFlinkИнтеграция имеет различные функциональные различия,Эта проблема поддерживается самим Hive.,Текущая версия Hive в CDP — 3.1.3000.,В настоящее время он не поддерживается.
- • Версия 1.2 и выше поддерживают встроенные функции Hive.
- • 3.1 и более поздние версии поддерживают ограничения столбцов (т. е. ПЕРВИЧНЫЙ КЛЮЧ и NOT NULL).
- • Версия 1.2.0 и более поздние поддерживают изменение статистики таблицы.
- • Версия 1.2.0 и более поздние поддерживают статистику столбца DATE.
- • Версия 2.0.x не поддерживает запись в таблицы ORC.
2. Интеграция Hive и Flink требует введения дополнительных пакетов зависимостей. Вы можете использовать официально доступные пакеты зависимостей, а можете реализовать это самостоятельно, внедрив независимые зависимости.
- • Доступные пакеты зависимостей, предоставляемые в настоящее время на официальном сайте Flink, следующие:

Примечание. Официально предоставляемая в настоящее время версия Hive3 для зависимостей несовместима с версией Hive в CDP7.1.7 и недоступна после тестирования.
- • Внедрить независимые пакеты зависимостей (в следующем списке кратко перечислены несколько версий, подробную информацию можно найти на официальном сайте).

3. Официально предоставленный исполняемый пакет зависимостей не очень хорошо адаптирован к CDP. Вы можете загрузить независимые зависимости только вторым способом, чтобы добиться интеграции с Hive.
- • Загрузите пакет зависимостей flink-connector-hive из официальной библиотеки Maven Cloudera.
https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive_2.12/1.14.0-csa1.6.0.0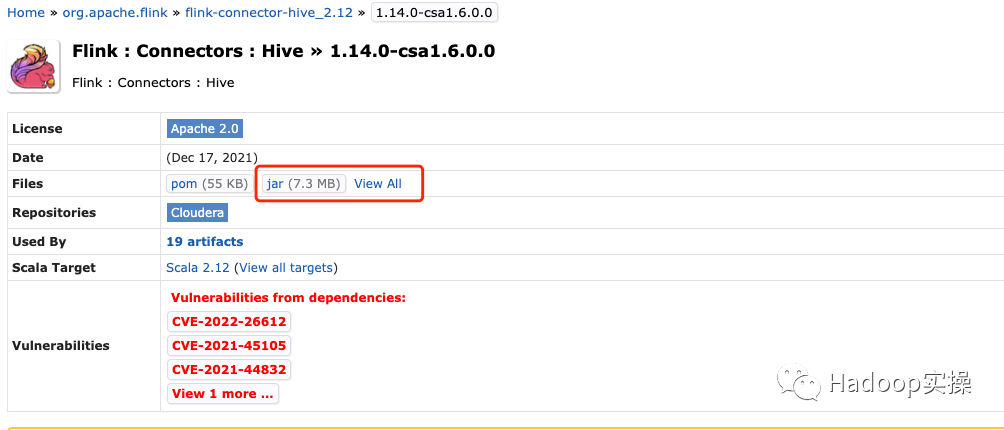
Метод введения зависимости Maven:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.14.0-csa1.6.0.0</version>
<scope>provided</scope>
</dependency>4. Загрузите загруженный пакет зависимостей в каталог /opt/cloudera/iceberg кластера CDP с ролью Flink Gateway.
mkdir -p /opt/cloudera/iceberg
5. Выше также упоминалось, что hive-exec и другие зависимые пакеты получаются в кластере. Конкретные пути следующие:
/opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec.jar
/opt/cloudera/parcels/CDH/lib/hadoop/client/hadoop-mapreduce-client-core.jar
/opt/cloudera/parcels/CDH/lib/hive/lib/libfb303-0.9.3.jar
/opt/cloudera/parcels/CDH/jars/antlr-runtime-3.5.2.jar
Для интеграции Flink и Hive после нахождения зависимого пакета Jar вы можете скопировать вышеупомянутый зависимый пакет jar в каталог установки Flink /opt/cloudera/parcels/FLINK/lib/flink/lib/ (необходимо скопировать). всем узлам кластера), который можно ввести через -j при запуске командной строки клиента.
flink-sql-client embedded \
-j /opt/cloudera/iceberg/iceberg-flink-runtime-1.14-0.13.1.jar \
-j /opt/cloudera/iceberg/flink-connector-hive_2.12-1.14.0-csa1.6.0.0.jar \
-j /opt/cloudera/parcels/CDH/lib/hadoop/client/hadoop-mapreduce-client-core.jar \
-j /opt/cloudera/parcels/CDH/lib/hive/lib/libfb303-0.9.3.jar \
-j /opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec.jar \
shell3 Проверка интеграции Flink и Hive
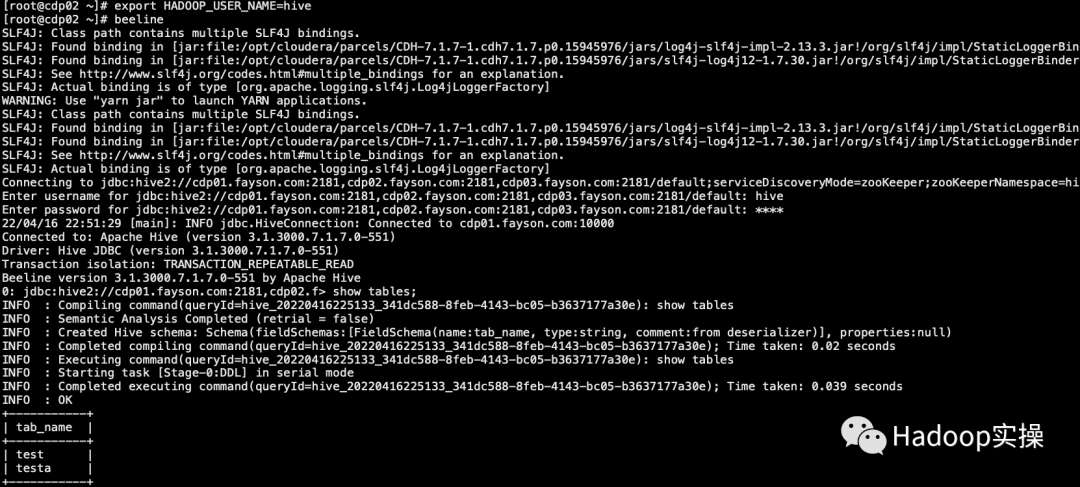
1. Выполните следующий скрипт в командной строке, чтобы запустить Flink SQL Client.
export HADOOP_USER_NAME=hive
flink-sql-client embedded \
-j /opt/cloudera/iceberg/flink-connector-hive_2.12-1.14.0-csa1.6.0.0.jar \
-j /opt/cloudera/parcels/CDH/lib/hadoop/client/hadoop-mapreduce-client-core.jar \
-j /opt/cloudera/parcels/CDH/lib/hive/lib/libfb303-0.9.3.jar \
-j /opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec.jar \
shell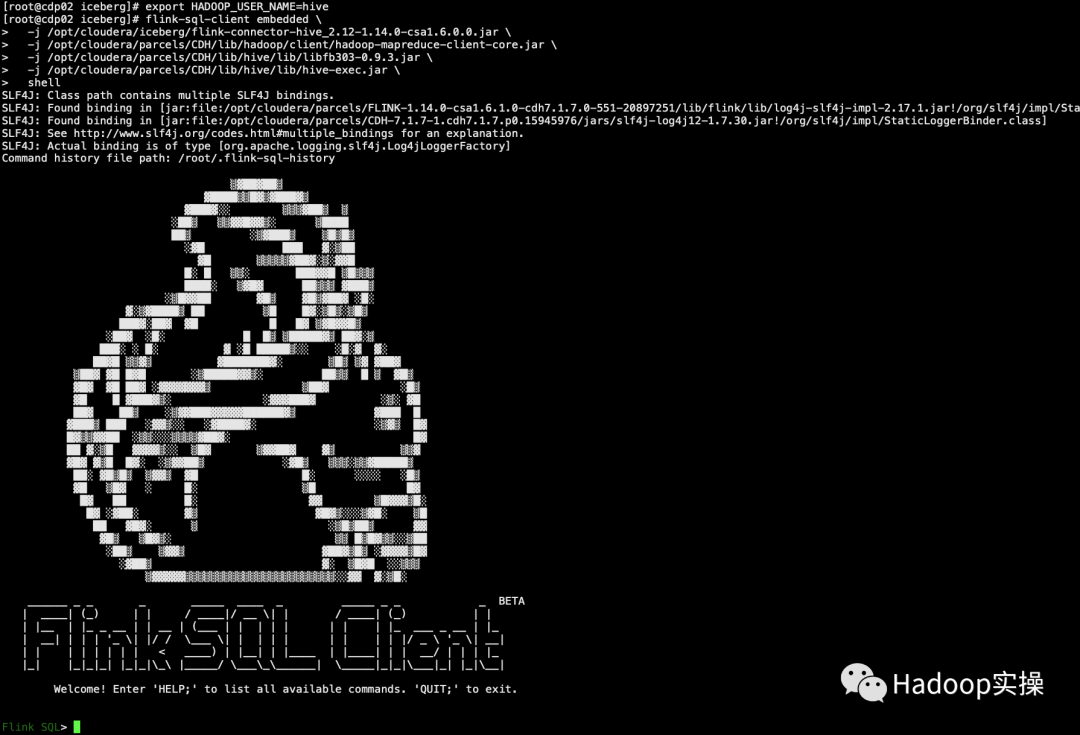
2. Выполните следующие команды в командной строке, чтобы установить режим отображения результатов и режим выполнения.
SET 'sql-client.execution.result-mode' = 'tableau';
SET 'execution.runtime-mode' = 'batch';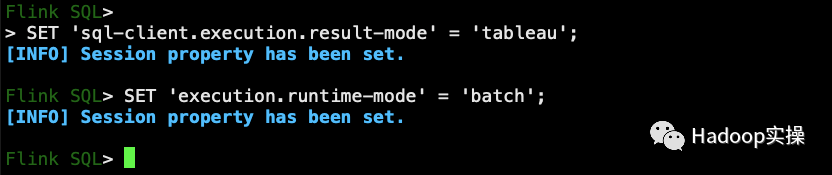
Для удобства отображения здесь используется пакетное выполнение и табличное отображение.
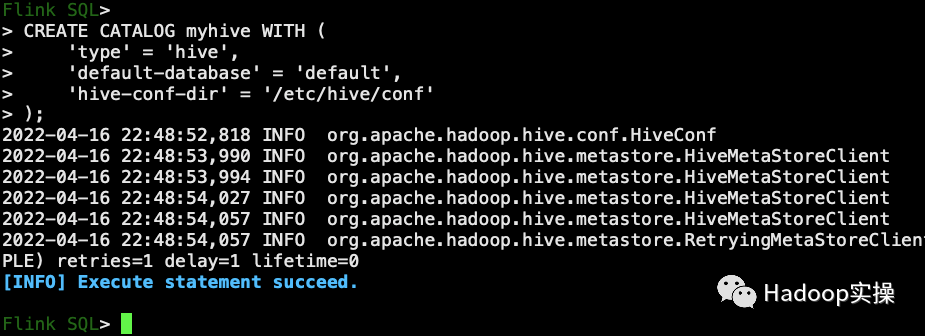
3. Выполните следующую команду, чтобы создать каталог Hive.
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/etc/hive/conf'
);
Посмотреть созданный Каталог
show CATALOGS;
4. Войдите в созданный каталог myhive и просмотрите таблицу.
use catalog myhive;
show tables;
Представленная здесь таблица соответствует таблице в Hive и также является соответствующей таблицей Hive.
5. Выполните инструкции SQL в командной строке для запроса данных таблицы.
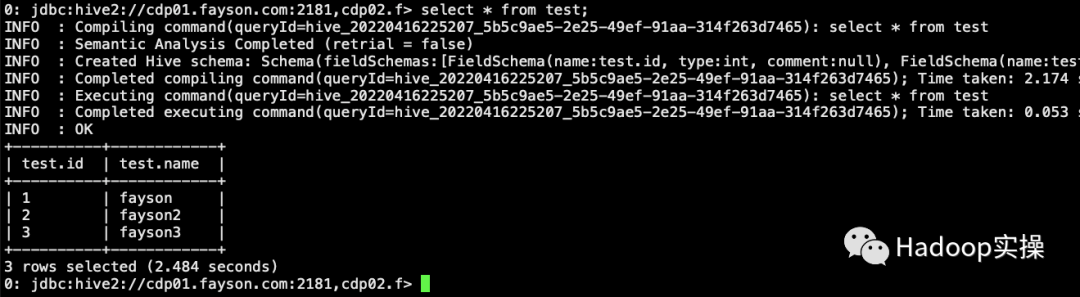
select * from test;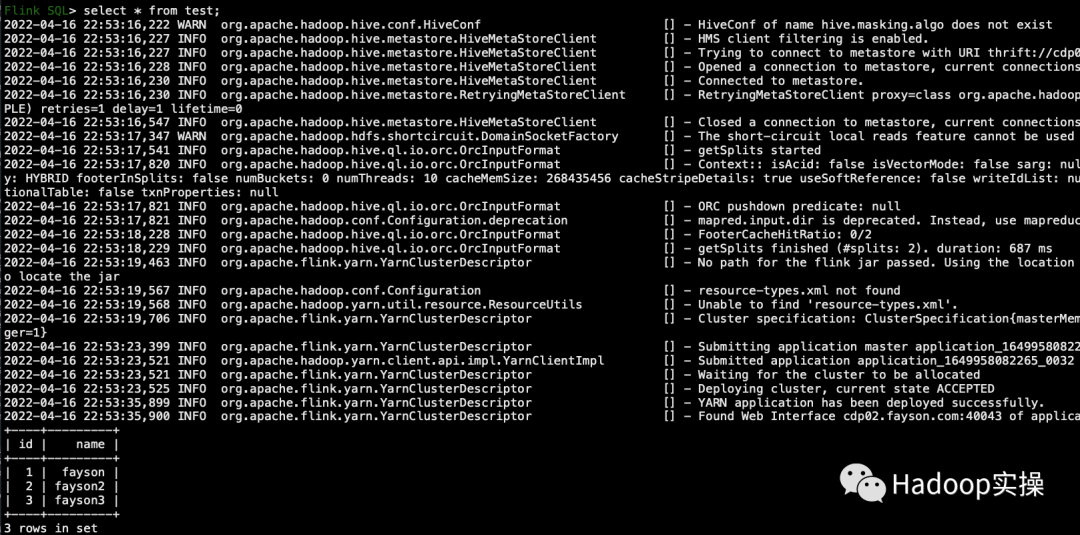
Соответствует данным, запрошенным в Hive
6. Выполните операцию подсчета SQL.
select count(*) from test;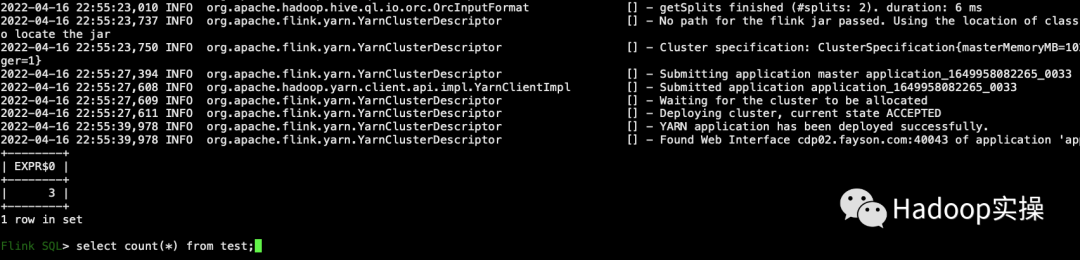
4 Обработка исключений
1. При запуске примера подсчета слов Flink в командной строке после завершения задания появляется следующий вывод журнала исключений.
Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.ensureInner(FlinkUserCodeClassLoaders.java:164)
at 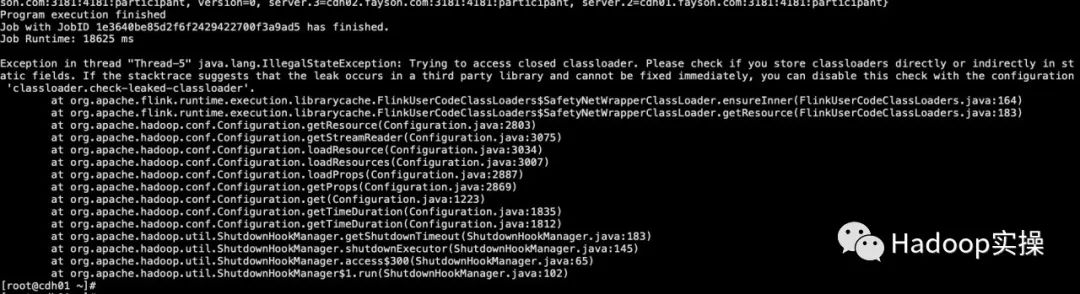
Решение:
Добавьте следующую конфигурацию в файл flink-conf.yaml для роли Flink Gateway в Cloudera Manager:
classloader.check-leaked-classloader: false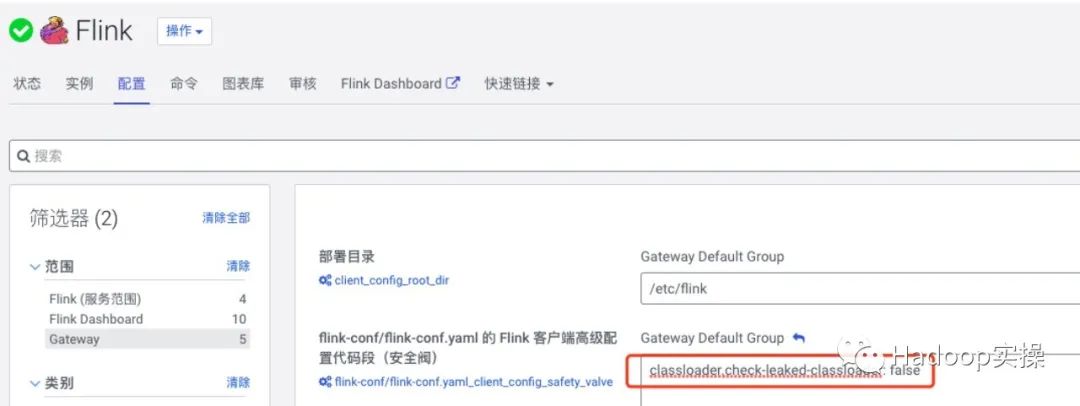
2. При использовании примера WordCount от Flink в командной строке будет выдано большое количество ненормальных выходных данных журнала, а именно:
2022-04-13 08:37:50,368 ERROR org.apache.flink.shaded.curator4.org.apache.curator.ConnectionState [] - Authentication failed
2022-04-13 08:37:50,399 ERROR org.apache.flink.shaded.curator4.org.apache.curator.framework.imps.EnsembleTracker [] - Invalid config event received: {server.1=cdp03.fayson.com:3181:4181:participant, version=0, server.3=cdp02.fayson.com:3181:4181:participant, server.2=cdp01.fayson.com:3181:4181:participant}Решение:
Добавьте следующую конфигурацию в log4j.properties и log4j-cli.properties роли Flink Gateway в Cloudera Manager:
logger.curator.name = org.apache.flink.shaded.curator4.org.apache.curator.framework.imps.EnsembleTracker
logger.curator.level = OFF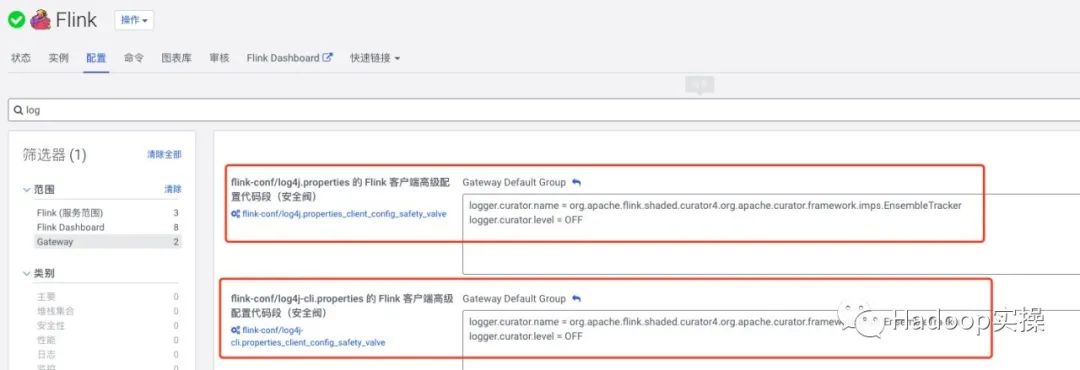
Анализ проблемы:
Приведенный выше ненормальный журнал в основном связан с введением пакета зависимостей Curator в Flink. Когда пакет зависимостей обрабатывает сообщения Zookeeper, полученная информация содержит «{}», что приводит к исключению при анализе данных. В настоящее время это исключение не существует. Влияет на использование сервисов (https://issues.apache.org/jir). a/browse/CURATOR-526), исправлено после версии Curator 5.2. В исправленном коде видно, что уровень журнала изменен с log.error на log.debug, см. https://github.com/. Apache /куратор/pull/382
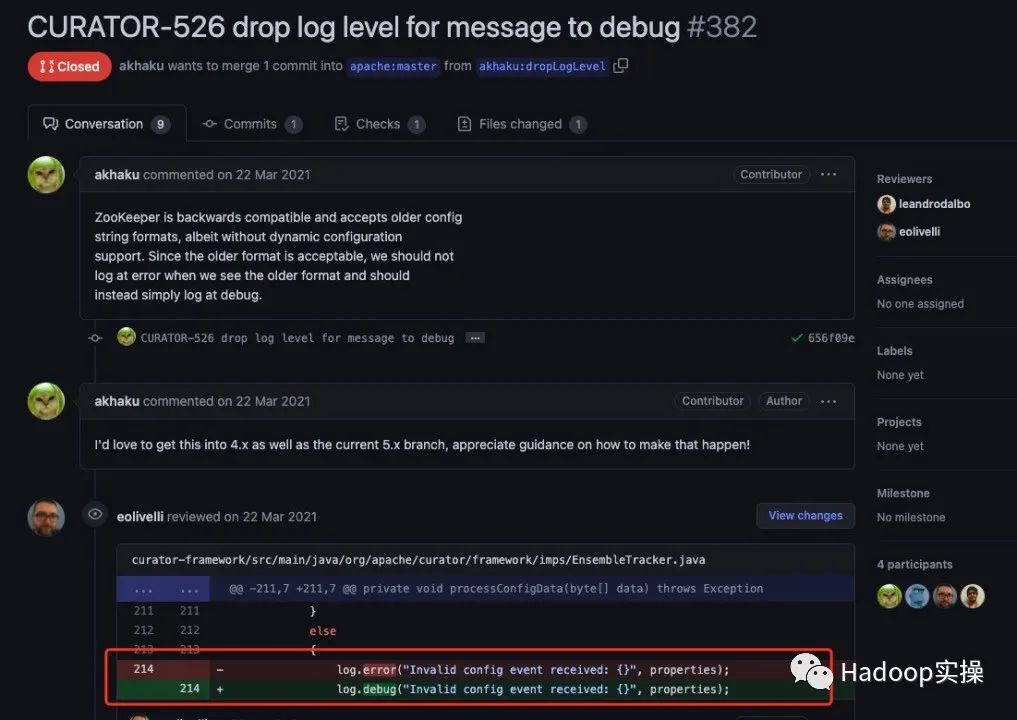
Попробуйте упаковать исправленные в версии 5.2 классы в каталог org/apache/flink/shaded/curator4/org/apache/curator/framework/imps файла flink-shaded-zookeeper-3.5.5.7.1.7.0-551.jar. Однако при запуске задания произошел сбой, и журнал исключений был запрошен следующим образом:
Caused by: java.lang.NoClassDefFoundError: org/apache/flink/shaded/curator4/org/apache/curator/framework/imps/EnsembleTracker (wrong name: org/apache/curator/framework/imps/EnsembleTracker)
Вы можете рассмотреть возможность перекомпиляции здесь. Мы еще не пробовали, но решили проблему, отфильтровав журнал ОШИБОК.
3. После интеграции Flink с Hive при запуске кода SQL сообщается о большом количестве журналов исключений.
2022-04-13 08:58:24,505 WARN org.apache.flink.streaming.api.operators.collect.CollectResultFetcher [] - An exception occurred when fetching query results
java.util.concurrent.ExecutionException: org.apache.flink.runtime.rest.util.RestClientException: [Internal server error., <Exception on server side:
org.apache.flink.runtime.messages.FlinkJobNotFoundException: Could not find Flink job (ef7f994a08f57141fafd18481d13ab85)
at 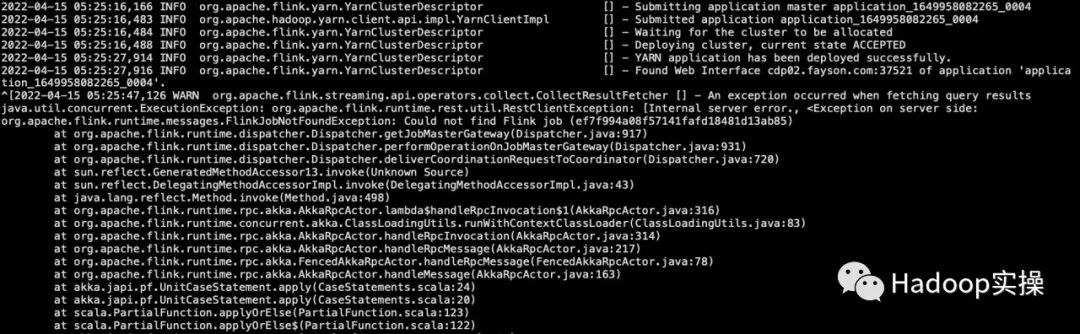
Анализ проблемы: В этом можно убедиться, проанализировав лог менеджера заданий Flink.
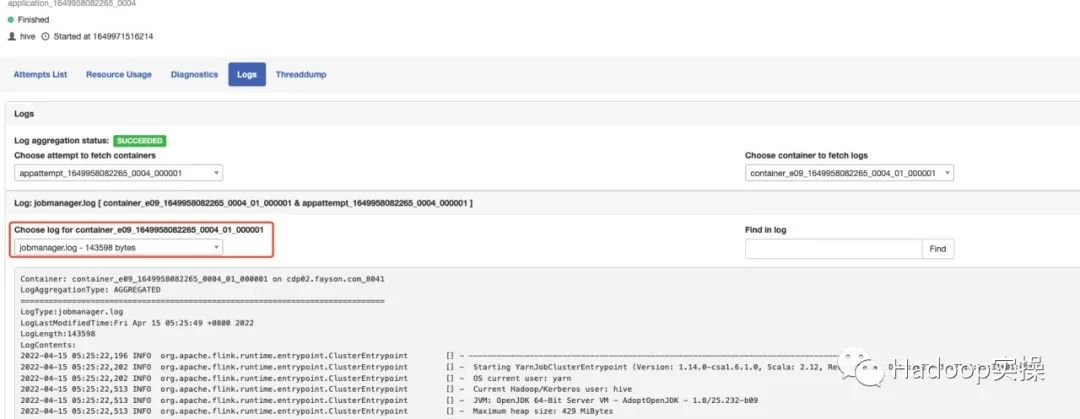

Из журнала видно, что идентификатор задания, о котором сообщается об ошибке (ef7f994a08f57141fafd18481d13ab85), на самом деле является запросом, полученным после остановки соответствующего JobMaster, поэтому возникает эта ошибка. Найдите соответствующий исходный код в сегменте журнала ошибок.
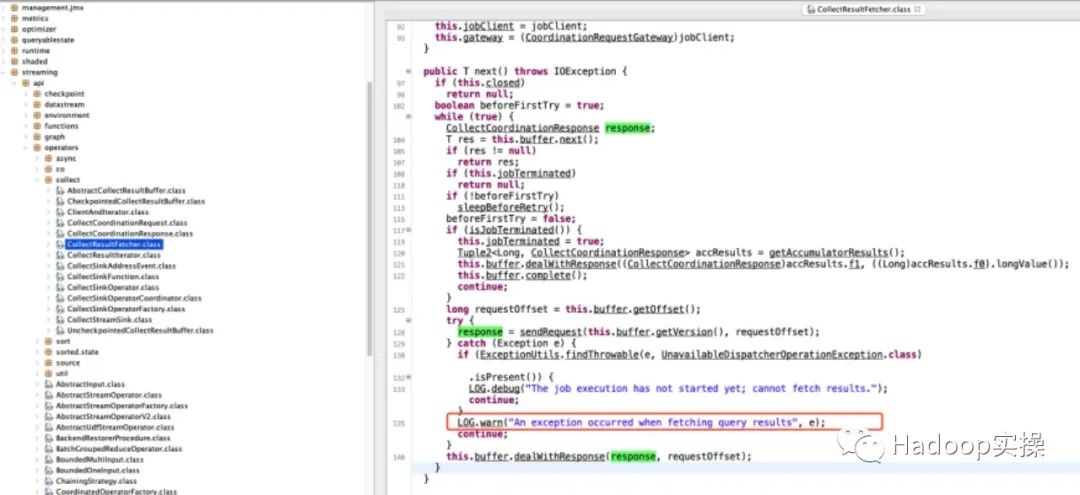
Видно, что часть получения результатов представляет собой цикл while, который непрерывно получает результаты от мастера заданий. Нет оценки состояния завершения работы JobMaster или ожидания ожидания. Цикл while приводит к тому, что мастер заданий не завершается полностью. , а затем появляется снова, что приводит к новому запросу.
Решение: В службе FLink CM установите уровень журнала на ОШИБКУ. Конкретная конфигурация выглядит следующим образом:
logger.flink-collect.name = org.apache.flink.streaming.api.operators.collect.CollectResultFetcher
logger.flink-collect.level = ERROR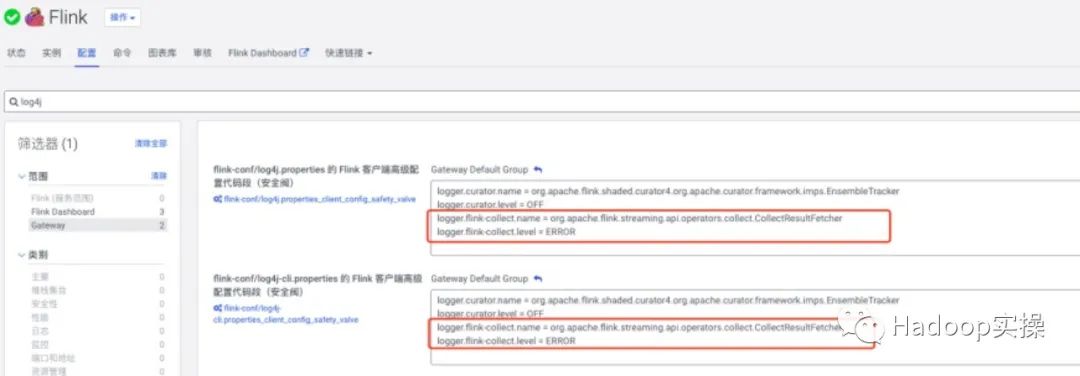
5 Резюме
1. Официально предоставленный пакет зависимостей flink-connector-hive не может быть интегрирован с Hive CDP. Для интеграции необходимо использовать flink-connector-hive_2.12-1.14.0-csa1.6.0.0.jar, предоставленный Cloudera.
2. Каталог Hive, созданный в Flink SQL Client, действителен в текущем сеансе и его необходимо создать заново после перезапуска сеанса.
3. Шлюз Hive On Tez должен быть развернут на узле шлюза FLink, иначе информация о конфигурации, связанная с Hive Metastore (например, URI Metastore и путь HDFS к хранилищу), не будет найдена при создании каталога.
4. После добавления зависимости antlr-runtime-3.5.2.jar диалект Hive нельзя использовать, установив 'table.sql-dialect' = 'hive'.
5. Если зависимость Hadoop-mapreduce-client-core.jar не добавлена, выполнение SQL в SQL-клиенте будет зависать.
6. Запуск заданий Flink под SQL-клиентом поддерживает только режим каждого задания и не поддерживает режим сеанса.
7. После вставки данных в таблицу через Flink SQL созданное задание Flink не может завершиться автоматически и всегда выполняется. Фактические данные были записаны в таблицу.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
